 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFootFormer: Estimating Stability from Visual Input
Oct 22, 2025We propose FootFormer, a cross-modality approach for jointly predicting human motion dynamics directly from visual input. On multiple datasets, FootFormer achieves statistically significantly better or equivalent estimates of foot pressure distributions, foot contact maps, and center of mass (CoM), as compared with existing methods that generate one or two of those measures. Furthermore, FootFormer achieves SOTA performance in estimating stability-predictive components (CoP, CoM, BoS) used in classic kinesiology metrics. Code and data are available at https://github.com/keatonkraiger/Vision-to-Stability.git.
MedReasoner: Reinforcement Learning Drives Reasoning Grounding from Clinical Thought to Pixel-Level Precision
Aug 11, 2025Accurately grounding regions of interest (ROIs) is critical for diagnosis and treatment planning in medical imaging. While multimodal large language models (MLLMs) combine visual perception with natural language, current medical-grounding pipelines still rely on supervised fine-tuning with explicit spatial hints, making them ill-equipped to handle the implicit queries common in clinical practice. This work makes three core contributions. We first define Unified Medical Reasoning Grounding (UMRG), a novel vision-language task that demands clinical reasoning and pixel-level grounding. Second, we release U-MRG-14K, a dataset of 14K samples featuring pixel-level masks alongside implicit clinical queries and reasoning traces, spanning 10 modalities, 15 super-categories, and 108 specific categories. Finally, we introduce MedReasoner, a modular framework that distinctly separates reasoning from segmentation: an MLLM reasoner is optimized with reinforcement learning, while a frozen segmentation expert converts spatial prompts into