 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFootFormer: Estimating Stability from Visual Input
Oct 22, 2025We propose FootFormer, a cross-modality approach for jointly predicting human motion dynamics directly from visual input. On multiple datasets, FootFormer achieves statistically significantly better or equivalent estimates of foot pressure distributions, foot contact maps, and center of mass (CoM), as compared with existing methods that generate one or two of those measures. Furthermore, FootFormer achieves SOTA performance in estimating stability-predictive components (CoP, CoM, BoS) used in classic kinesiology metrics. Code and data are available at https://github.com/keatonkraiger/Vision-to-Stability.git.
A Light-Weight Contrastive Approach for Aligning Human Pose Sequences
Mar 07, 2023

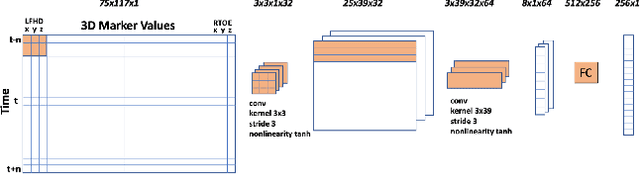

We present a simple unsupervised method for learning an encoder mapping short 3D pose sequences into embedding vectors suitable for sequence-to-sequence alignment by dynamic time warping. Training samples consist of temporal windows of frames containing 3D body points such as mocap markers or skeleton joints. A light-weight, 3-layer encoder is trained using a contrastive loss function that encourages embedding vectors of augmented sample pairs to have cosine similarity 1, and similarity 0 with all other samples in a minibatch. When multiple scripted training sequences are available, temporal alignments inferred from an initial round of training are harvested to extract additional, cross-performance match pairs for a second phase of training to refine the encoder. In addition to being simple, the proposed method is fast to train, making it easy to adapt to new data using different marker sets or skeletal joint layouts. Experimental results illustrate ease of use, transferability, and utility of the learned embeddings for comparing and analyzing human behavior sequences.
Image-based Stability Quantification
Jun 23, 2022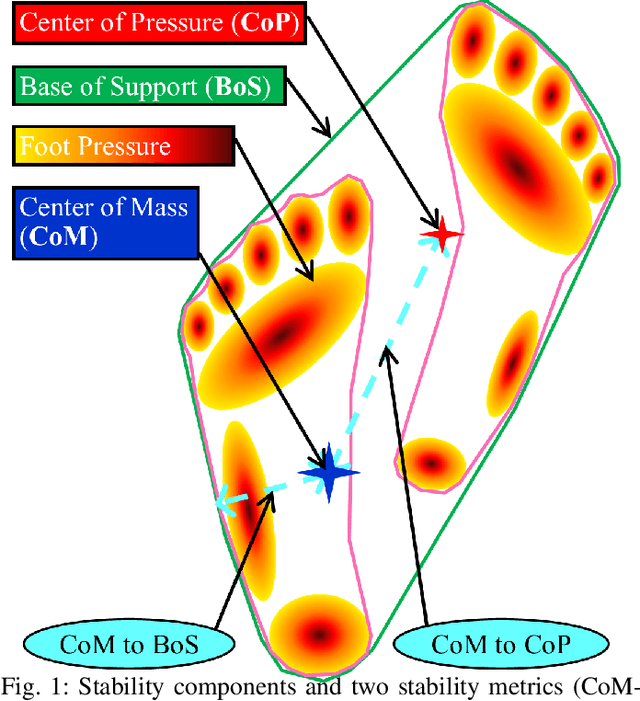
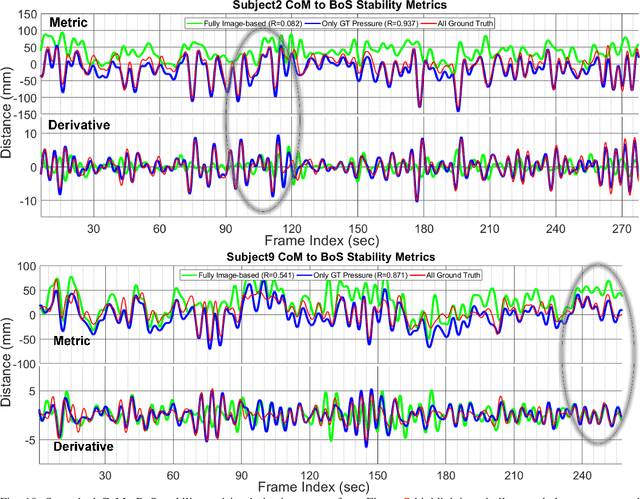
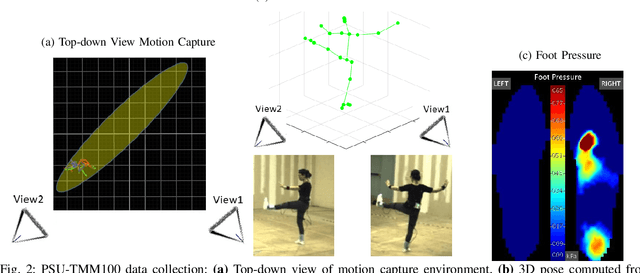
Quantitative evaluation of human stability using foot pressure/force measurement hardware and motion capture (mocap) technology is expensive, time consuming, and restricted to the laboratory (lab-based). We propose a novel image-based method to estimate three key components for stability computation: Center of Mass (CoM), Base of Support (BoS), and Center of Pressure (CoP). Furthermore, we quantitatively validate our image-based methods for computing two classic stability measures against the ones generated directly from lab-based sensory output (ground truth) using a publicly available multi-modality (mocap, foot pressure, 2-view videos), ten-subject human motion dataset. Using leave-one-subject-out cross validation, our experimental results show: 1) our CoM estimation method (CoMNet) consistently outperforms state-of-the-art inertial sensor-based CoM estimation techniques; 2) our image-based method combined with insole foot-pressure alone produces consistent and statistically significant correlation with ground truth stability measures (CoMtoCoP R=0.79 P<0.001, CoMtoBoS R=0.75 P<0.001); 3) our fully image-based stability metric estimation produces consistent, positive, and statistically significant correlation on the two stability metrics (CoMtoCoP R=0.31 P<0.001, CoMtoBoS R=0.22 P<0.001). Our study provides promising quantitative evidence for stability computations and monitoring in natural environments.
