 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRAF-SLAM: An Illumination-Robust and Adaptive Feature-Culling Front-End for Visual SLAM in Challenging Environments
Jul 10, 2025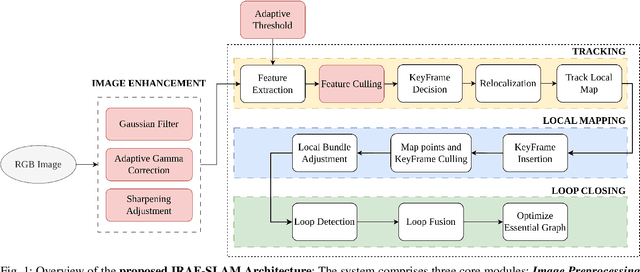
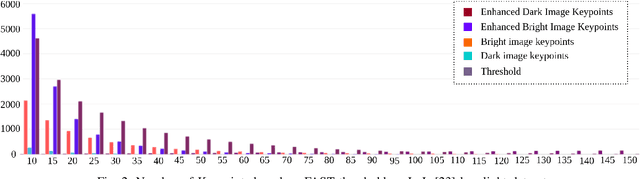

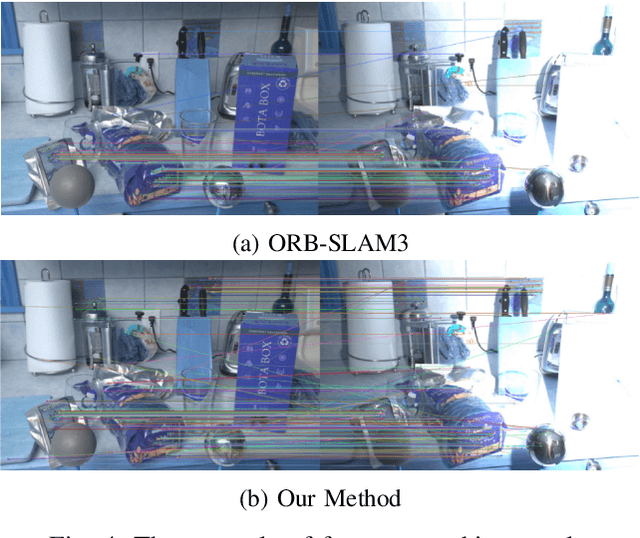
Robust Visual SLAM (vSLAM) is essential for autonomous systems operating in real-world environments, where challenges such as dynamic objects, low texture, and critically, varying illumination conditions often degrade performance. Existing feature-based SLAM systems rely on fixed front-end parameters, making them vulnerable to sudden lighting changes and unstable feature tracking. To address these challenges, we propose ``IRAF-SLAM'', an Illumination-Robust and Adaptive Feature-Culling front-end designed to enhance vSLAM resilience in complex and challenging environments. Our approach introduces: (1) an image enhancement scheme to preprocess and adjust image quality under varying lighting conditions; (2) an adaptive feature extraction mechanism that dynamically adjusts detection sensitivity based on image entropy, pixel intensity, and gradient analysis; and (3) a feature culling strategy that filters out unreliable feature points using density distribution analysis and a lighting impact factor. Comprehensive evaluations on the TUM-VI and European Robotics Challenge (EuRoC) datasets demonstrate that IRAF-SLAM significantly reduces tracking failures and achieves superior trajectory accuracy compared to state-of-the-art vSLAM methods under adverse illumination conditions. These results highlight the effectiveness of adaptive front-end strategies in improving vSLAM robustness without incurring significant computational overhead. The implementation of IRAF-SLAM is publicly available at https://thanhnguyencanh. github.io/IRAF-SLAM/.
