 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Defined Sparse Neural Networks with Hardware Acceleration
Dec 04, 2018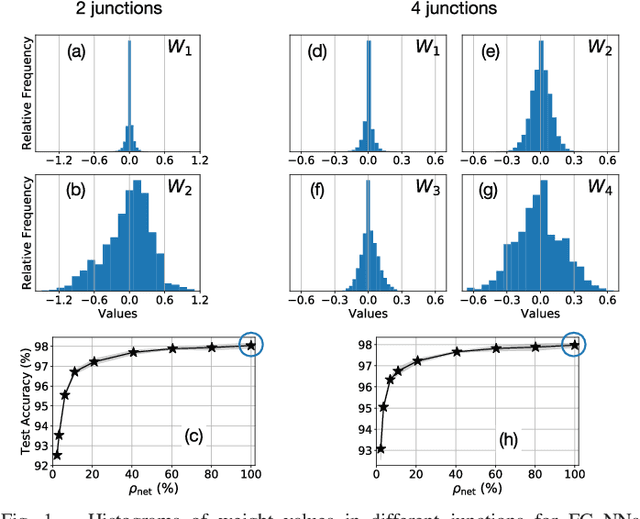
Neural networks have proven to be extremely powerful tools for modern artificial intelligence applications, but computational and storage complexity remain limiting factors. This paper presents two compatible contributions towards reducing the time, energy, computational, and storage complexities associated with multilayer perceptrons. Pre-defined sparsity is proposed to reduce the complexity during both training and inference, regardless of the implementation platform. Our results show that storage and computational complexity can be reduced by factors greater than 5X without significant performance loss. The second contribution is an architecture for hardware acceleration that is compatible with pre-defined sparsity. This architecture supports both training and inference modes and is flexible in the sense that it is not tied to a specific number of neurons. For example, this flexibility implies that various sized neural networks can be supported on various sized Field Programmable Gate Array (FPGA)s.
A Highly Parallel FPGA Implementation of Sparse Neural Network Training
Oct 11, 2018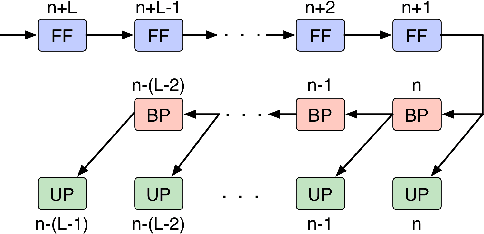
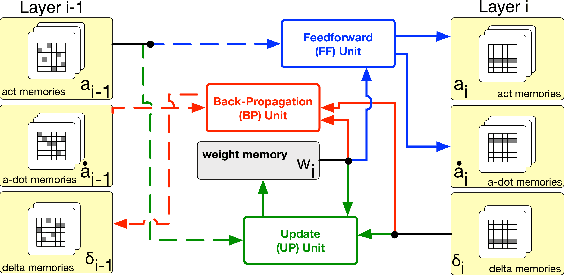
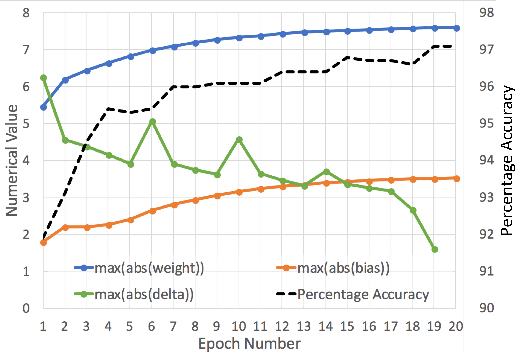
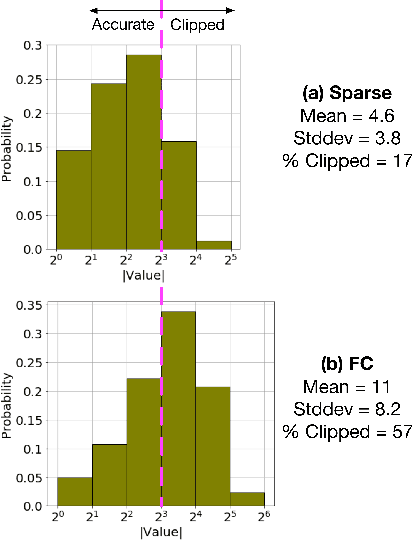
We demonstrate an FPGA implementation of a parallel and reconfigurable architecture for sparse neural networks, capable of on-chip training and inference. The network connectivity uses pre-determined, structured sparsity to significantly reduce complexity by lowering memory and computational requirements. The architecture uses a notion of edge-processing, leading to efficient pipelining and parallelization. Moreover, the device can be reconfigured to trade off resource utilization with training time to fit networks and datasets of varying sizes. The combined effects of complexity reduction and easy reconfigurability enable significantly greater exploration of network hyperparameters and structures on-chip. As proof of concept, we show implementation results on an Artix-7 FPGA.
