 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Object-Centric Video Understanding for Generating Robotic Manipulation Commands
Jun 15, 2026Translating video demonstrations into executable robot commands remains challenging because existing methods often fail to identify which objects are functionally involved in the demonstrated action. As a result, they may generate commands that are linguistically plausible but operationally ambiguous. We propose an object-centric video understanding framework that decouples action recognition from object identification to generate precise, grammar-free manipulation commands. Our approach integrates Temporal Shift Modules (TSM) for efficient spatio-temporal action classification with a novel \textbf{Object Selection} algorithm that identifies task-relevant objects through trajectory-based role classification, blur detection, and overlap minimization. The selected objects are then processed by Vision-Language Models (VLMs) for robust category recognition and zero-shot generalization. Evaluated on a modified Something-Something V2 dataset, our method achieves 86.79\% action classification accuracy and BLEU-4 scores of 0.337 on standard objects and 0.261 on novel objects. These results improve over the strongest task-specific baseline by 80.2\% and 143.9\%, respectively. Larger gains are observed in METEOR and CIDEr, reaching 157.9\% and 171.7\% on novel objects. Across all semantic metrics, our approach consistently outperforms task-specific methods and remains competitive with, or surpasses, large general-purpose VLMs while retaining a modular, object-centric design.
WaveSync: Constrained Wavefront Optimization for Synchronized Co-Speech Gestures in Humanoid Robots
Jun 15, 2026Expressive co-speech gestures are crucial for natural human-robot interaction, but generating them on physical humanoid robots is difficult because gesture strokes must align with speech emphasis while satisfying strict kinematic and dynamic constraints. Unlike virtual avatars, humanoid robots cannot freely execute rapid or overlapping motions, making word-level synchronization and hardware-safe motion planning a coupled problem. We present \textbf{WaveSync}, a hybrid framework in which a Large Language Model decomposes dialogue responses into structured semantic schemas and assigns per-word importance weights, constructing a continuous Semantic Importance Wave. Gesture trajectories are shaped through Dynamic Movement Primitives, enforcing kinematic feasibility while enhancing expressiveness. A Wavefront Optimization stage aligns peak-to-peak gesture-speech synchronization and resolves residual kinematic violations through gesture-duration compression and forward propagation. Experimental evaluation based on five dialogue scenarios shows that our method achieves high synchronization accuracy and outperforms three baselines in both objective and subjective evaluations. Each component in WaveSync plays a necessary role in producing gestures that are expressive, semantically grounded, and kinematically compliant. The code, resources, and videos are available at \href{https://github.com/pairs-lab/WaveSync}{WaveSync}
OSDAG: Online Scheduling for Efficient Multi-Robot Collaboration
Jun 13, 2026Coordinating heterogeneous multi-robot systems (MRS) for complex, long-horizon tasks requires both flexible high-level reasoning and efficient low-level scheduling. Existing LLM-based approaches address the reasoning side but introduce two critical bottlenecks: (1) repeated LLM inference during execution, which inflates latency with agent count, and (2) offline, pre-committed scheduling, which forces robots to idle while waiting for sequentially ordered predecessors even when independent work is available. This paper presents OSDAG, a novel framework that integrates LLM-based task reasoning with Directed Acyclic Graph (DAG) representation and constraint-aware online scheduling. The LLM is invoked once to decompose a natural-language instruction into a dependency-annotated task graph, and a lightweight online scheduler then allocates ready tasks to idle agents in real time. The DAG representation encodes both precedence and resource constraints, ensuring correctness while exposing all available parallelism. Experiments across five benchmark scenarios demonstrate that OSDAG achieves 5-15x faster reasoning time compared to dialogue-based methods, reduces makespan by up to 38% over sequential baselines, and maintains competitive success rates. Both simulation and real-world experiments on dual-arm manipulation tasks validate the effectiveness and practicality of the proposed approach for efficient multi-robot coordination. The website and resources are available at http://thanhnguyencanh.github.io/LLM_DAG4MultiRobot
