 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation Capabilities of Neural Networks using Morphological Perceptrons and Generalizations
Jul 16, 2022

Standard artificial neural networks (ANNs) use sum-product or multiply-accumulate node operations with a memoryless nonlinear activation. These neural networks are known to have universal function approximation capabilities. Previously proposed morphological perceptrons use max-sum, in place of sum-product, node processing and have promising properties for circuit implementations. In this paper we show that these max-sum ANNs do not have universal approximation capabilities. Furthermore, we consider proposed signed-max-sum and max-star-sum generalizations of morphological ANNs and show that these variants also do not have universal approximation capabilities. We contrast these variations to log-number system (LNS) implementations which also avoid multiplications, but do exhibit universal approximation capabilities.
Improved Analysis of Current-Steering DACs Using Equivalent Timing Errors
Mar 16, 2022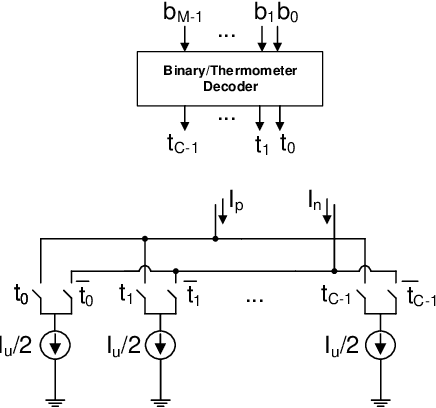
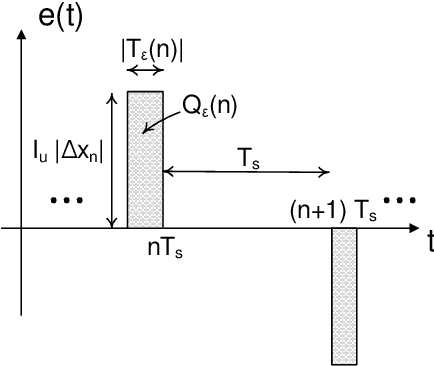
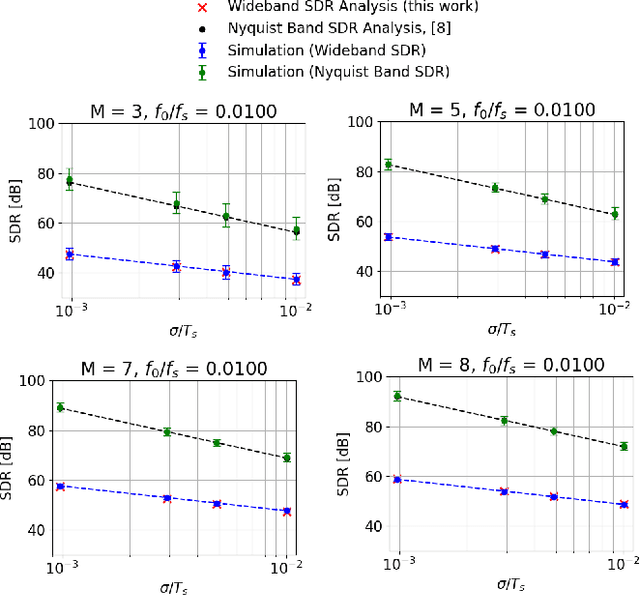
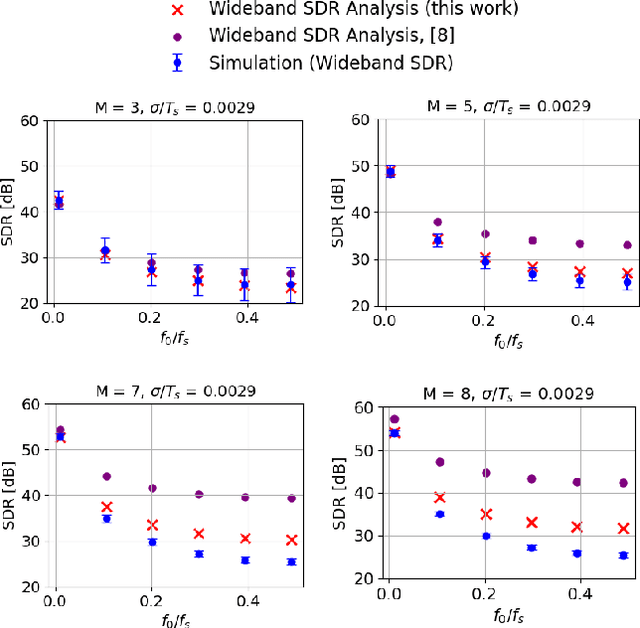
Current-steering (CS) digital-to-analog converters (DACs) generate analog signals by combining weighted current sources. Ideally, the current sources are combined at each switching instant simultaneously. However, this is not true in practice due to timing mismatch, resulting in nonlinear distortion. This work uses the equivalent timing error model, introduced by previous work, to analyze the signal-to-distortion ratio (SDR) resulting from these timing errors. Using a behavioral simulation model we demonstrate that our analysis is significantly more accurate than the previous methods. We also use our simulation model to investigate the effect of timing mismatch in partially-segmented CS-DACs, i.e., those comprised of both equally-weighted and binary-weighted current sources.
