 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Gives the Answer Away? Question Answering Bias Analysis on Video QA Datasets
Paper and Code
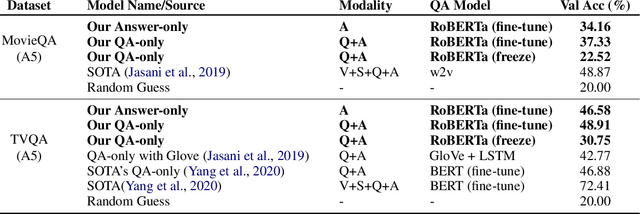
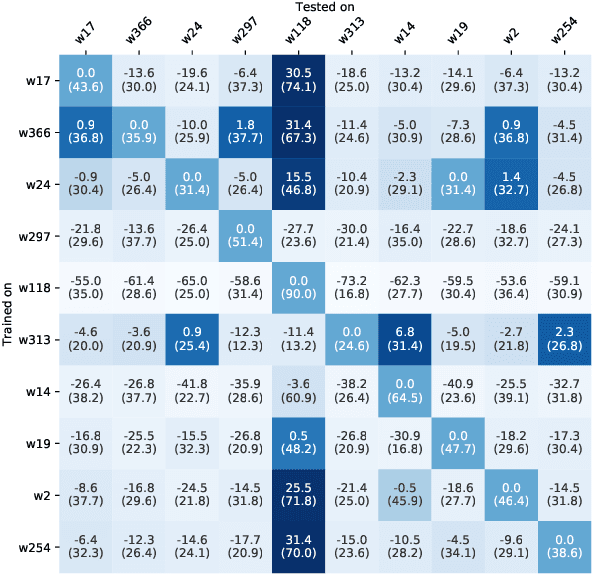

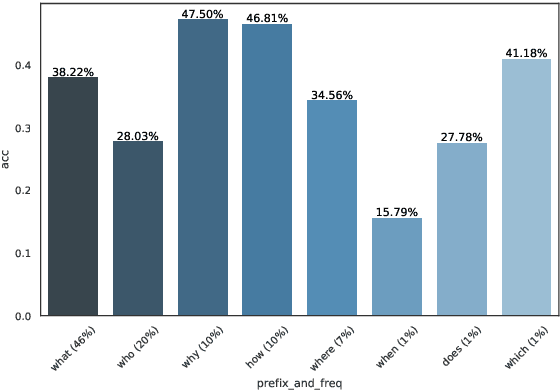
Question answering biases in video QA datasets can mislead multimodal model to overfit to QA artifacts and jeopardize the model's ability to generalize. Understanding how strong these QA biases are and where they come from helps the community measure progress more accurately and provide researchers insights to debug their models. In this paper, we analyze QA biases in popular video question answering datasets and discover pretrained language models can answer 37-48% questions correctly without using any multimodal context information, far exceeding the 20% random guess baseline for 5-choose-1 multiple-choice questions. Our ablation study shows biases can come from annotators and type of questions. Specifically, annotators that have been seen during training are better predicted by the model and reasoning, abstract questions incur more biases than factual, direct questions. We also show empirically that using annotator-non-overlapping train-test splits can reduce QA biases for video QA datasets.