From Kinematics To Dynamics: Estimating Center of Pressure and Base of Support from Video Frames of Human Motion
Jan 02, 2020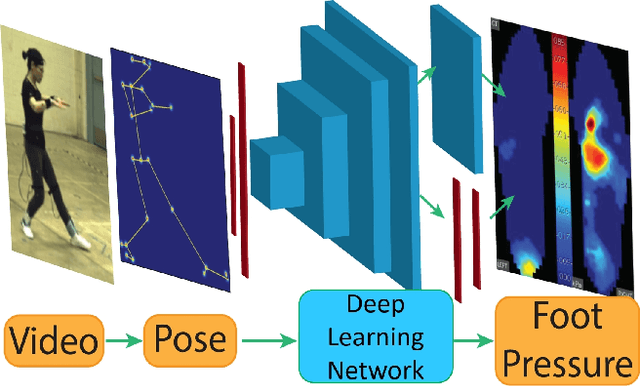
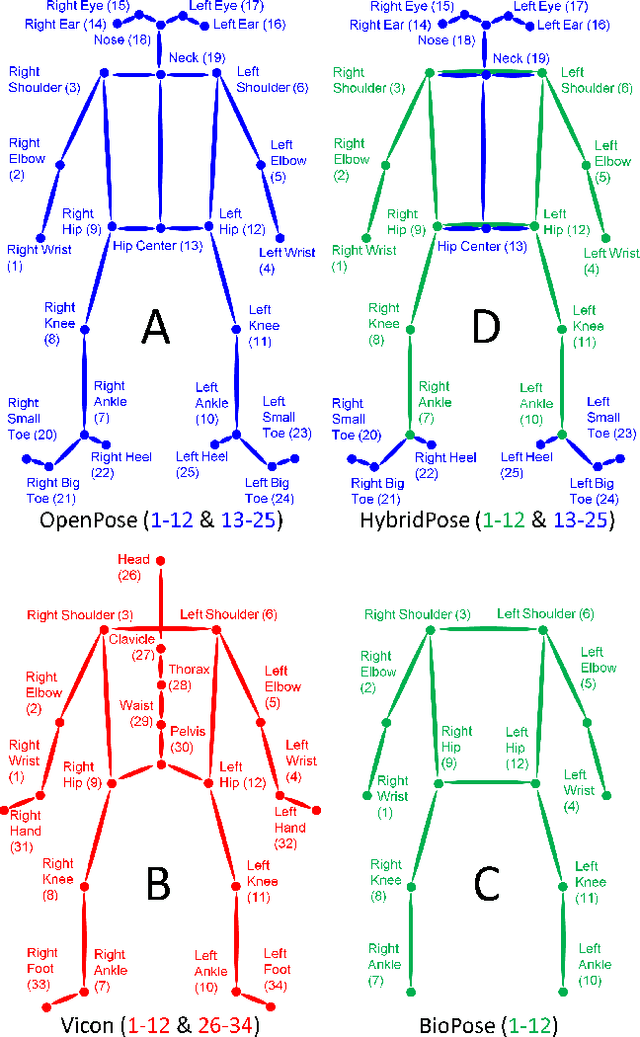
To gain an understanding of the relation between a given human pose image and the corresponding physical foot pressure of the human subject, we propose and validate two end-to-end deep learning architectures, PressNet and PressNet-Simple, to regress foot pressure heatmaps (dynamics) from 2D human pose (kinematics) derived from a video frame. A unique video and foot pressure data set of 813,050 synchronized pairs, composed of 5-minute long choreographed Taiji movement sequences of 6 subjects, is collected and used for leaving-one-subject-out cross validation. Our initial experimental results demonstrate reliable and repeatable foot pressure prediction from a single image, setting the first baseline for such a complex cross modality mapping problem in computer vision. Furthermore, we compute and quantitatively validate the Center of Pressure (CoP) and Base of Support (BoS) from predicted foot pressure distribution, obtaining key components in pose stability analysis from images with potential applications in kinesiology, medicine, sports and robotics.