Deep-n-Cheap: An Automated Search Framework for Low Complexity Deep Learning
Apr 03, 2020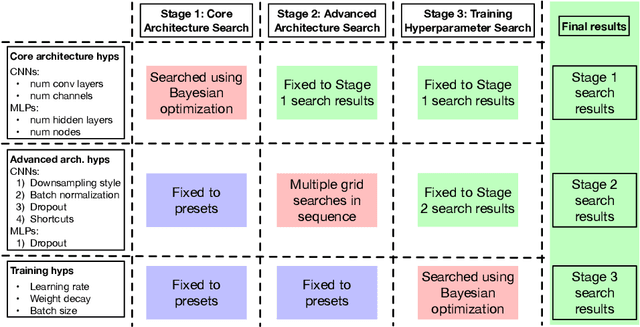

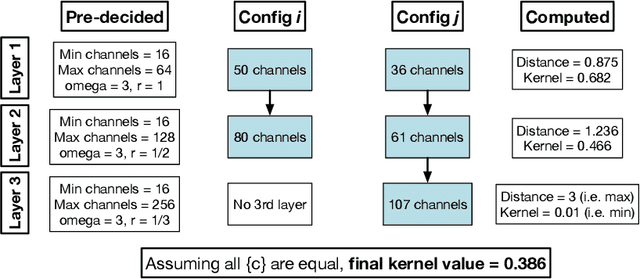
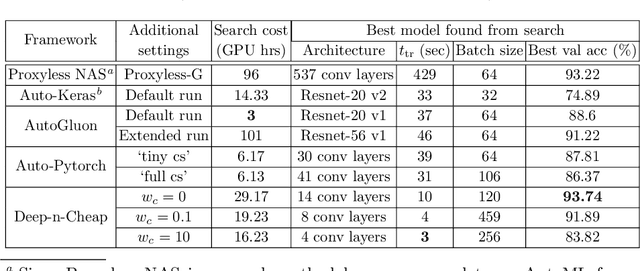
We present Deep-n-Cheap -- an open-source AutoML framework to search for deep learning models. This search includes both architecture and training hyperparameters, and supports convolutional neural networks and multi-layer perceptrons. Our framework is targeted for deployment on both benchmark and custom datasets, and as a result, offers a greater degree of search space customizability as compared to a more limited search over only pre-existing models from literature. We also introduce the technique of 'search transfer', which demonstrates the generalization capabilities of the models found by our framework to multiple datasets. Deep-n-Cheap includes a user-customizable complexity penalty which trades off performance with training time or number of parameters. Specifically, our framework results in models offering performance comparable to state-of-the-art while taking 1-2 orders of magnitude less time to train than models from other AutoML and model search frameworks. Additionally, this work investigates and develops various insights regarding the search process. In particular, we show the superiority of a greedy strategy and justify our choice of Bayesian optimization as the primary search methodology over random / grid search.