BPDA-GMM: Bayesian Probabilistic Data Association via Gaussian Mixture Models for Semantic SLAM
Jun 03, 2026Probabilistic data association (PDA) improves semantic SLAM in perceptually aliased scenes, but existing methods often assume a fixed landmark set, recompute association weights as the map grows, or rely on hand-tuned null-hypothesis weights. To address these limitations, we propose \textbf{BPDA-GMM}, an online Bayesian PDA framework for semantic SLAM with a growing object-level map. BPDA-GMM uses a Dirichlet-process prior to induce a Chinese Restaurant Process (CRP) association model, where accumulated evidence favors existing landmarks, and the concentration parameter assigns probability mass to new landmarks. For each semantic detection, plausible candidates are selected by a joint semantic-geometric gate, CRP-weighted association probabilities are computed, and object landmarks are updated as semantic Gaussians in closed form. The resulting landmark set forms a Gaussian mixture model, and its dominant component is passed to the back-end as a max-mixture semantic factor. When association weights are inconclusive, an ambiguity-triggered $α$-divergence tempering step improves discrimination. Finally, a decoupled back-end zeroes the pose Jacobian of semantic factors, allowing noisy detections to refine landmarks without directly perturbing the trajectory. Experiments in simulation and on a real indoor dataset demonstrate improved trajectory accuracy, semantic mapping quality, and robustness to perceptual aliasing and classifier errors over state-of-the-art baselines. Code and video are publicly available at https://github.com/thanhnguyencanh/BPDA-SLAM.
Con-DSO: Learning Short-Horizon Consistency Priors for RGB-D Direct Sparse Odometry
May 27, 2026Visual odometry (VO) is a fundamental component in robotics and augmented reality. RGB-D direct VO benefits from metric depth measurements, but it can degrade in challenging environments, where dynamic objects, occlusions, illumination changes, and unreliable depth violate the short-horizon photometric and depth-geometric consistency assumptions used by direct alignment. Existing approaches mitigate these issues through semantic filtering, explicit occlusion reasoning, illumination adaptation, or hand-crafted geometric criteria, but often rely on external modules or fixed assumptions tailored to individual failure modes, limiting their flexibility and ability to handle diverse challenges in a unified manner. In this work, we propose Con-DSO, a consistency-aware RGB-D direct sparse odometry framework that predicts dense photometric and depth-geometric consistency uncertainty from temporally adjacent RGB-D frame pairs. The consistency network is trained using flow-guided photometric errors and projective depth-consistency errors, allowing consistency violations to be represented as pixel-level uncertainty. These pairwise uncertainty predictions are converted into a host-side quality prior for keyframe-based tracking. The prior is then applied to VO through quality-aware support-pixel selection and decoupled photometric-geometric weighting during pose estimation, enabling continuous attenuation of unreliable observations rather than hard rejection or threshold-based gating. Experiments on five public RGB-D benchmarks show substantial gains over direct RGB-D VO baselines, with over 20\% absolute trajectory error reduction on ICL-NUIM and 50\%--80\% reductions on RGB-D Scenes V2, TUM/Bonn Dynamic, and OpenLORIS sequences.
Multimodal Adversarial Quality Policy for Safe Grasping
Mar 02, 2026Vision-guided robot grasping based on Deep Neural Networks (DNNs) generalizes well but poses safety risks in the Human-Robot Interaction (HRI). Recent works solved it by designing benign adversarial attacks and patches with RGB modality, yet depth-independent characteristics limit their effectiveness on RGBD modality. In this work, we propose the Multimodal Adversarial Quality Policy (MAQP) to realize multimodal safe grasping. Our framework introduces two key components. First, the Heterogeneous Dual-Patch Optimization Scheme (HDPOS) mitigates the distribution discrepancy between RGB and depth modalities in patch generation by adopting modality-specific initialization strategies, employing a Gaussian distribution for depth patches and a uniform distribution for RGB patches, while jointly optimizing both modalities under a unified objective function. Second, the Gradient-Level Modality Balancing Strategy (GLMBS) is designed to resolve the optimization imbalance from RGB and Depth patches in patch shape adaptation by reweighting gradient contributions based on per-channel sensitivity analysis and applying distance-adaptive perturbation bounds. We conduct extensive experiments on the benchmark datasets and a cobot, showing the effectiveness of MAQP.
