Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorse Code Datasets for Machine Learning
Paper and Code
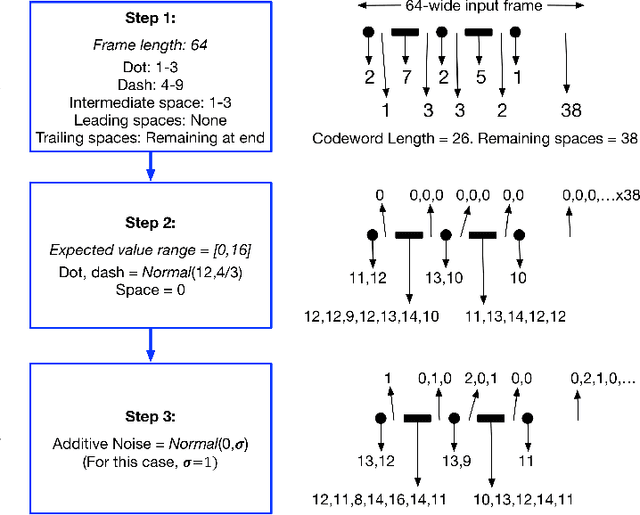
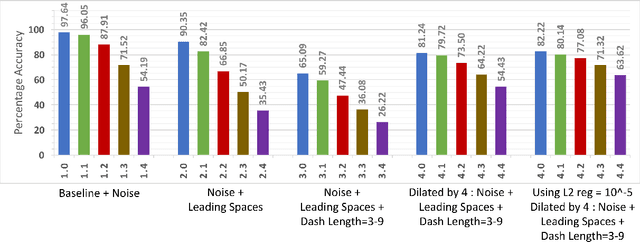
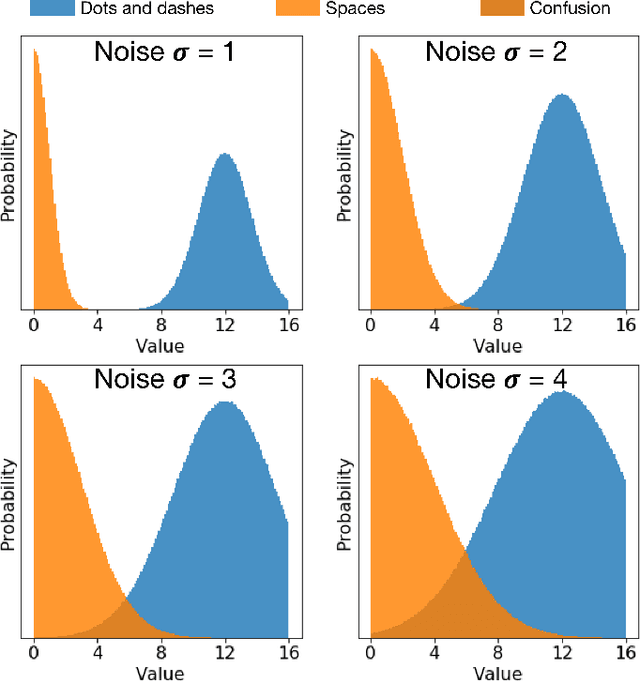
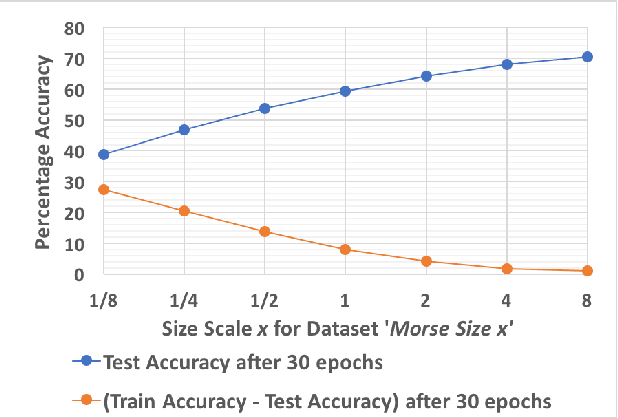
We present an algorithm to generate synthetic datasets of tunable difficulty on classification of Morse code symbols for supervised machine learning problems, in particular, neural networks. The datasets are spatially one-dimensional and have a small number of input features, leading to high density of input information content. This makes them particularly challenging when implementing network complexity reduction methods. We explore how network performance is affected by deliberately adding various forms of noise and expanding the feature set and dataset size. Finally, we establish several metrics to indicate the difficulty of a dataset, and evaluate their merits. The algorithm and datasets are open-source.
* Presented at the 9th International Conference on Computing,
Communication and Networking Technologies (ICCCNT)
View paper on