Pre-defined Sparsity for Low-Complexity Convolutional Neural Networks
Feb 04, 2020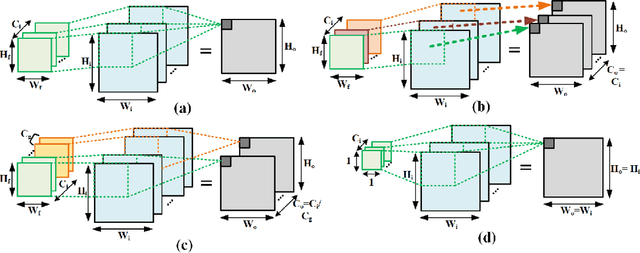

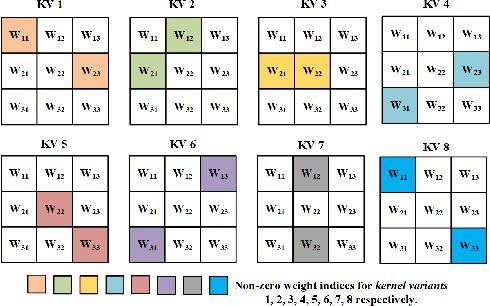
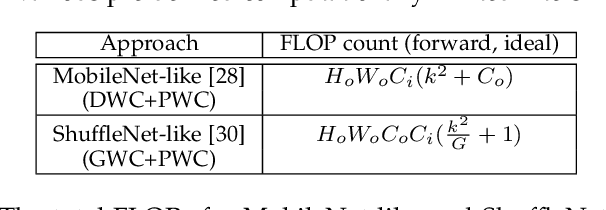
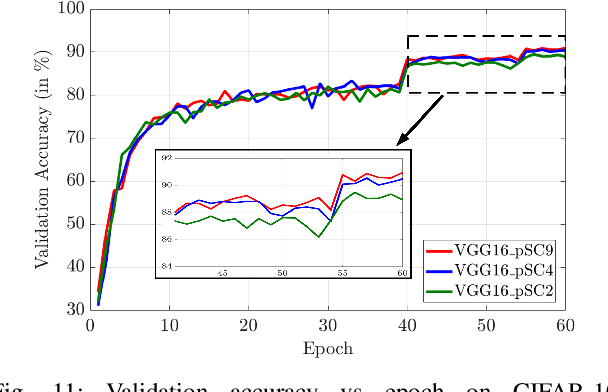
The high energy cost of processing deep convolutional neural networks impedes their ubiquitous deployment in energy-constrained platforms such as embedded systems and IoT devices. This work introduces convolutional layers with pre-defined sparse 2D kernels that have support sets that repeat periodically within and across filters. Due to the efficient storage of our periodic sparse kernels, the parameter savings can translate into considerable improvements in energy efficiency due to reduced DRAM accesses, thus promising significant improvements in the trade-off between energy consumption and accuracy for both training and inference. To evaluate this approach, we performed experiments with two widely accepted datasets, CIFAR-10 and Tiny ImageNet in sparse variants of the ResNet18 and VGG16 architectures. Compared to baseline models, our proposed sparse variants require up to 82% fewer model parameters with 5.6times fewer FLOPs with negligible loss in accuracy for ResNet18 on CIFAR-10. For VGG16 trained on Tiny ImageNet, our approach requires 5.8times fewer FLOPs and up to 83.3% fewer model parameters with a drop in top-5 (top-1) accuracy of only 1.2% (2.1%). We also compared the performance of our proposed architectures with that of ShuffleNet andMobileNetV2. Using similar hyperparameters and FLOPs, our ResNet18 variants yield an average accuracy improvement of 2.8%.
