 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Highly Parallel FPGA Implementation of Sparse Neural Network Training
Paper and Code
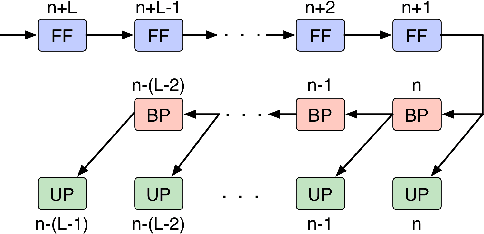
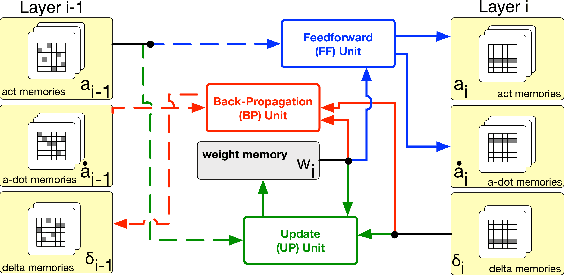
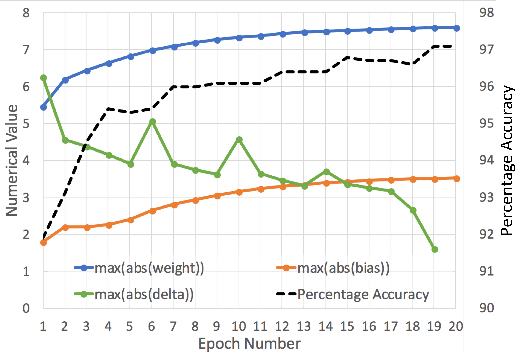
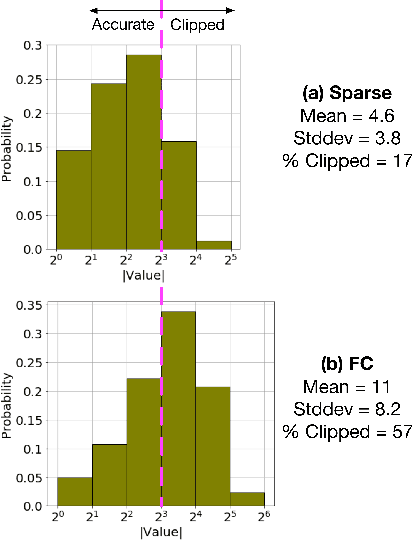
We demonstrate an FPGA implementation of a parallel and reconfigurable architecture for sparse neural networks, capable of on-chip training and inference. The network connectivity uses pre-determined, structured sparsity to significantly reduce complexity by lowering memory and computational requirements. The architecture uses a notion of edge-processing, leading to efficient pipelining and parallelization. Moreover, the device can be reconfigured to trade off resource utilization with training time to fit networks and datasets of varying sizes. The combined effects of complexity reduction and easy reconfigurability enable significantly greater exploration of network hyperparameters and structures on-chip. As proof of concept, we show implementation results on an Artix-7 FPGA.