masks, with alignment achieved through format and accuracy rewards. MedReasoner achieves state-of-the-art performance on U-MRG-14K and demonstrates strong generalization to unseen clinical queries, underscoring the significant promise of reinforcement learning for interpretable medical grounding.
Recurrence-based Vanishing Point Detection
Dec 30, 2024Classical approaches to Vanishing Point Detection (VPD) rely solely on the presence of explicit straight lines in images, while recent supervised deep learning approaches need labeled datasets for training. We propose an alternative unsupervised approach: Recurrence-based Vanishing Point Detection (R-VPD) that uses implicit lines discovered from recurring correspondences in addition to explicit lines. Furthermore, we contribute two Recurring-Pattern-for-Vanishing-Point (RPVP) datasets: 1) a Synthetic Image dataset with 3,200 ground truth vanishing points and camera parameters, and 2) a Real-World Image dataset with 1,400 human annotated vanishing points. We compare our method with two classical methods and two state-of-the-art deep learning-based VPD methods. We demonstrate that our unsupervised approach outperforms all the methods on the synthetic images dataset, outperforms the classical methods, and is on par with the supervised learning approaches on real-world images.
EscherNet 101
Mar 07, 2023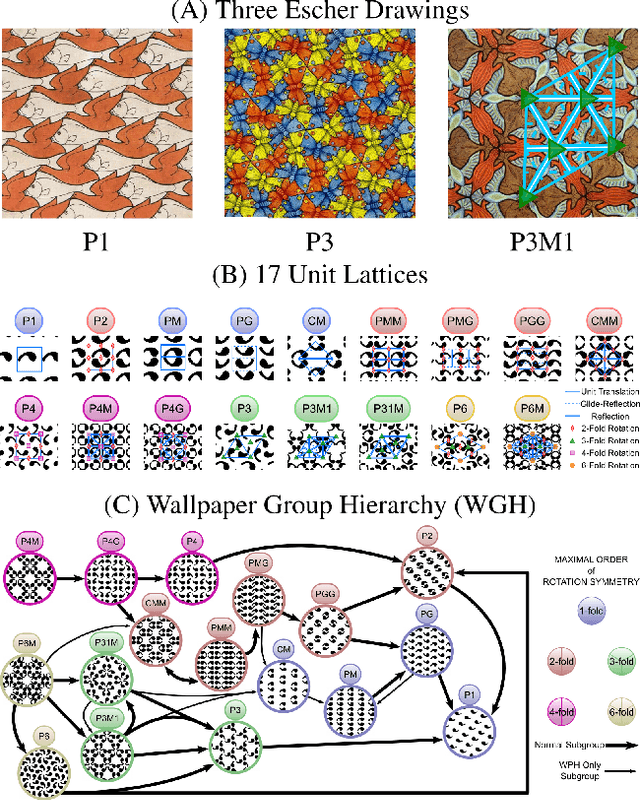
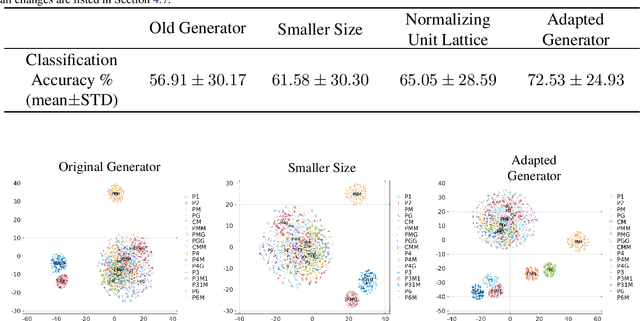
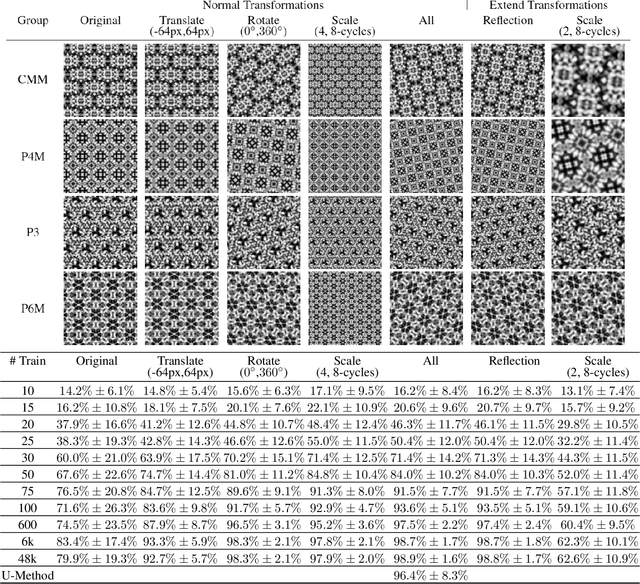
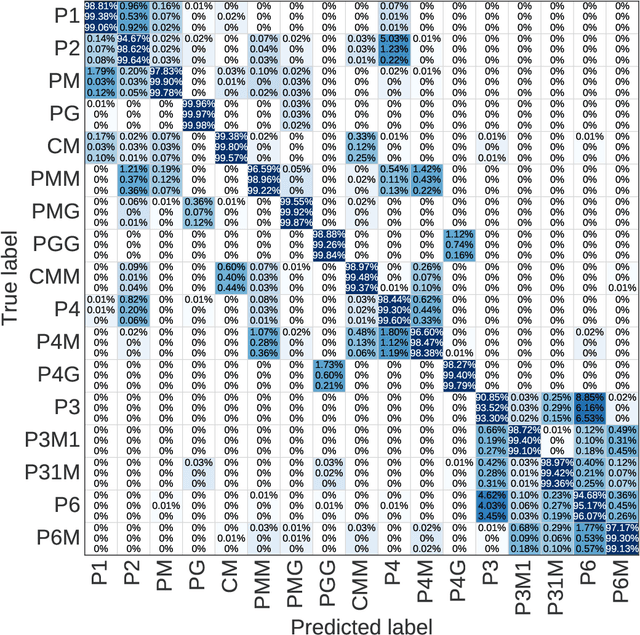
A deep learning model, EscherNet 101, is constructed to categorize images of 2D periodic patterns into their respective 17 wallpaper groups. Beyond evaluating EscherNet 101 performance by classification rates, at a micro-level we investigate the filters learned at different layers in the network, capable of capturing second-order invariants beyond edge and curvature.