Hybrid TD3: Overestimation Bias Analysis and Stable Policy Optimization for Hybrid Action Space
Mar 01, 2026Reinforcement learning in discrete-continuous hybrid action spaces presents fundamental challenges for robotic manipulation, where high-level task decisions and low-level joint-space execution must be jointly optimized. Existing approaches either discretize continuous components or relax discrete choices into continuous approximations, which suffer from scalability limitations and training instability in high-dimensional action spaces and under domain randomization. In this paper, we propose Hybrid TD3, an extension of Twin Delayed Deep Deterministic Policy Gradient (TD3) that natively handles parameterized hybrid action spaces in a principled manner. We conduct a rigorous theoretical analysis of overestimation bias in hybrid action settings, deriving formal bounds under twin-critic architectures and establishing a complete bias ordering across five algorithmic variants. Building on this analysis, we introduce a weighted clipped Q-learning target that marginalizes over the discrete action distribution, achieving equivalent bias reduction to standard clipped minimization while improving policy smoothness. Experimental results demonstrate that Hybrid TD3 achieves superior training stability and competitive performance against state-of-the-art hybrid action baselines
Human-to-Robot Interaction: Learning from Video Demonstration for Robot Imitation
Feb 22, 2026Learning from Demonstration (LfD) offers a promising paradigm for robot skill acquisition. Recent approaches attempt to extract manipulation commands directly from video demonstrations, yet face two critical challenges: (1) general video captioning models prioritize global scene features over task-relevant objects, producing descriptions unsuitable for precise robotic execution, and (2) end-to-end architectures coupling visual understanding with policy learning require extensive paired datasets and struggle to generalize across objects and scenarios. To address these limitations, we propose a novel ``Human-to-Robot'' imitation learning pipeline that enables robots to acquire manipulation skills directly from unstructured video demonstrations, inspired by the human ability to learn by watching and imitating. Our key innovation is a modular framework that decouples the learning process into two distinct stages: (1) Video Understanding, which combines Temporal Shift Modules (TSM) with Vision-Language Models (VLMs) to extract actions and identify interacted objects, and (2) Robot Imitation, which employs TD3-based deep reinforcement learning to execute the demonstrated manipulations. We validated our approach in PyBullet simulation environments with a UR5e manipulator and in a real-world experiment with a UF850 manipulator across four fundamental actions: reach, pick, move, and put. For video understanding, our method achieves 89.97% action classification accuracy and BLEU-4 scores of 0.351 on standard objects and 0.265 on novel objects, representing improvements of 76.4% and 128.4% over the best baseline, respectively. For robot manipulation, our framework achieves an average success rate of 87.5% across all actions, with 100% success on reaching tasks and up to 90% on complex pick-and-place operations. The project website is available at https://thanhnguyencanh.github.io/LfD4hri.