Neural Network Training with Approximate Logarithmic Computations
Oct 22, 2019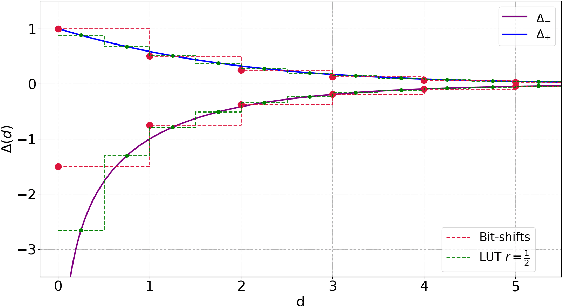
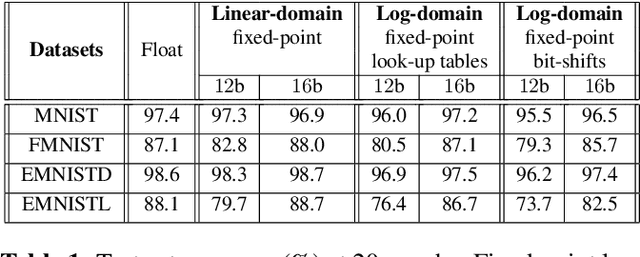
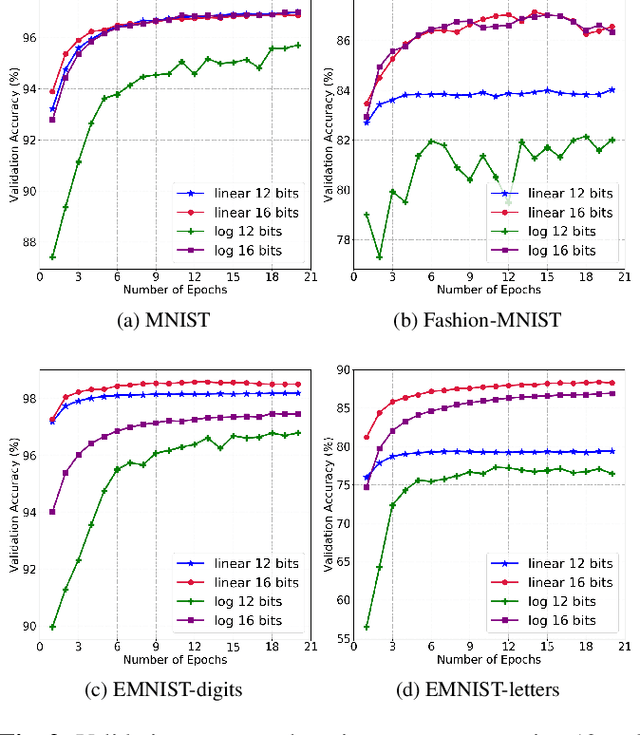
The high computational complexity associated with training deep neural networks limits online and real-time training on edge devices. This paper proposed an end-to-end training and inference scheme that eliminates multiplications by approximate operations in the log-domain which has the potential to significantly reduce implementation complexity. We implement the entire training procedure in the log-domain, with fixed-point data representations. This training procedure is inspired by hardware-friendly approximations of log-domain addition which are based on look-up tables and bit-shifts. We show that our 16-bit log-based training can achieve classification accuracy within approximately 1% of the equivalent floating-point baselines for a number of commonly used datasets.
A Pre-defined Sparse Kernel Based Convolution for Deep CNNs
Oct 16, 2019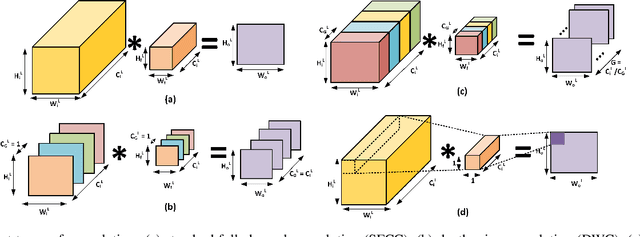
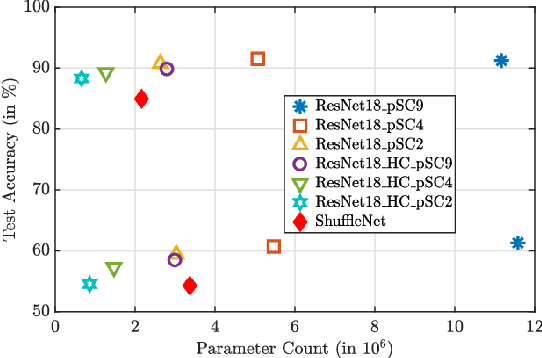
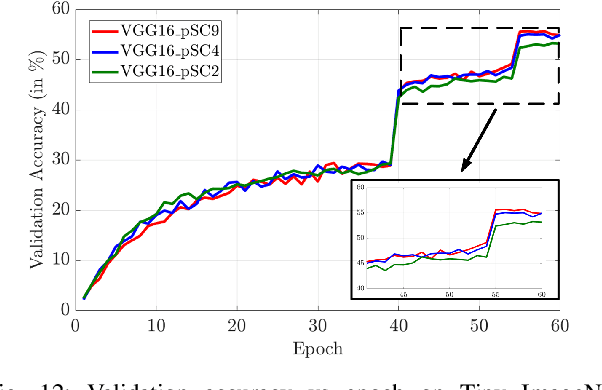
The high demand for computational and storage resources severely impede the deployment of deep convolutional neural networks (CNNs) in limited-resource devices. Recent CNN architectures have proposed reduced complexity versions (e.g. SuffleNet and MobileNet) but at the cost of modest decreases inaccuracy. This paper proposes pSConv, a pre-defined