 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Redundancy-Free Sub-networks in Continual Learning
Dec 01, 2023Catastrophic Forgetting (CF) is a prominent issue in continual learning. Parameter isolation addresses this challenge by masking a sub-network for each task to mitigate interference with old tasks. However, these sub-networks are constructed relying on weight magnitude, which does not necessarily correspond to the importance of weights, resulting in maintaining unimportant weights and constructing redundant sub-networks. To overcome this limitation, inspired by information bottleneck, which removes redundancy between adjacent network layers, we propose \textbf{\underline{I}nformation \underline{B}ottleneck \underline{M}asked sub-network (IBM)} to eliminate redundancy within sub-networks. Specifically, IBM accumulates valuable information into essential weights to construct redundancy-free sub-networks, not only effectively mitigating CF by freezing the sub-networks but also facilitating new tasks training through the transfer of valuable knowledge. Additionally, IBM decomposes hidden representations to automate the construction process and make it flexible. Extensive experiments demonstrate that IBM consistently outperforms state-of-the-art methods. Notably, IBM surpasses the state-of-the-art parameter isolation method with a 70\% reduction in the number of parameters within sub-networks and an 80\% decrease in training time.
Boosting Adversarial Attacks by Leveraging Decision Boundary Information
Mar 10, 2023
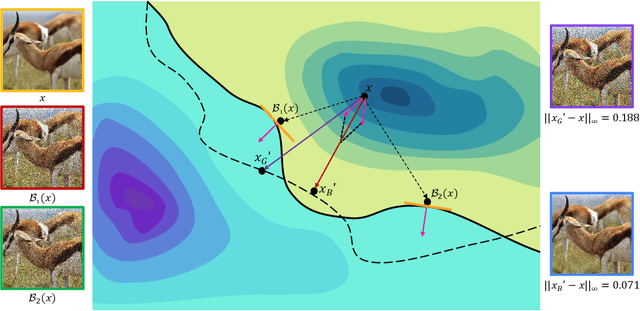
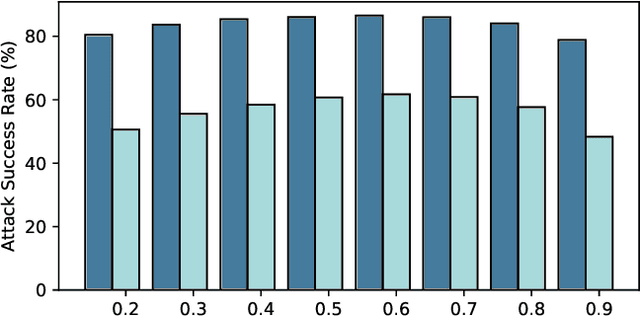
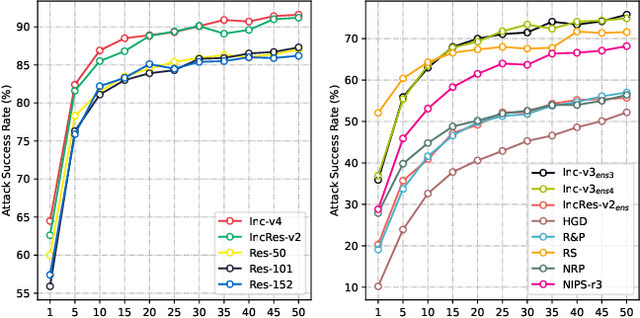
Due to the gap between a substitute model and a victim model, the gradient-based noise generated from a substitute model may have low transferability for a victim model since their gradients are different. Inspired by the fact that the decision boundaries of different models do not differ much, we conduct experiments and discover that the gradients of different models are more similar on the decision boundary than in the original position. Moreover, since the decision boundary in the vicinity of an input image is flat along most directions, we conjecture that the boundary gradients can help find an effective direction to cross the decision boundary of the victim models. Based on it, we propose a Boundary Fitting Attack to improve transferability. Specifically, we introduce a method to obtain a set of boundary points and leverage the gradient information of these points to update the adversarial examples. Notably, our method can be combined with existing gradient-based methods. Extensive experiments prove the effectiveness of our method, i.e., improving the success rate by 5.6% against normally trained CNNs and 14.9% against defense CNNs on average compared to state-of-the-art transfer-based attacks. Further we compare transformers with CNNs, the results indicate that transformers are more robust than CNNs. However, our method still outperforms existing methods when attacking transformers. Specifically, when using CNNs as substitute models, our method obtains an average attack success rate of 58.2%, which is 10.8% higher than other state-of-the-art transfer-based attacks.