 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Human-Centric Visual Cues for Human-Object Interaction Detection via Large Vision-Language Models
Nov 26, 2023Human-object interaction (HOI) detection aims at detecting human-object pairs and predicting their interactions. However, the complexity of human behavior and the diverse contexts in which these interactions occur make it challenging. Intuitively, human-centric visual cues, such as the involved participants, the body language, and the surrounding environment, play crucial roles in shaping these interactions. These cues are particularly vital in interpreting unseen interactions. In this paper, we propose three prompts with VLM to generate human-centric visual cues within an image from multiple perspectives of humans. To capitalize on these rich Human-Centric Visual Cues, we propose a novel approach named HCVC for HOI detection. Particularly, we develop a transformer-based multimodal fusion module with multitower architecture to integrate visual cue features into the instance and interaction decoders. Our extensive experiments and analysis validate the efficacy of leveraging the generated human-centric visual cues for HOI detection. Notably, the experimental results indicate the superiority of the proposed model over the existing state-of-the-art methods on two widely used datasets.
Federated Class-Incremental Learning with Prompting
Oct 13, 2023As Web technology continues to develop, it has become increasingly common to use data stored on different clients. At the same time, federated learning has received widespread attention due to its ability to protect data privacy when let models learn from data which is distributed across various clients. However, most existing works assume that the client's data are fixed. In real-world scenarios, such an assumption is most likely not true as data may be continuously generated and new classes may also appear. To this end, we focus on the practical and challenging federated class-incremental learning (FCIL) problem. For FCIL, the local and global models may suffer from catastrophic forgetting on old classes caused by the arrival of new classes and the data distributions of clients are non-independent and identically distributed (non-iid). In this paper, we propose a novel method called Federated Class-Incremental Learning with PrompTing (FCILPT). Given the privacy and limited memory, FCILPT does not use a rehearsal-based buffer to keep exemplars of old data. We choose to use prompts to ease the catastrophic forgetting of the old classes. Specifically, we encode the task-relevant and task-irrelevant knowledge into prompts, preserving the old and new knowledge of the local clients and solving the problem of catastrophic forgetting. We first sort the task information in the prompt pool in the local clients to align the task information on different clients before global aggregation. It ensures that the same task's knowledge are fully integrated, solving the problem of non-iid caused by the lack of classes among different clients in the same incremental task. Experiments on CIFAR-100, Mini-ImageNet, and Tiny-ImageNet demonstrate that FCILPT achieves significant accuracy improvements over the state-of-the-art methods.
Prototype-Based Layered Federated Cross-Modal Hashing
Oct 27, 2022

Recently, deep cross-modal hashing has gained increasing attention. However, in many practical cases, data are distributed and cannot be collected due to privacy concerns, which greatly reduces the cross-modal hashing performance on each client. And due to the problems of statistical heterogeneity, model heterogeneity, and forcing each client to accept the same parameters, applying federated learning to cross-modal hash learning becomes very tricky. In this paper, we propose a novel method called prototype-based layered federated cross-modal hashing. Specifically, the prototype is introduced to learn the similarity between instances and classes on server, reducing the impact of statistical heterogeneity (non-IID) on different clients. And we monitor the distance between local and global prototypes to further improve the performance. To realize personalized federated learning, a hypernetwork is deployed on server to dynamically update different layers' weights of local model. Experimental results on benchmark datasets show that our method outperforms state-of-the-art methods.
