 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTGAT: Multimodal Temporal Graph Attention Networks for Unaligned Human Multimodal Language Sequences
Oct 22, 2020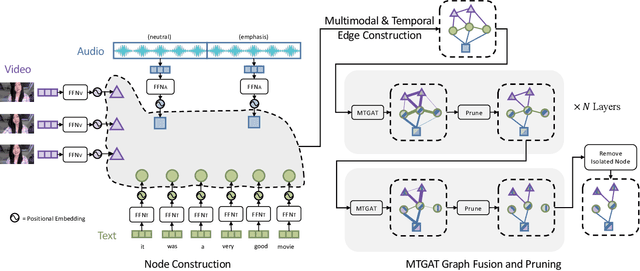
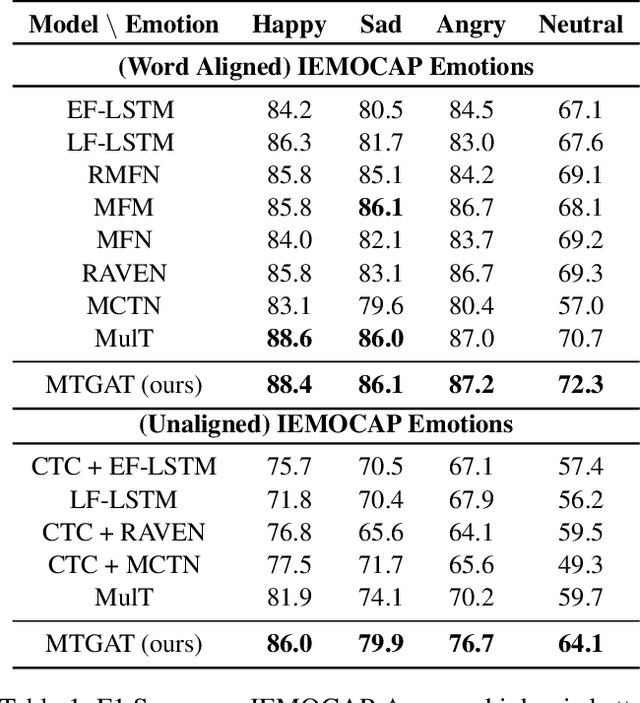
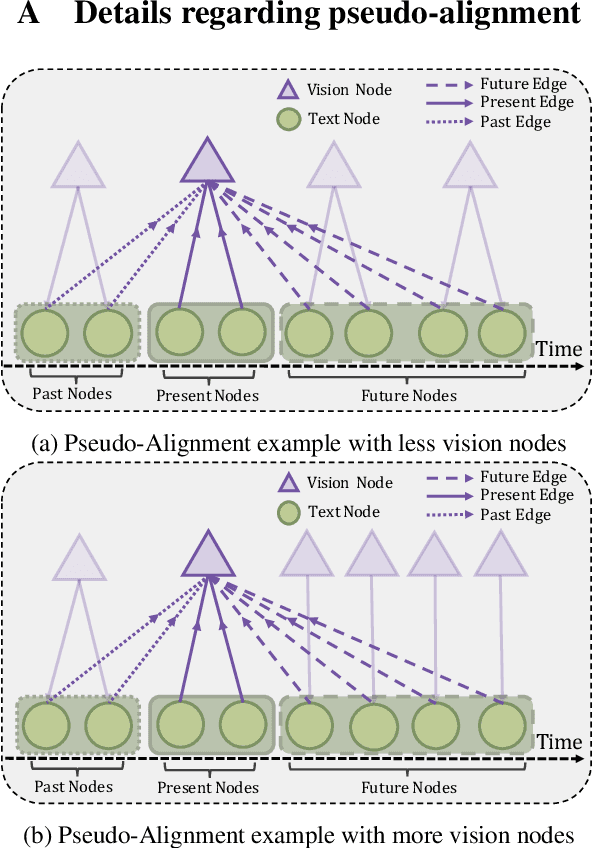
Human communication is multimodal in nature; it is through multiple modalities, i.e., language, voice, and facial expressions, that opinions and emotions are expressed. Data in this domain exhibits complex multi-relational and temporal interactions. Learning from this data is a fundamentally challenging research problem. In this paper, we propose Multimodal Temporal Graph Attention Networks (MTGAT). MTGAT is an interpretable graph-based neural model that provides a suitable framework for analyzing this type of multimodal sequential data. We first introduce a procedure to convert unaligned multimodal sequence data into a graph with heterogeneous nodes and edges that captures the rich interactions between different modalities through time. Then, a novel graph operation, called Multimodal Temporal Graph Attention, along with a dynamic pruning and read-out technique is designed to efficiently process this multimodal temporal graph. By learning to focus only on the important interactions within the graph, our MTGAT is able to achieve state-of-the-art performance on multimodal sentiment analysis and emotion recognition benchmarks including IEMOCAP and CMU-MOSI, while utilizing significantly fewer computations.