Foot Pressure from Video: A Deep Learning Approach to Predict Dynamics from Kinematics
Nov 30, 2018
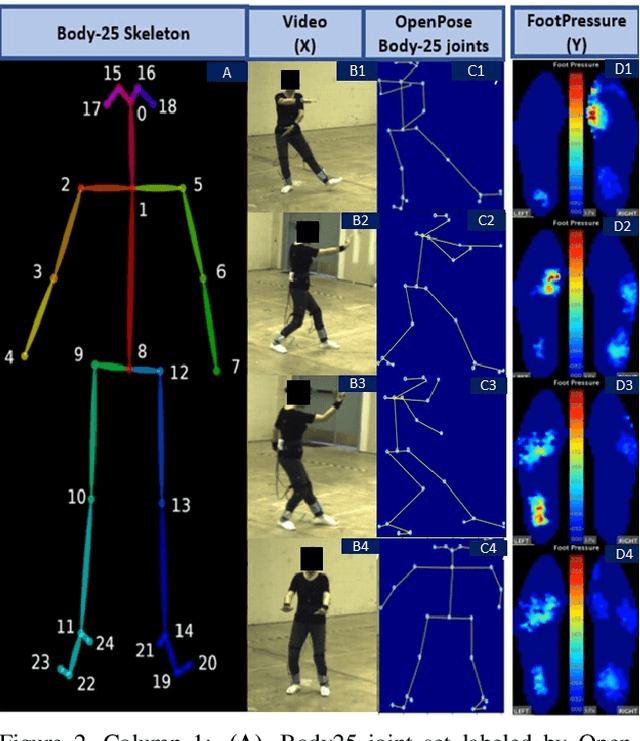
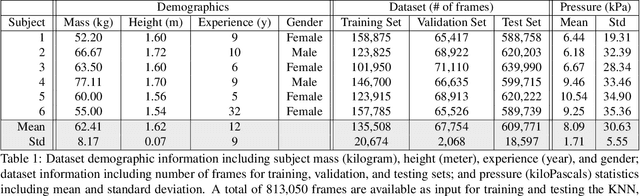
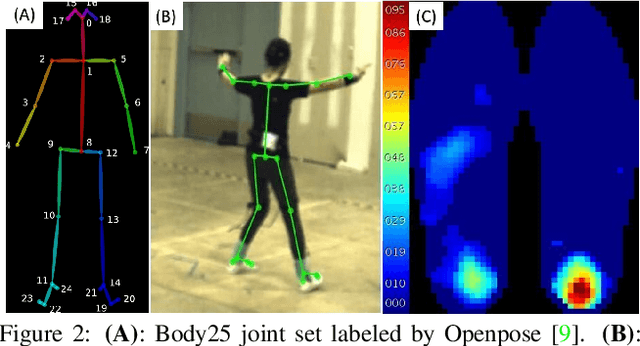
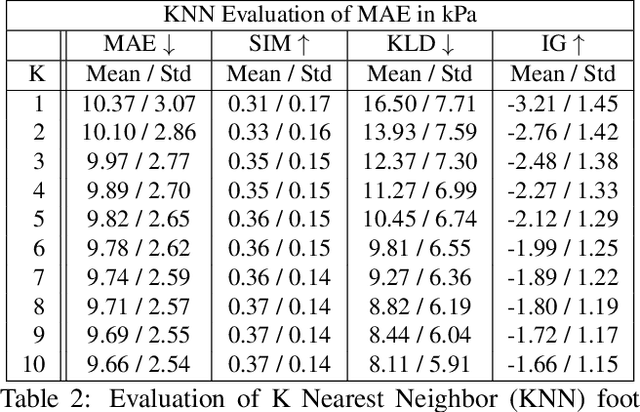
Human gait stability analysis is a key to understanding locomotion and control of body equilibrium, with numerous applications in the fields of Kinesiology, Medicine and Robotics. This work introduces a novel approach to learn dynamics of a human body from kinematics to aid stability analysis. We propose an end-to-end deep learning architecture to regress foot pressure from a human pose derived from video. This approach utilizes human Body-25 joints extracted from videos of subjects performing choreographed Taiji (Tai Chi) sequences using OpenPose estimation. The derived human pose data and corresponding foot pressure maps are used to train a convolutional neural network with residual architecture, termed PressNET, in an end-to-end fashion to predict the foot pressure corresponding to a given human pose. We create the largest dataset for simultaneous video and foot pressure on five subjects containing greater than 350k frames. We perform cross-subject evaluation with data from the five subjects on two versions of PressNET to evaluate the performance of our networks. KNearest Neighbors (KNN) is used to establish a baseline for comparisons and evaluation. We empirically show that PressNet significantly outperform KNN on all the splits.