ESRPCB: an Edge guided Super-Resolution model and Ensemble learning for tiny Printed Circuit Board Defect detection
Jun 16, 2025Printed Circuit Boards (PCBs) are critical components in modern electronics, which require stringent quality control to ensure proper functionality. However, the detection of defects in small-scale PCBs images poses significant challenges as a result of the low resolution of the captured images, leading to potential confusion between defects and noise. To overcome these challenges, this paper proposes a novel framework, named ESRPCB (edgeguided super-resolution for PCBs defect detection), which combines edgeguided super-resolution with ensemble learning to enhance PCBs defect detection. The framework leverages the edge information to guide the EDSR (Enhanced Deep Super-Resolution) model with a novel ResCat (Residual Concatenation) structure, enabling it to reconstruct high-resolution images from small PCBs inputs. By incorporating edge features, the super-resolution process preserves critical structural details, ensuring that tiny defects remain distinguishable in the enhanced image. Following this, a multi-modal defect detection model employs ensemble learning to analyze the super-resolved
A Rate-Quality Model for Learned Video Coding
May 05, 2025Learned video coding (LVC) has recently achieved superior coding performance. In this paper, we model the rate-quality (R-Q) relationship for learned video coding by a parametric function. We learn a neural network, termed RQNet, to characterize the relationship between the bitrate and quality level according to video content and coding context. The predicted (R,Q) results are further integrated with those from previously coded frames using the least-squares method to determine the parameters of our R-Q model on-the-fly. Compared to the conventional approaches, our method accurately estimates the R-Q relationship, enabling the online adaptation of model parameters to enhance both flexibility and precision. Experimental results show that our R-Q model achieves significantly smaller bitrate deviations than the baseline method on commonly used datasets with minimal additional complexity.
Flight Time Improvement Using Adaptive Model Predictive Control for Unmanned Aerial Vehicles
Nov 11, 2024Intelligent aerial platforms such as Unmanned Aerial Vehicles (UAVs) are expected to revolutionize various fields, including transportation, traffic management, field monitoring, industrial production, and agricultural management. Among these, precise control is a critical task that determines the performance and capabilities of UAV systems. However, current research primarily focuses on trajectory tracking and minimizing flight errors, with limited attention to improving flight time. In this paper, we propose a Model Predictive Control (MPC) approach aimed at minimizing flight time while addressing the limitations of the commonly used classical MPC controllers. Furthermore, the MPC method and its application for UAV control are presented in detail. Finally, the results demonstrate that the proposed controller outperforms the standard MPC in terms of efficiency. Moreover, this approach shows potential to become a foundation for integrating intelligent algorithms into basic controllers.
Quadrotor Trajectory Tracking Using Linear and Nonlinear Model Predictive Control
Nov 11, 2024Accurate trajectory tracking is an essential characteristic for the safe navigation of a quadrotor in cluttered or disturbed environments. In this paper, we present in detail two state-of-the-art model-based control frameworks for trajectory tracking: the Linear Model Predictive Controller (LMPC) and the Nonlinear Model Predictive Controller (NMPC). Additionally, the kinematic and dynamic models of the quadrotor are comprehensively described. Finally, a simulation system is implemented to verify feasibility, demonstrating the effectiveness of both controllers.
Development of a Human-Robot Interaction Platform for Dual-Arm Robots Based on ROS and Multimodal Artificial Intelligence
Nov 08, 2024In this paper, we propose the development of an interactive platform between humans and a dual-arm robotic system based on the Robot Operating System (ROS) and a multimodal artificial intelligence model. Our proposed platform consists of two main components: a dual-arm robotic hardware system and software that includes image processing tasks and natural language processing using a 3D camera and embedded computing. First, we designed and developed a dual-arm robotic system with a positional accuracy of less than 2 cm, capable of operating independently, performing industrial and service tasks while simultaneously simulating and modeling the robot in the ROS environment. Second, artificial intelligence models for image processing are integrated to execute object picking and classification tasks with an accuracy of over 90%. Finally, we developed remote control software using voice commands through a natural language processing model. Experimental results demonstrate the accuracy of the multimodal artificial intelligence model and the flexibility of the dual-arm robotic system in interactive human environments.