Novel 3D Scene Understanding Applications From Recurrence in a Single Image
Oct 14, 2022


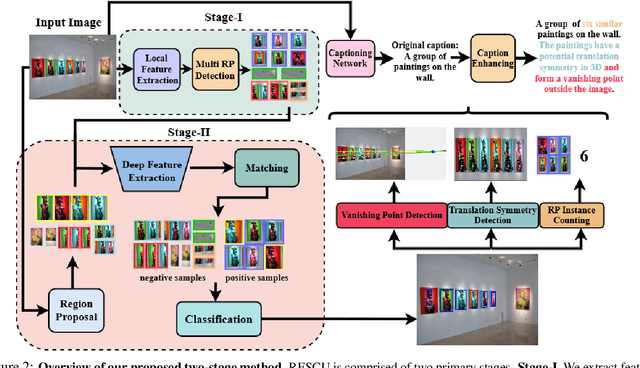
We demonstrate the utility of recurring pattern discovery from a single image for spatial understanding of a 3D scene in terms of (1) vanishing point detection, (2) hypothesizing 3D translation symmetry and (3) counting the number of RP instances in the image. Furthermore, we illustrate the feasibility of leveraging RP discovery output to form a more precise, quantitative text description of the scene. Our quantitative evaluations on a new 1K+ Recurring Pattern (RP) benchmark with diverse variations show that visual perception of recurrence from one single view leads to scene understanding outcomes that are as good as or better than existing supervised methods and/or unsupervised methods that use millions of images.
Image-based Stability Quantification
Jun 23, 2022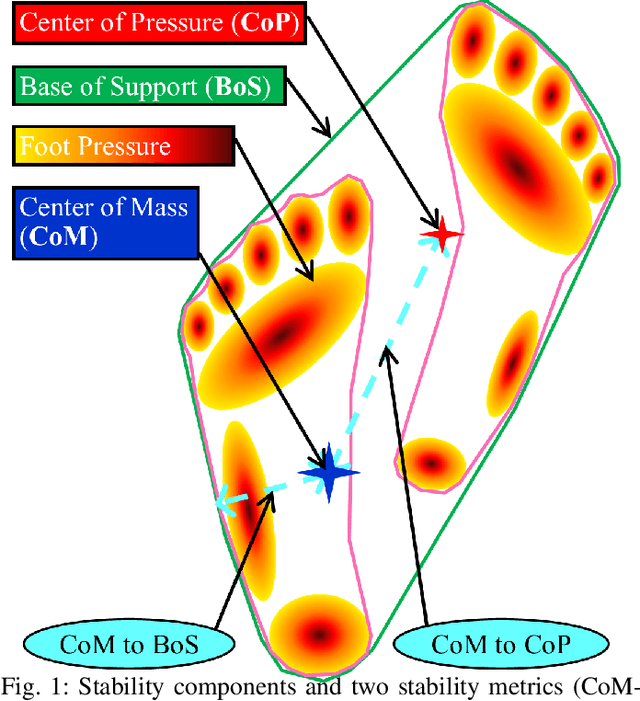
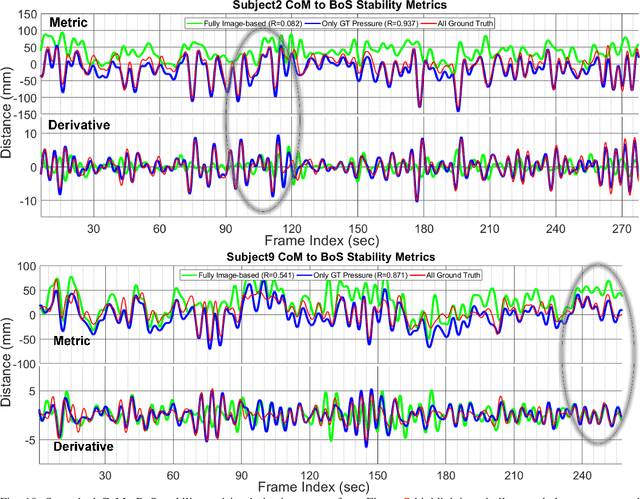
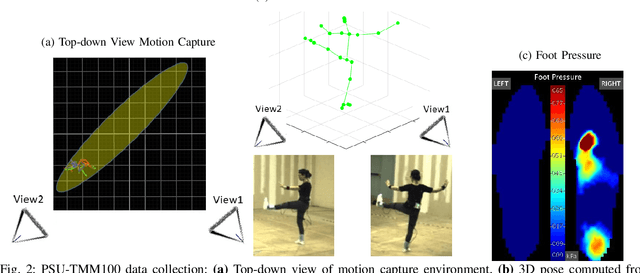
Quantitative evaluation of human stability using foot pressure/force measurement hardware and motion capture (mocap) technology is expensive, time consuming, and restricted to the laboratory (lab-based). We propose a novel image-based method to estimate three key components for stability computation: Center of Mass (CoM), Base of Support (BoS), and Center of Pressure (CoP). Furthermore, we quantitatively validate our image-based methods for computing two classic stability measures against the ones generated directly from lab-based sensory output (ground truth) using a publicly available multi-modality (mocap, foot pressure, 2-view videos), ten-subject human motion dataset. Using leave-one-subject-out cross validation, our experimental results show: 1) our CoM estimation method (CoMNet) consistently outperforms state-of-the-art inertial sensor-based CoM estimation techniques; 2) our image-based method combined with insole foot-pressure alone produces consistent and statistically significant correlation with ground truth stability measures (CoMtoCoP R=0.79 P<0.001, CoMtoBoS R=0.75 P<0.001); 3) our fully image-based stability metric estimation produces consistent, positive, and statistically significant correlation on the two stability metrics (CoMtoCoP R=0.31 P<0.001, CoMtoBoS R=0.22 P<0.001). Our study provides promising quantitative evidence for stability computations and monitoring in natural environments.
