 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition from the perspective of Activity Recognition
Paper and Code
Mar 24, 2024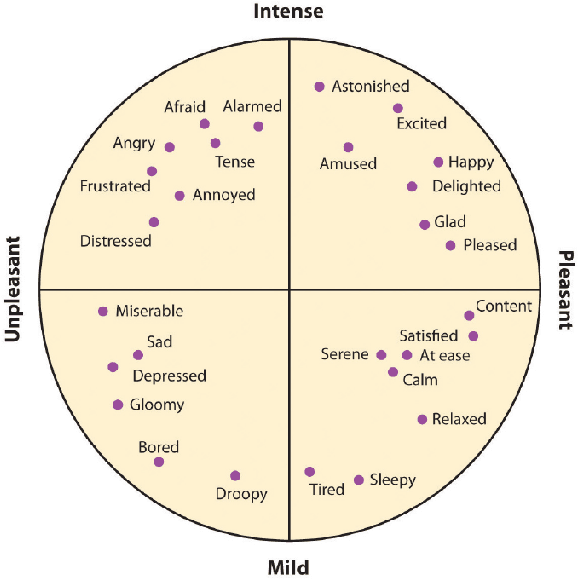
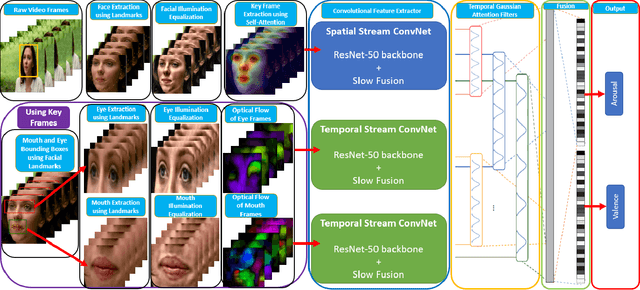
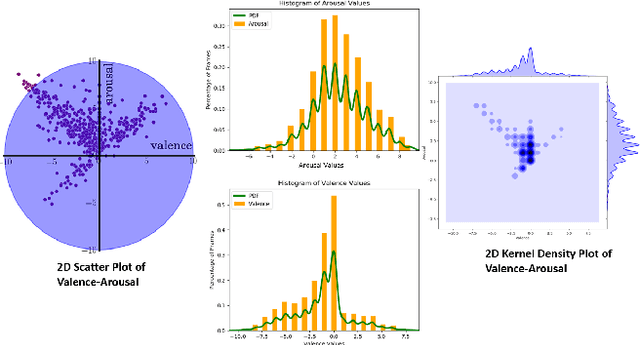
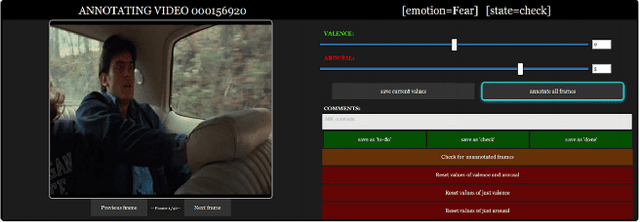
Applications of an efficient emotion recognition system can be found in several domains such as medicine, driver fatigue surveillance, social robotics, and human-computer interaction. Appraising human emotional states, behaviors, and reactions displayed in real-world settings can be accomplished using latent continuous dimensions. Continuous dimensional models of human affect, such as those based on valence and arousal are more accurate in describing a broad range of spontaneous everyday emotions than more traditional models of discrete stereotypical emotion categories (e.g. happiness, surprise). Most of the prior work on estimating valence and arousal considers laboratory settings and acted data. But, for emotion recognition systems to be deployed and integrated into real-world mobile and computing devices, we need to consider data collected in the world. Action recognition is a domain of Computer Vision that involves capturing complementary information on appearance from still frames and motion between frames. In this paper, we treat emotion recognition from the perspective of action recognition by exploring the application of deep learning architectures specifically designed for action recognition, for continuous affect recognition. We propose a novel three-stream end-to-end deep learning regression pipeline with an attention mechanism, which is an ensemble design based on sub-modules of multiple state-of-the-art action recognition systems. The pipeline constitutes a novel data pre-processing approach with a spatial self-attention mechanism to extract keyframes. The optical flow of high-attention regions of the face is extracted to capture temporal context. AFEW-VA in-the-wild dataset has been used to conduct comparative experiments. Quantitative analysis shows that the proposed model outperforms multiple standard baselines of both emotion recognition and action recognition models.