Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the topology of the space of tokens with structured prompts
Mar 19, 2025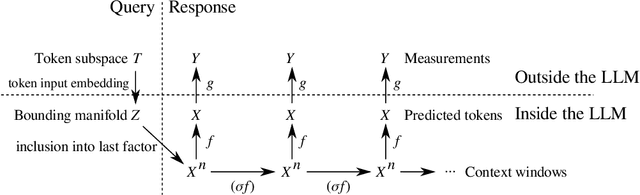

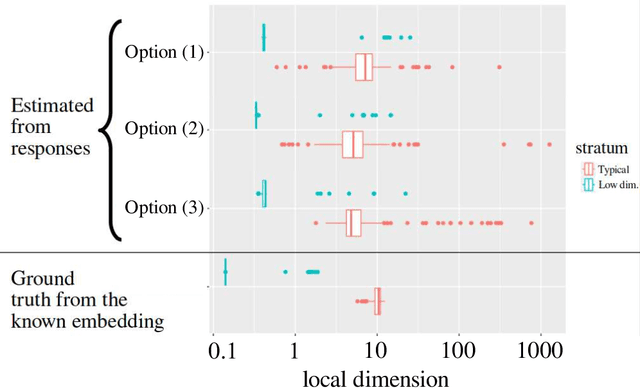
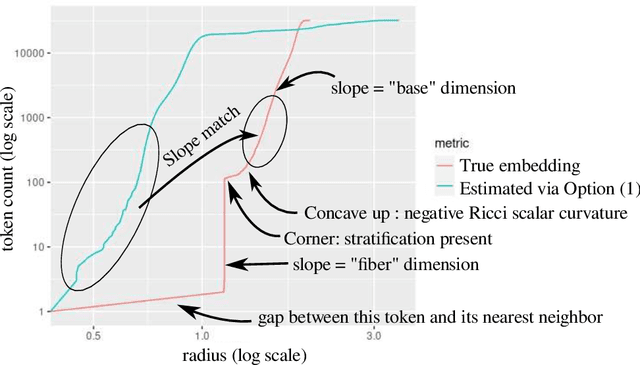
This article presents a general and flexible method for prompting a large language model (LLM) to reveal its (hidden) token input embedding up to homeomorphism. Moreover, this article provides strong theoretical justification -- a mathematical proof for generic LLMs -- for why this method should be expected to work. With this method in hand, we demonstrate its effectiveness by recovering the token subspace of Llemma-7B. The results of this paper apply not only to LLMs but also to general nonlinear autoregressive processes.
* 20 pages, 5 figures
Via