From Kinematics To Dynamics: Estimating Center of Pressure and Base of Support from Video Frames of Human Motion
Jan 02, 2020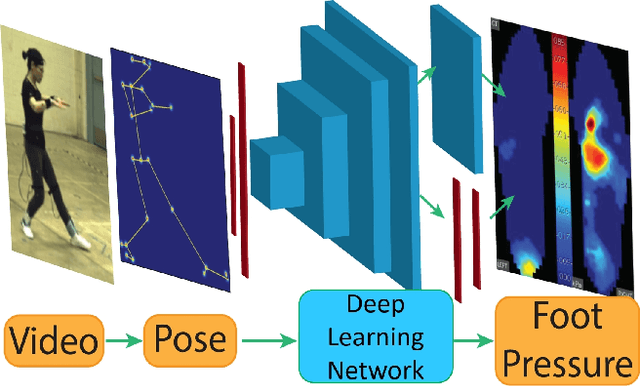
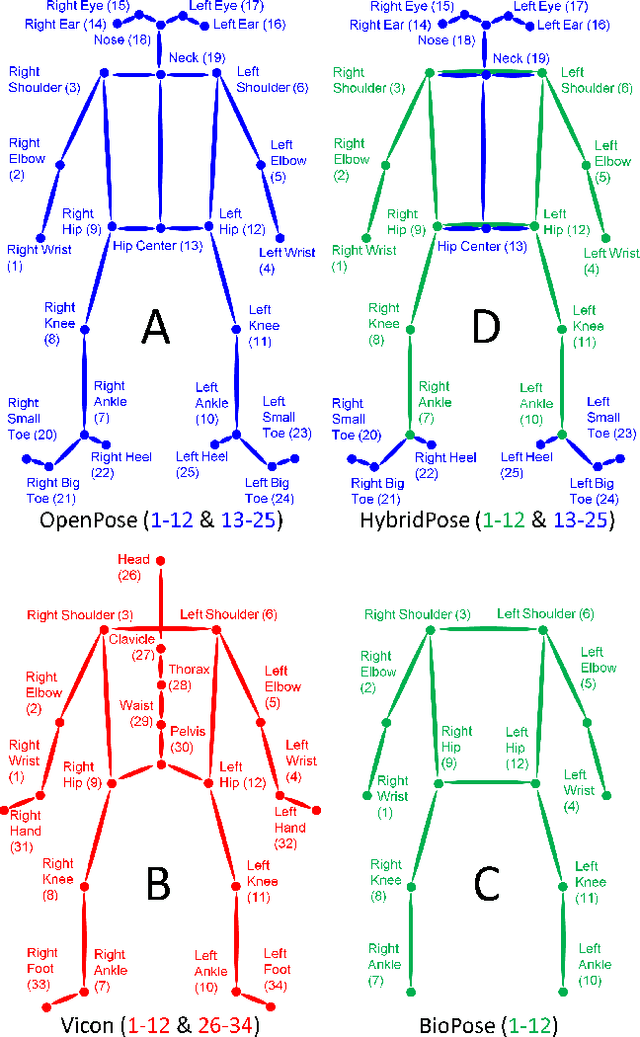
To gain an understanding of the relation between a given human pose image and the corresponding physical foot pressure of the human subject, we propose and validate two end-to-end deep learning architectures, PressNet and PressNet-Simple, to regress foot pressure heatmaps (dynamics) from 2D human pose (kinematics) derived from a video frame. A unique video and foot pressure data set of 813,050 synchronized pairs, composed of 5-minute long choreographed Taiji movement sequences of 6 subjects, is collected and used for leaving-one-subject-out cross validation. Our initial experimental results demonstrate reliable and repeatable foot pressure prediction from a single image, setting the first baseline for such a complex cross modality mapping problem in computer vision. Furthermore, we compute and quantitatively validate the Center of Pressure (CoP) and Base of Support (BoS) from predicted foot pressure distribution, obtaining key components in pose stability analysis from images with potential applications in kinesiology, medicine, sports and robotics.