sparse 2D kernel-based convolution, which promises significant improvements in the trade-off between complexity and accuracy for both CNN training and inference. To explore the potential of this approach, we have experimented with two widely accepted datasets, CIFAR-10 and Tiny ImageNet, in sparse variants of both the ResNet18 and VGG16 architectures. Our approach shows a parameter count reduction of up to 4.24x with modest degradation in classification accuracy relative to that of standard CNNs. Our approach outperforms a popular variant of ShuffleNet using a variant of ResNet18 with pSConv having 3x3 kernels with only four of nine elements not fixed at zero. In particular, the parameter count is reduced by 1.7x for CIFAR-10 and 2.29x for Tiny ImageNet with an increased accuracy of ~4%.
Pre-Defined Sparse Neural Networks with Hardware Acceleration
Dec 04, 2018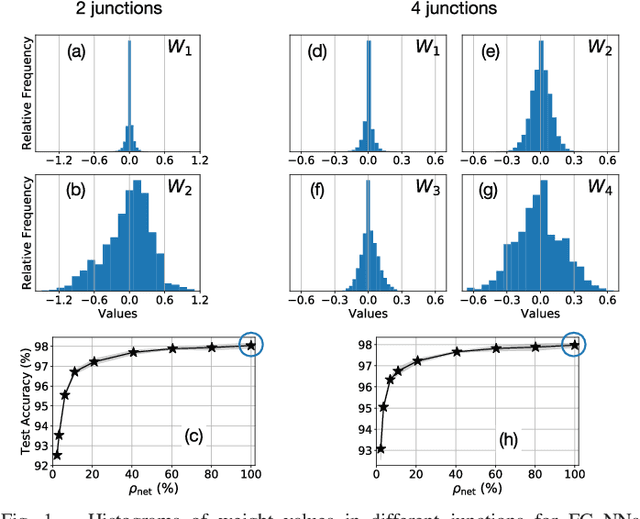
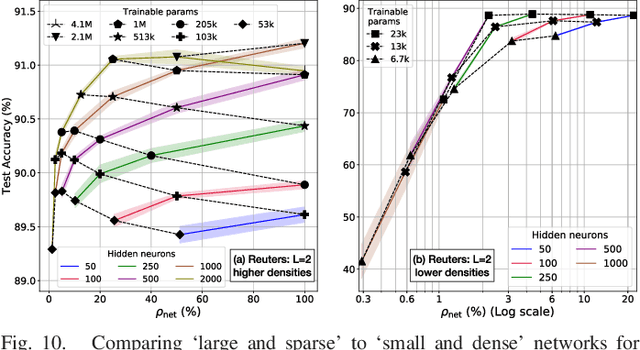
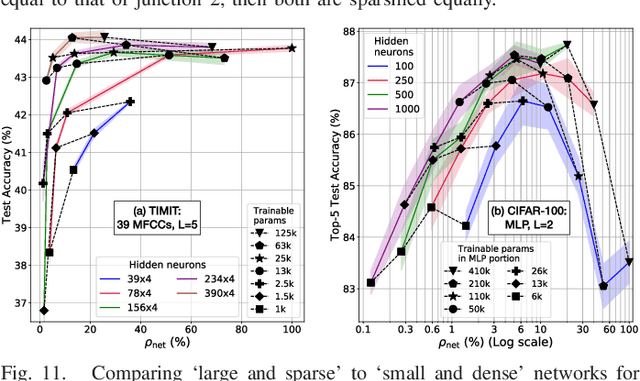
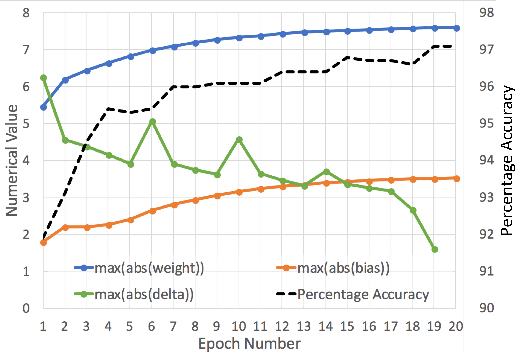
Neural networks have proven to be extremely powerful tools for modern artificial intelligence applications, but computational and storage complexity remain limiting factors. This paper presents two compatible contributions towards reducing the time, energy, computational, and storage complexities associated with multilayer perceptrons. Pre-defined sparsity is proposed to reduce the complexity during both training and inference, regardless of the implementation platform. Our results