IRAF-SLAM: An Illumination-Robust and Adaptive Feature-Culling Front-End for Visual SLAM in Challenging Environments
Jul 10, 2025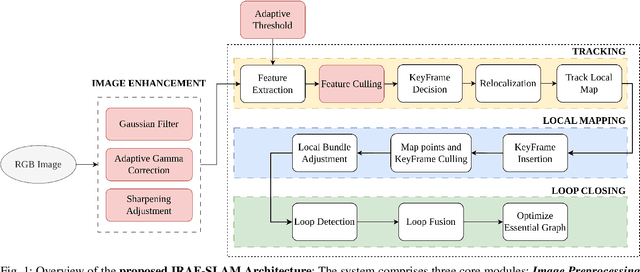
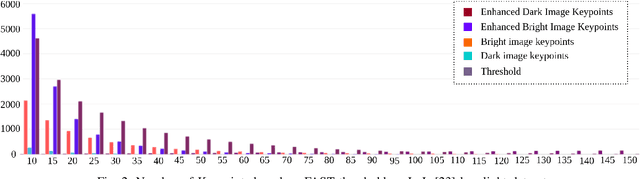

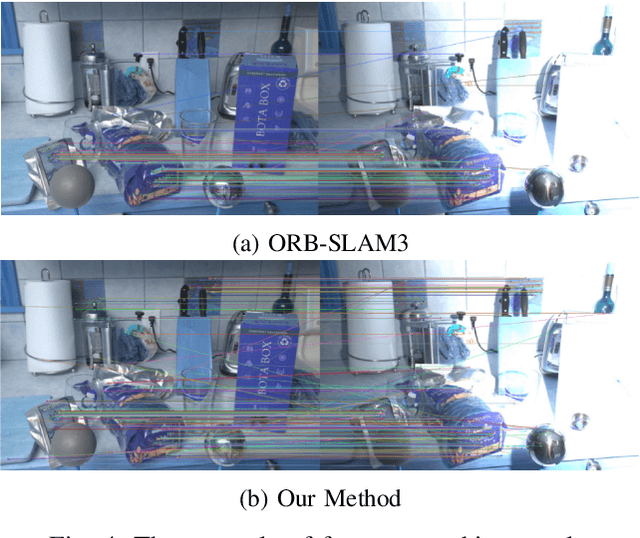
Robust Visual SLAM (vSLAM) is essential for autonomous systems operating in real-world environments, where challenges such as dynamic objects, low texture, and critically, varying illumination conditions often degrade performance. Existing feature-based SLAM systems rely on fixed front-end parameters, making them vulnerable to sudden lighting changes and unstable feature tracking. To address these challenges, we propose ``IRAF-SLAM'', an Illumination-Robust and Adaptive Feature-Culling front-end designed to enhance vSLAM resilience in complex and challenging environments. Our approach introduces: (1) an image enhancement scheme to preprocess and adjust image quality under varying lighting conditions; (2) an adaptive feature extraction mechanism that dynamically adjusts detection sensitivity based on image entropy, pixel intensity, and gradient analysis; and (3) a feature culling strategy that filters out unreliable feature points using density distribution analysis and a lighting impact factor. Comprehensive evaluations on the TUM-VI and European Robotics Challenge (EuRoC) datasets demonstrate that IRAF-SLAM significantly reduces tracking failures and achieves superior trajectory accuracy compared to state-of-the-art vSLAM methods under adverse illumination conditions. These results highlight the effectiveness of adaptive front-end strategies in improving vSLAM robustness without incurring significant computational overhead. The implementation of IRAF-SLAM is publicly available at https://thanhnguyencanh. github.io/IRAF-SLAM/.
Quality-focused Active Adversarial Policy for Safe Grasping in Human-Robot Interaction
Mar 25, 2025Vision-guided robot grasping methods based on Deep Neural Networks (DNNs) have achieved remarkable success in handling unknown objects, attributable to their powerful generalizability. However, these methods with this generalizability tend to recognize the human hand and its adjacent objects as graspable targets, compromising safety during Human-Robot Interaction (HRI). In this work, we propose the Quality-focused Active Adversarial Policy (QFAAP) to solve this problem. Specifically, the first part is the Adversarial Quality Patch (AQP), wherein we design the adversarial quality patch loss and leverage the grasp dataset to optimize a patch with high quality scores. Next, we construct the Projected Quality Gradient Descent (PQGD) and integrate it with the AQP, which contains only the hand region within each real-time frame, endowing the AQP with fast adaptability to the human hand shape. Through AQP and PQGD, the hand can be actively adversarial with the surrounding objects, lowering their quality scores. Therefore, further setting the quality score of the hand to zero will reduce the grasping priority of both the hand and its adjacent objects, enabling the robot to grasp other objects away from the hand without emergency stops. We conduct extensive experiments on the benchmark datasets and a cobot, showing the effectiveness of QFAAP. Our code and demo videos are available here: https://github.com/clee-jaist/QFAAP.