Foot Pressure from Video: A Deep Learning Approach to Predict Dynamics from Kinematics
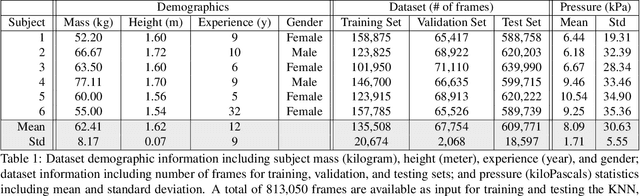
Nov 30, 2018
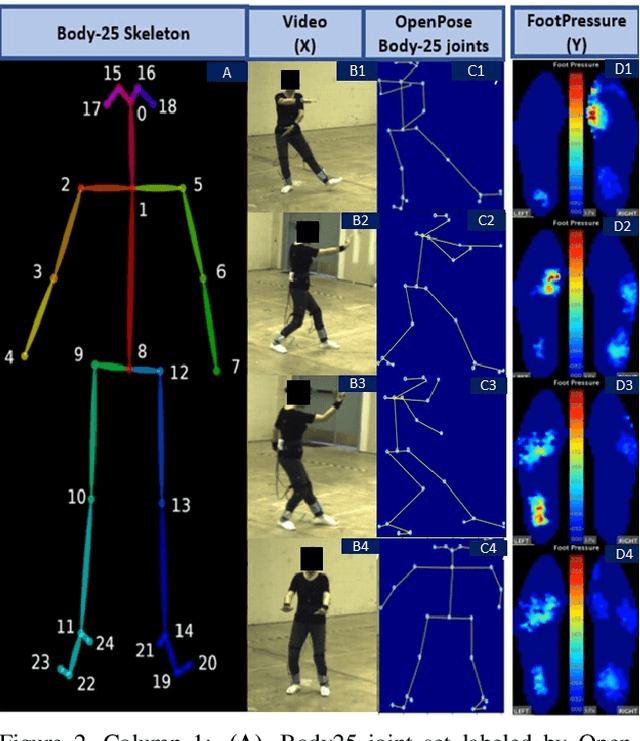
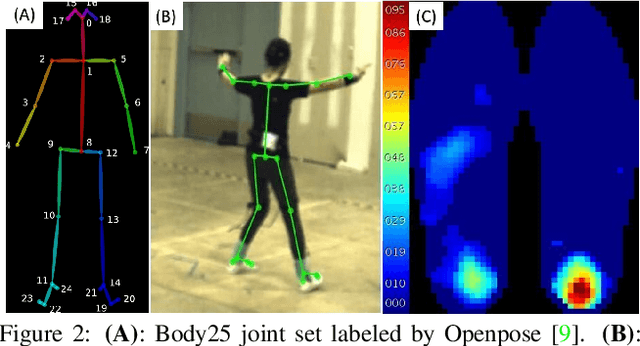
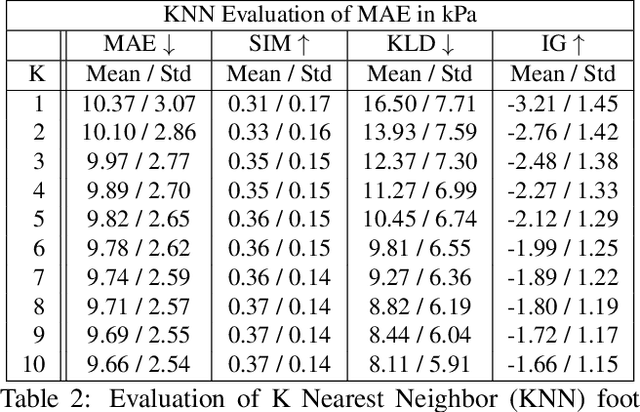
Human gait stability analysis is a key to understanding locomotion and control of body equilibrium, with numerous applications in the fields of Kinesiology, Medicine and Robotics. This work introduces a novel approach to learn dynamics of a human body from kinematics to aid stability analysis. We propose an end-to-end deep learning architecture to regress foot pressure from a human pose derived from video. This approach utilizes human Body-25 joints extracted from videos of subjects performing choreographed Taiji (Tai Chi) sequences using OpenPose estimation. The derived human pose data and corresponding foot pressure maps are used to train a convolutional neural network with residual architecture, termed PressNET, in an end-to-end fashion to predict the foot pressure corresponding to a given human pose. We create the largest dataset for simultaneous video and foot pressure on five subjects containing greater than 350k frames. We perform cross-subject evaluation with data from the five subjects on two versions of PressNET to evaluate the performance of our networks. KNearest Neighbors (KNN) is used to establish a baseline for comparisons and evaluation. We empirically show that PressNet significantly outperform KNN on all the splits.