Enhancing Depth Image Estimation for Underwater Robots by Combining Image Processing and Machine Learning
Nov 08, 2024Depth information plays a crucial role in autonomous systems for environmental perception and robot state estimation. With the rapid development of deep neural network technology, depth estimation has been extensively studied and shown potential for practical applications. However, in particularly challenging environments such as low-light and noisy underwater conditions, direct application of machine learning models may not yield the desired results. Therefore, in this paper, we present an approach to enhance underwater image quality to improve depth estimation effectiveness. First, underwater images are processed through methods such as color compensation, brightness equalization, and enhancement of contrast and sharpness of objects in the image. Next, we perform depth estimation using the Udepth model on the enhanced images. Finally, the results are evaluated and presented to verify the effectiveness and accuracy of the enhanced depth image quality approach for underwater robots.
Development of an indoor localization and navigation system based on monocular SLAM for mobile robots
Nov 08, 2024Localization and navigation are two crucial issues for mobile robots. In this paper, we propose an approach for localization and navigation systems for a differential-drive robot based on monocular SLAM. The system is implemented on the Robot Operating System (ROS). The hardware includes a differential-drive robot with an embedded computing platform (Jetson Xavier AGX), a 2D camera, and a LiDAR sensor for collecting external environmental information. The A* algorithm and Dynamic Window Approach (DWA) are used for path planning based on a 2D grid map. The ORB_SLAM3 algorithm is utilized to extract environmental features, providing the robot's pose for the localization and navigation processes. Finally, the system is tested in the Gazebo simulation environment and visualized through Rviz, demonstrating the efficiency and potential of the system for indoor localization and navigation of mobile robots.
Toward Integrating Semantic-aware Path Planning and Reliable Localization for UAV Operations
Nov 04, 2024

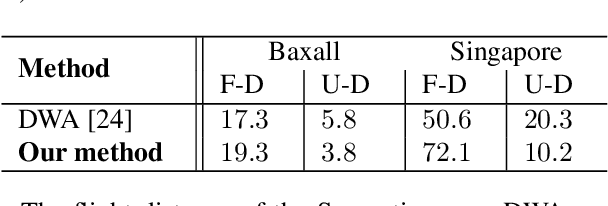
Localization is one of the most crucial tasks for Unmanned Aerial Vehicle systems (UAVs) directly impacting overall performance, which can be achieved with various sensors and applied to numerous tasks related to search and rescue operations, object tracking, construction, etc. However, due to the negative effects of challenging environments, UAVs may lose signals for localization. In this paper, we present an effective path-planning system leveraging semantic segmentation information to navigate around texture-less and problematic areas like lakes, oceans, and high-rise buildings using a monocular camera. We introduce a real-time semantic segmentation architecture and a novel keyframe decision pipeline to optimize image inputs based on pixel distribution, reducing processing time. A hierarchical planner based on the Dynamic Window Approach (DWA) algorithm, integrated with a cost map, is designed to facilitate efficient path planning. The system is implemented in a photo-realistic simulation environment using Unity, aligning with segmentation model parameters. Comprehensive qualitative and quantitative evaluations validate the effectiveness of our approach, showing significant improvements in the reliability and efficiency of UAV localization in challenging environments.
Enhancing Social Robot Navigation with Integrated Motion Prediction and Trajectory Planning in Dynamic Human Environments
Nov 04, 2024Navigating safely in dynamic human environments is crucial for mobile service robots, and social navigation is a key aspect of this process. In this paper, we proposed an integrative approach that combines motion prediction and trajectory planning to enable safe and socially-aware robot navigation. The main idea of the proposed method is to leverage the advantages of Socially Acceptable trajectory prediction and Timed Elastic Band (TEB) by incorporating human interactive information including position, orientation, and motion into the objective function of the TEB algorithms. In addition, we designed social constraints to ensure the safety of robot navigation. The proposed system is evaluated through physical simulation using both quantitative and qualitative metrics, demonstrating its superior performance in avoiding human and dynamic obstacles, thereby ensuring safe navigation. The implementations are open source at: \url{https://github.com/thanhnguyencanh/SGan-TEB.git}