Three-Stream Joint Network for Zero-Shot Sketch-Based Image Retrieval
Apr 12, 2022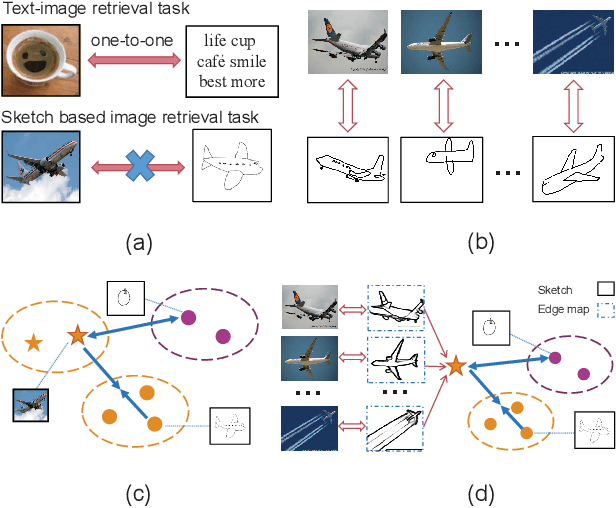
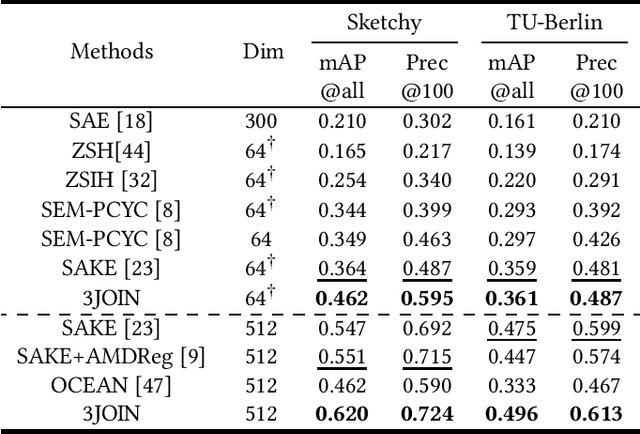
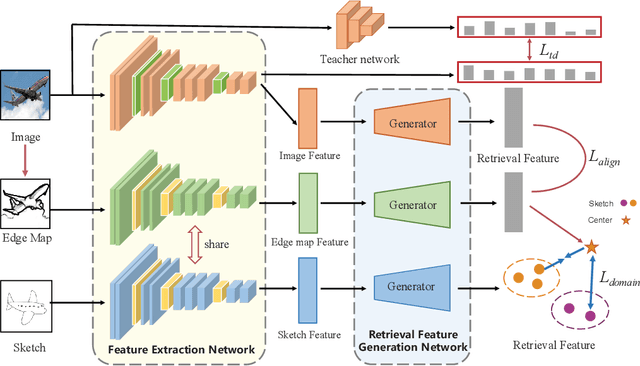
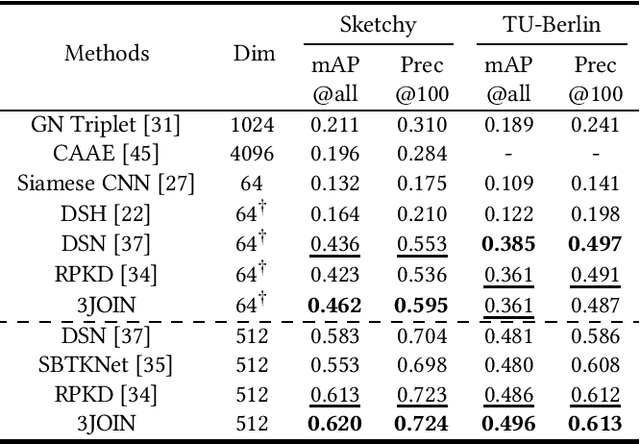
The Zero-Shot Sketch-based Image Retrieval (ZS-SBIR) is a challenging task because of the large domain gap between sketches and natural images as well as the semantic inconsistency between seen and unseen categories. Previous literature bridges seen and unseen categories by semantic embedding, which requires prior knowledge of the exact class names and additional extraction efforts. And most works reduce domain gap by mapping sketches and natural images into a common high-level space using constructed sketch-image pairs, which ignore the unpaired information between images and sketches. To address these issues, in this paper, we propose a novel Three-Stream Joint Training Network (3JOIN) for the ZS-SBIR task. To narrow the domain differences between sketches and images, we extract edge maps for natural images and treat them as a bridge between images and sketches, which have similar content to images and similar style to sketches. For exploiting a sufficient combination of sketches, natural images, and edge maps, a novel three-stream joint training network is proposed. In addition, we use a teacher network to extract the implicit semantics of the samples without the aid of other semantics and transfer the learned knowledge to unseen classes. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed method.