Characterizing Sparse Connectivity Patterns in Neural Networks
Feb 23, 2018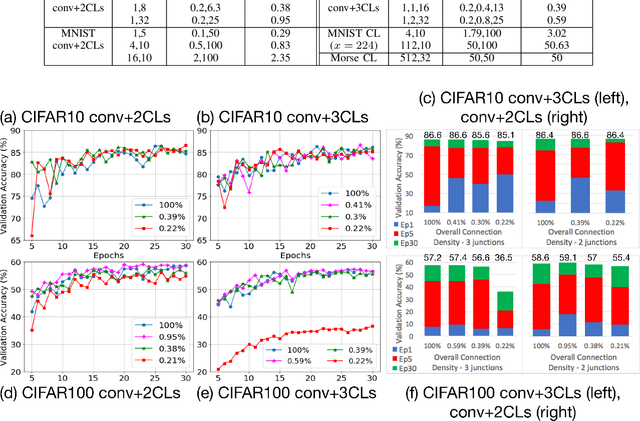
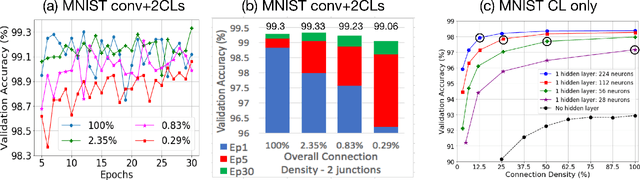
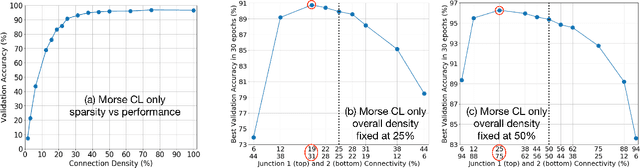
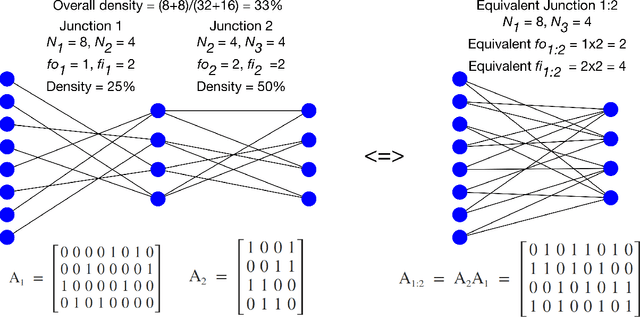
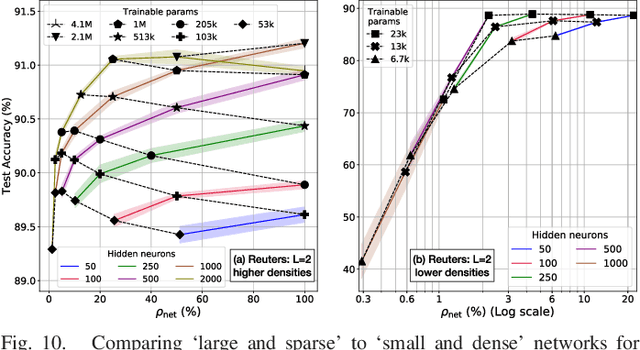
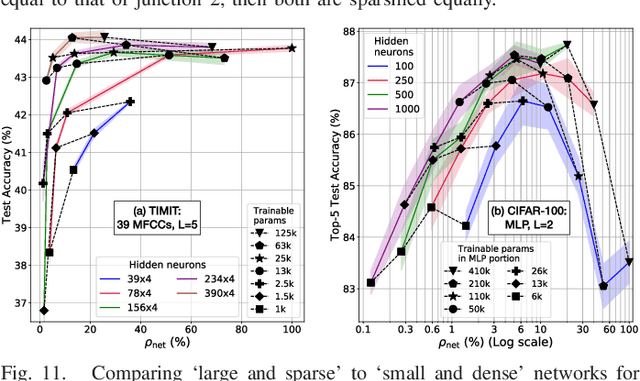
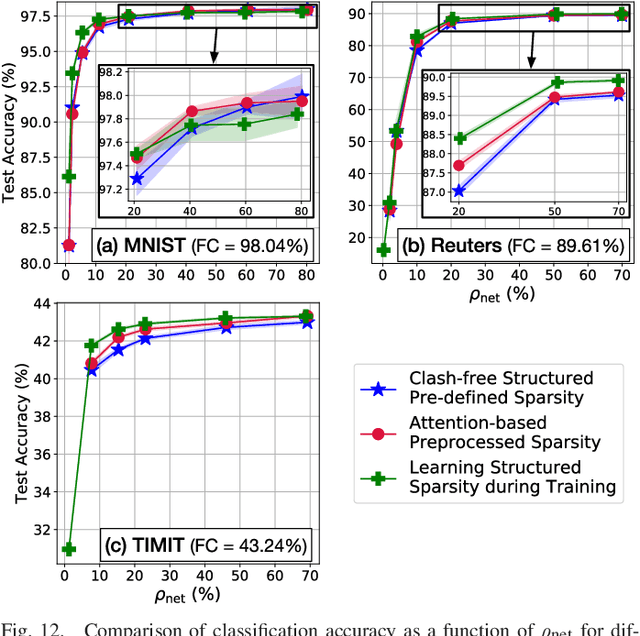
We propose a novel way of reducing the number of parameters in the storage-hungry fully connected layers of a neural network by using pre-defined sparsity, where the majority of connections are absent prior to starting training. Our results indicate that convolutional neural networks can operate without any loss of accuracy at less than half percent classification layer connection density, or less than 5 percent overall network connection density. We also investigate the effects of pre-defining the sparsity of networks with only fully connected layers. Based on our sparsifying technique, we introduce the `scatter' metric to characterize the quality of a particular connection pattern. As proof of concept, we show results on CIFAR, MNIST and a new dataset on classifying Morse code symbols, which highlights some interesting trends and limits of sparse connection patterns.