 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVC-MF: End-to-end Video Captioning Network with Multi-scale Features
Oct 22, 2024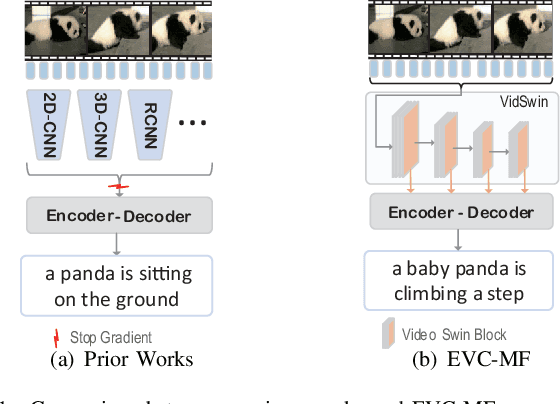



Conventional approaches for video captioning leverage a variety of offline-extracted features to generate captions. Despite the availability of various offline-feature-extractors that offer diverse information from different perspectives, they have several limitations due to fixed parameters. Concretely, these extractors are solely pre-trained on image/video comprehension tasks, making them less adaptable to video caption datasets. Additionally, most of these extractors only capture features prior to the classifier of the pre-training task, ignoring a significant amount of valuable shallow information. Furthermore, employing multiple offline-features may introduce redundant information. To address these issues, we propose an end-to-end encoder-decoder-based network (EVC-MF) for video captioning, which efficiently utilizes multi-scale visual and textual features to generate video descriptions. Specifically, EVC-MF consists of three modules. Firstly, instead of relying on multiple feature extractors, we directly feed video frames into a transformer-based network to obtain multi-scale visual features and update feature extractor parameters. Secondly, we fuse the multi-scale features and input them into a masked encoder to reduce redundancy and encourage learning useful features. Finally, we utilize an enhanced transformer-based decoder, which can efficiently leverage shallow textual information, to generate video descriptions. To evaluate our proposed model, we conduct extensive experiments on benchmark datasets. The results demonstrate that EVC-MF yields competitive performance compared with the state-of-theart methods.