 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKCFRC: Kinematic Collision-Aware Foothold Reachability Criteria for Legged Locomotion
Feb 24, 2026Legged robots face significant challenges in navigating complex environments, as they require precise real-time decisions for foothold selection and contact planning. While existing research has explored methods to select footholds based on terrain geometry or kinematics, a critical gap remains: few existing methods efficiently validate the existence of a non-collision swing trajectory. This paper addresses this gap by introducing KCFRC, a novel approach for efficient foothold reachability analysis. We first formally define the foothold reachability problem and establish a sufficient condition for foothold reachability. Based on this condition, we develop the KCFRC algorithm, which enables robots to validate foothold reachability in real time. Our experimental results demonstrate that KCFRC achieves remarkable time efficiency, completing foothold reachability checks for a single leg across 900 potential footholds in an average of 2 ms. Furthermore, we show that KCFRC can accelerate trajectory optimization and is particularly beneficial for contact planning in confined spaces, enhancing the adaptability and robustness of legged robots in challenging environments.
Utilizing Earth Foundation Models to Enhance the Simulation Performance of Hydrological Models with AlphaEarth Embeddings
Jan 04, 2026Predicting river flow in places without streamflow records is challenging because basins respond differently to climate, terrain, vegetation, and soils. Traditional basin attributes describe some of these differences, but they cannot fully represent the complexity of natural environments. This study examines whether AlphaEarth Foundation embeddings, which are learned from large collections of satellite images rather than designed by experts, offer a more informative way to describe basin characteristics. These embeddings summarize patterns in vegetation, land surface properties, and long-term environmental dynamics. We find that models using them achieve higher accuracy when predicting flows in basins not used for training, suggesting that they capture key physical differences more effectively than traditional attributes. We further investigate how selecting appropriate donor basins influences prediction in ungauged regions. Similarity based on the embeddings helps identify basins with comparable environmental and hydrological behavior, improving performance, whereas adding many dissimilar basins can reduce accuracy. The results show that satellite-informed environmental representations can strengthen hydrological forecasting and support the development of models that adapt more easily to different landscapes.
PegasusFlow: Parallel Rolling-Denoising Score Sampling for Robot Diffusion Planner Flow Matching
Sep 10, 2025Diffusion models offer powerful generative capabilities for robot trajectory planning, yet their practical deployment on robots is hindered by a critical bottleneck: a reliance on imitation learning from expert demonstrations. This paradigm is often impractical for specialized robots where data is scarce and creates an inefficient, theoretically suboptimal training pipeline. To overcome this, we introduce PegasusFlow, a hierarchical rolling-denoising framework that enables direct and parallel sampling of trajectory score gradients from environmental interaction, completely bypassing the need for expert data. Our core innovation is a novel sampling algorithm, Weighted Basis Function Optimization (WBFO), which leverages spline basis representations to achieve superior sample efficiency and faster convergence compared to traditional methods like MPPI. The framework is embedded within a scalable, asynchronous parallel simulation architecture that supports massively parallel rollouts for efficient data collection. Extensive experiments on trajectory optimization and robotic navigation tasks demonstrate that our approach, particularly Action-Value WBFO (AVWBFO) combined with a reinforcement learning warm-start, significantly outperforms baselines. In a challenging barrier-crossing task, our method achieved a 100% success rate and was 18% faster than the next-best method, validating its effectiveness for complex terrain locomotion planning. https://masteryip.github.io/pegasusflow.github.io/
Enhancing Interaction Modeling with Agent Selection and Physical Methods for Trajectory Prediction
May 21, 2024



In this study, we address the limitations inherent in most existing vehicle trajectory prediction methodologies that indiscriminately incorporate all agents within a predetermined proximity when accounting for inter-agent interactions. These approaches commonly employ attention-based architecture or graph neural networks for encoding interactions, which introduces three challenges: (i) The indiscriminate selection of all nearby agents substantially escalates the computational demands of the model, particularly in those interaction-rich scenarios. (ii) Moreover, the simplistic feature extraction of current time agents falls short of adequately capturing the nuanced dynamics of interactions. (iii) Compounded by the inherently low interpretability of attention mechanism and graph neural networks, there is a propensity for the model to allocate unreliable correlation coefficients to certain agents, adversely impacting the accuracy of trajectory predictions. To mitigate these issues, we introduce ASPILin, a novel approach that enhances the selection of interacting agents by considering their current and future lanes, extending this consideration across all historical frames. Utilizing the states of the agents, we estimate the nearest future distance between agents and the time needed to reach this distance. Then, combine these with their current distances to derive a physical correlation coefficient to encode interactions. Experiments conducted on popular trajectory prediction datasets demonstrate that our method is efficient and straightforward, outperforming other state-of-the-art methods.