show that storage and computational complexity can be reduced by factors greater than 5X without significant performance loss. The second contribution is an architecture for hardware acceleration that is compatible with pre-defined sparsity. This architecture supports both training and inference modes and is flexible in the sense that it is not tied to a specific number of neurons. For example, this flexibility implies that various sized neural networks can be supported on various sized Field Programmable Gate Array (FPGA)s.
A Highly Parallel FPGA Implementation of Sparse Neural Network Training
Oct 11, 2018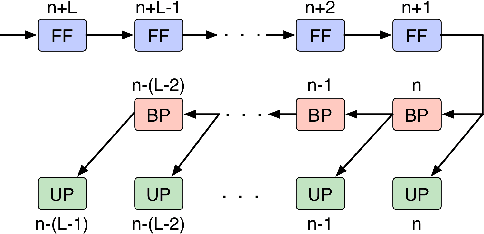
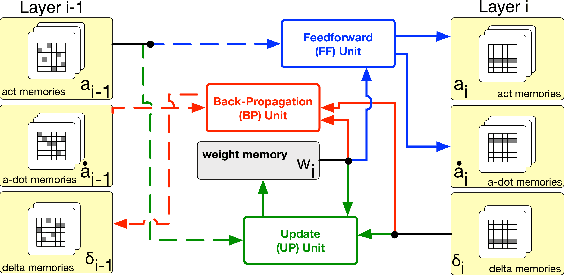
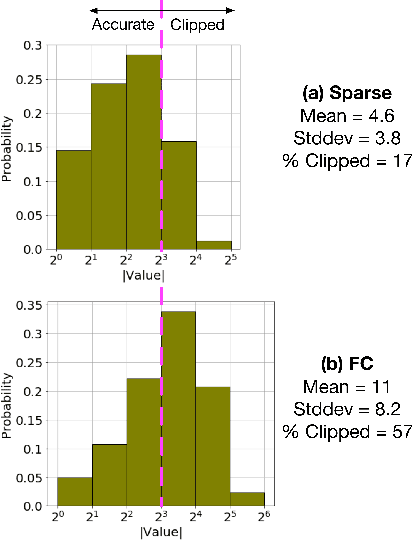
We demonstrate an FPGA implementation of a parallel and reconfigurable architecture for sparse neural networks, capable of on-chip training and inference. The network connectivity uses pre-determined, structured sparsity to significantly reduce complexity by lowering memory and computational requirements. The architecture uses a notion of edge-processing, leading to efficient pipelining and parallelization. Moreover, the device can be reconfigured to trade off resource utilization with training time to fit networks and datasets of varying sizes. The combined effects of complexity reduction and easy reconfigurability enable significantly greater exploration of network hyperparameters and structures on-chip. As proof of concept, we show implementation results on an Artix-7 FPGA.