Beyond Planar Symmetry: Modeling human perception of reflection and rotation symmetries in the wild
Aug 28, 2017
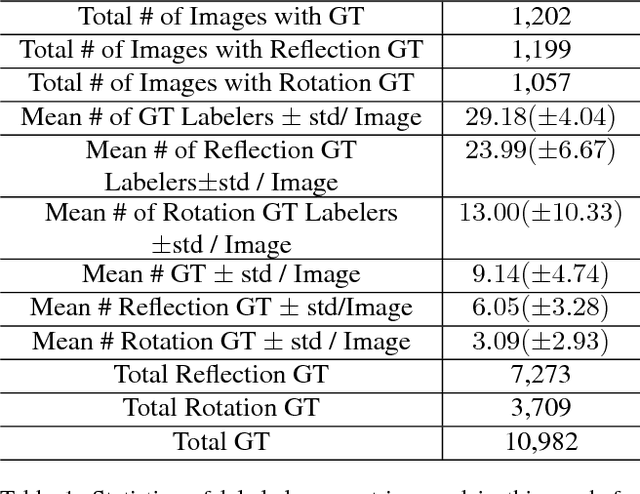
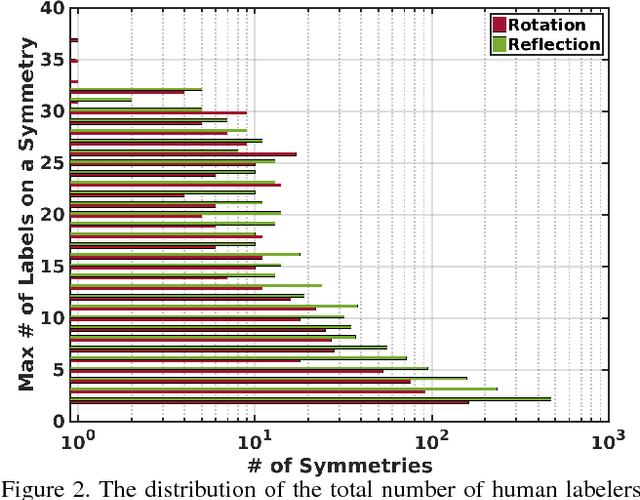

Humans take advantage of real world symmetries for various tasks, yet capturing their superb symmetry perception mechanism with a computational model remains elusive. Motivated by a new study demonstrating the extremely high inter-person accuracy of human perceived symmetries in the wild, we have constructed the first deep-learning neural network for reflection and rotation symmetry detection (Sym-NET), trained on photos from MS-COCO (Microsoft-Common Object in COntext) dataset with nearly 11K consistent symmetry-labels from more than 400 human observers. We employ novel methods to convert discrete human labels into symmetry heatmaps, capture symmetry densely in an image and quantitatively evaluate Sym-NET against multiple existing computer vision algorithms. On CVPR 2013 symmetry competition testsets and unseen MS-COCO photos, Sym-NET significantly outperforms all other competitors. Beyond mathematically well-defined symmetries on a plane, Sym-NET demonstrates abilities to identify viewpoint-varied 3D symmetries, partially occluded symmetrical objects, and symmetries at a semantic level.