Continental-scale streamflow modeling of basins with reservoirs: a demonstration of effectiveness and a delineation of challenges
Jan 12, 2021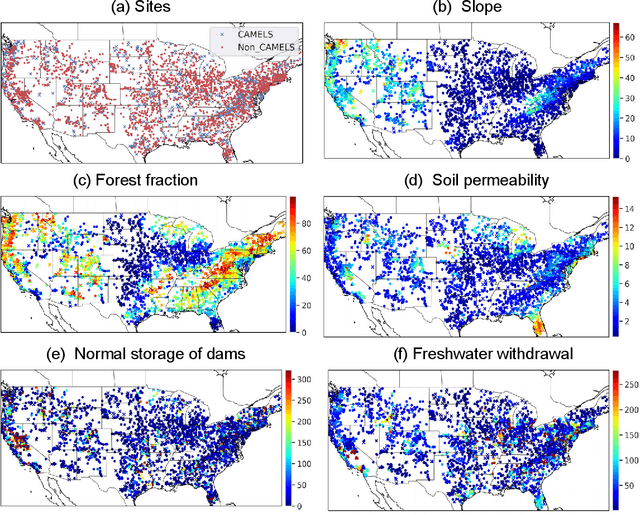


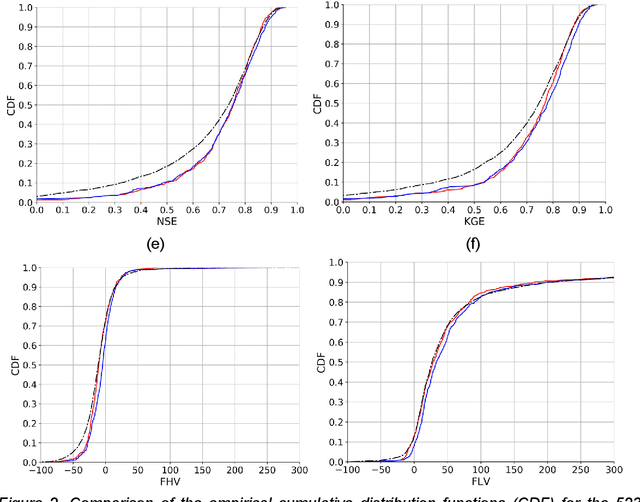
A large fraction of major waterways have dams influencing streamflow, which must be accounted for in large-scale hydrologic modeling. However, daily streamflow prediction for basins with dams is challenging for various modeling approaches, especially at large scales. Here we took a divide-and-conquer approach to examine which types of basins could be well represented by a long short-term memory (LSTM) deep learning model using only readily-available information. We analyzed data from 3557 basins (83% dammed) over the contiguous United States and noted strong impacts of reservoir purposes, capacity-to-runoff ratio (dor), and diversion on streamflow on streamflow modeling. Surprisingly, while the LSTM model trained on a widely-used reference-basin dataset performed poorly for more non-reference basins, the model trained on the whole dataset presented a median test Nash-Sutcliffe efficiency coefficient (NSE) of 0.74, reaching benchmark-level performance. The zero-dor, small-dor, and large-dor basins were found to have distinct behaviors, so migrating models between categories yielded catastrophic results. However, training with pooled data from different sets yielded optimal median NSEs of 0.73, 0.78, and 0.71 for these groups, respectively, showing noticeable advantages over existing models. These results support a coherent, mixed modeling strategy where smaller dams are modeled as part of rainfall-runoff processes, but dammed basins must not be treated as reference ones and must be included in the training set; then, large-dor reservoirs can be represented explicitly and future work should examine modeling reservoirs for fire protection and irrigation, followed by those for hydroelectric power generation, and flood control, etc.