Morse Code Datasets for Machine Learning
Jul 11, 2018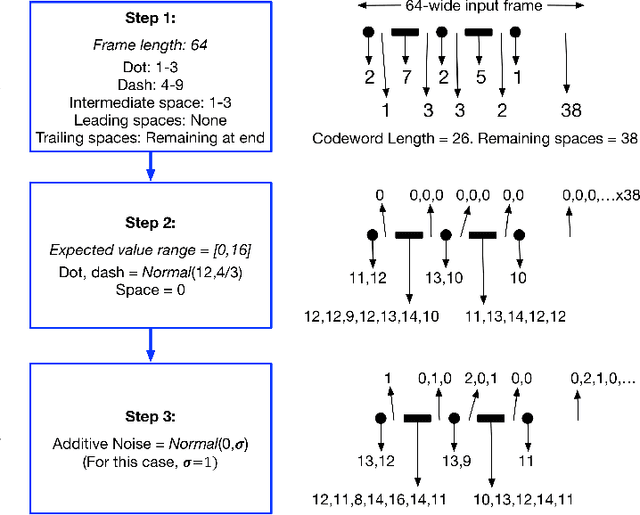
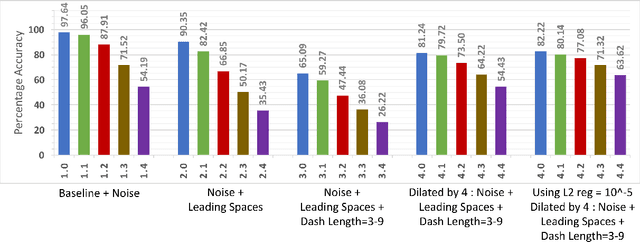
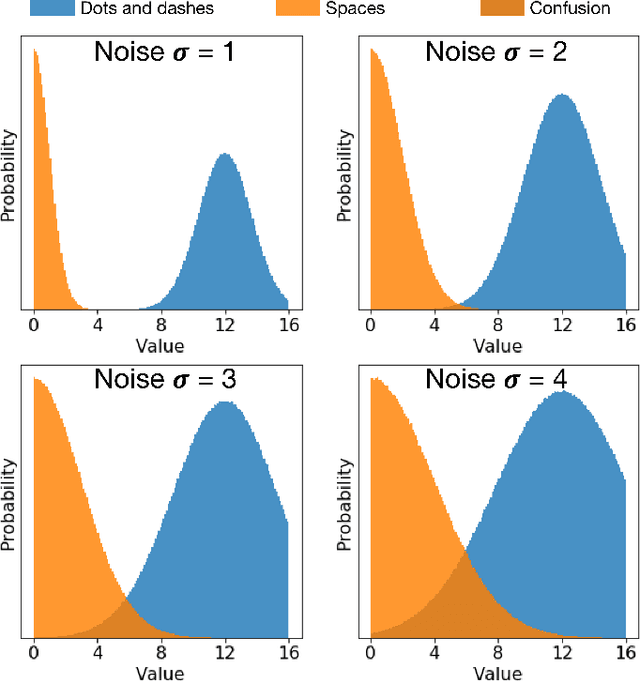
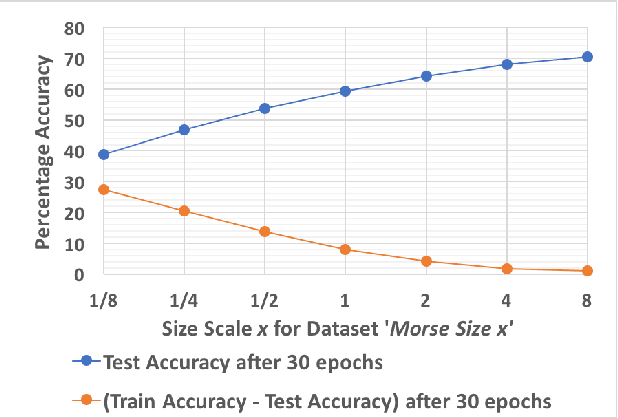
We present an algorithm to generate synthetic datasets of tunable difficulty on classification of Morse code symbols for supervised machine learning problems, in particular, neural networks. The datasets are spatially one-dimensional and have a small number of input features, leading to high density of input information content. This makes them particularly challenging when implementing network complexity reduction methods. We explore how network performance is affected by deliberately adding various forms of noise and expanding the feature set and dataset size. Finally, we establish several metrics to indicate the difficulty of a dataset, and evaluate their merits. The algorithm and datasets are open-source.