What Gives the Answer Away? Question Answering Bias Analysis on Video QA Datasets
Jul 07, 2020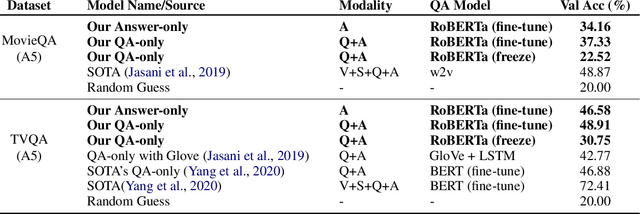
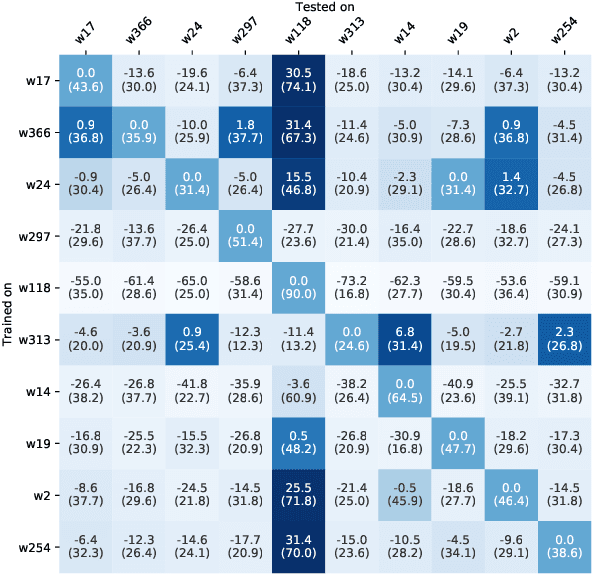

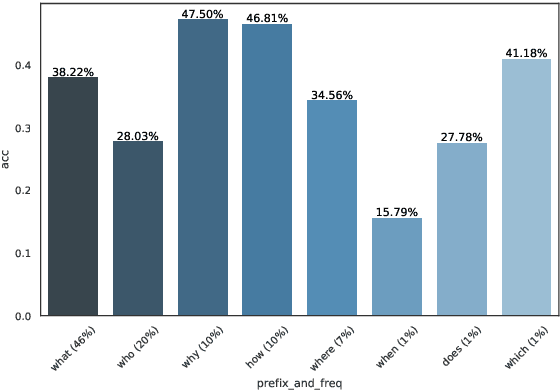
Question answering biases in video QA datasets can mislead multimodal model to overfit to QA artifacts and jeopardize the model's ability to generalize. Understanding how strong these QA biases are and where they come from helps the community measure progress more accurately and provide researchers insights to debug their models. In this paper, we analyze QA biases in popular video question answering datasets and discover pretrained language models can answer 37-48% questions correctly without using any multimodal context information, far exceeding the 20% random guess baseline for 5-choose-1 multiple-choice questions. Our ablation study shows biases can come from annotators and type of questions. Specifically, annotators that have been seen during training are better predicted by the model and reasoning, abstract questions incur more biases than factual, direct questions. We also show empirically that using annotator-non-overlapping train-test splits can reduce QA biases for video QA datasets.