Online Enhanced Semantic Hashing: Towards Effective and Efficient Retrieval for Streaming Multi-Modal Data
Sep 09, 2021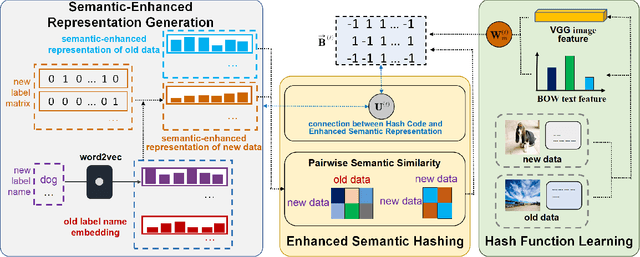
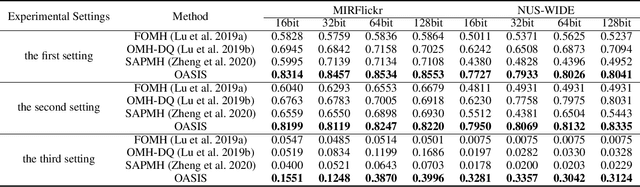
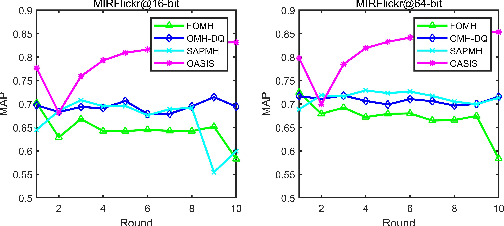

With the vigorous development of multimedia equipment and applications, efficient retrieval of large-scale multi-modal data has become a trendy research topic. Thereinto, hashing has become a prevalent choice due to its retrieval efficiency and low storage cost. Although multi-modal hashing has drawn lots of attention in recent years, there still remain some problems. The first point is that existing methods are mainly designed in batch mode and not able to efficiently handle streaming multi-modal data. The second point is that all existing online multi-modal hashing methods fail to effectively handle unseen new classes which come continuously with streaming data chunks. In this paper, we propose a new model, termed Online enhAnced SemantIc haShing (OASIS). We design novel semantic-enhanced representation for data, which could help handle the new coming classes, and thereby construct the enhanced semantic objective function. An efficient and effective discrete online optimization algorithm is further proposed for OASIS. Extensive experiments show that our method can exceed the state-of-the-art models. For good reproducibility and benefiting the community, our code and data are already available in supplementary material and will be made publicly available.
Weakly-Supervised Online Hashing
Sep 16, 2020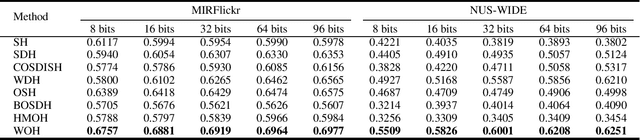


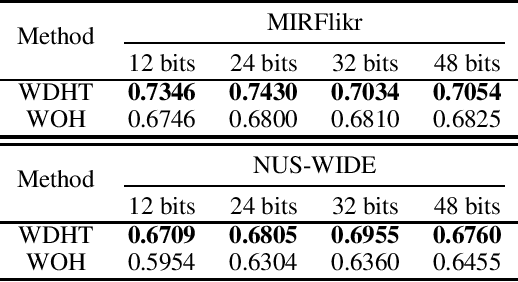
With the rapid development of social websites, recent years have witnessed an explosive growth of social images with user-provided tags which continuously arrive in a streaming fashion. Due to the fast query speed and low storage cost, hashing-based methods for image search have attracted increasing attention. However, existing hashing methods for social image retrieval are based on batch mode which violates the nature of social images, i.e., social images are usually generated periodically or collected in a stream fashion. Although there exist many online image hashing methods, they either adopt unsupervised learning which ignore the relevant tags, or are designed in the supervised manner which needs high-quality labels. In this paper, to overcome the above limitations, we propose a new method named Weakly-supervised Online Hashing (WOH). In order to learn high-quality hash codes, WOH exploits the weak supervision by considering the semantics of tags and removing the noise. Besides, We develop a discrete online optimization algorithm for WOH, which is efficient and scalable. Extensive experiments conducted on two real-world datasets demonstrate the superiority of WOH compared with several state-of-the-art hashing baselines.