Interleaver Design for Deep Neural Networks
Apr 22, 2018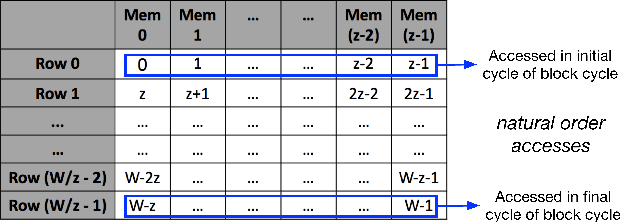
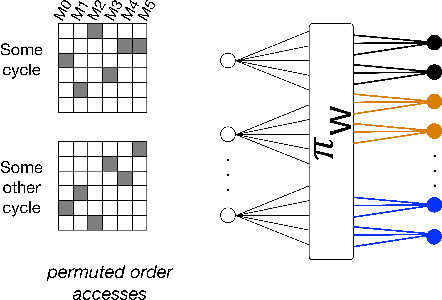
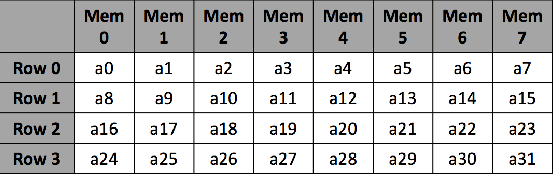
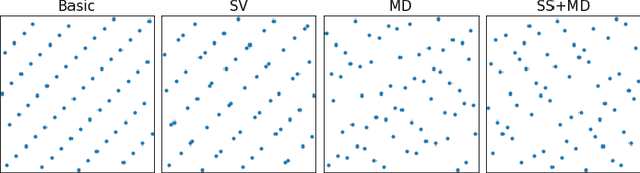
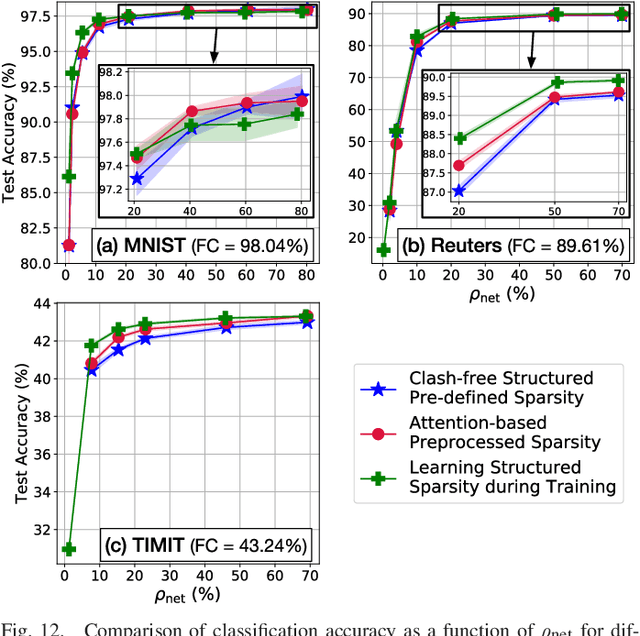
We propose a class of interleavers for a novel deep neural network (DNN) architecture that uses algorithmically pre-determined, structured sparsity to significantly lower memory and computational requirements, and speed up training. The interleavers guarantee clash-free memory accesses to eliminate idle operational cycles, optimize spread and dispersion to improve network performance, and are designed to ease the complexity of memory address computations in hardware. We present a design algorithm with mathematical proofs for these properties. We also explore interleaver variations and analyze the behavior of neural networks as a function of interleaver metrics.