 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-power Spike-based Wearable Analytics on RRAM Crossbars
Feb 10, 2025



This work introduces a spike-based wearable analytics system utilizing Spiking Neural Networks (SNNs) deployed on an In-memory Computing engine based on RRAM crossbars, which are known for their compactness and energy-efficiency. Given the hardware constraints and noise characteristics of the underlying RRAM crossbars, we propose online adaptation of pre-trained SNNs in real-time using Direct Feedback Alignment (DFA) against traditional backpropagation (BP). Direct Feedback Alignment (DFA) learning, that allows layer-parallel gradient computations, acts as a fast, energy & area-efficient method for online adaptation of SNNs on RRAM crossbars, unleashing better algorithmic performance against those adapted using BP. Through extensive simulations using our in-house hardware evaluation engine called DFA_Sim, we find that DFA achieves upto 64.1% lower energy consumption, 10.1% lower area overhead, and a 2.1x reduction in latency compared to BP, while delivering upto 7.55% higher inference accuracy on human activity recognition (HAR) tasks.
* Accepted in 2025 IEEE International Symposium on Circuits and Systems (ISCAS)
When In-memory Computing Meets Spiking Neural Networks -- A Perspective on Device-Circuit-System-and-Algorithm Co-design
Aug 22, 2024



This review explores the intersection of bio-plausible artificial intelligence in the form of Spiking Neural Networks (SNNs) with the analog In-Memory Computing (IMC) domain, highlighting their collective potential for low-power edge computing environments. Through detailed investigation at the device, circuit, and system levels, we highlight the pivotal synergies between SNNs and IMC architectures. Additionally, we emphasize the critical need for comprehensive system-level analyses, considering the inter-dependencies between algorithms, devices, circuit & system parameters, crucial for optimal performance. An in-depth analysis leads to identification of key system-level bottlenecks arising from device limitations which can be addressed using SNN-specific algorithm-hardware co-design techniques. This review underscores the imperative for holistic device to system design space co-exploration, highlighting the critical aspects of hardware and algorithm research endeavors for low-power neuromorphic solutions.
TReX- Reusing Vision Transformer's Attention for Efficient Xbar-based Computing
Aug 22, 2024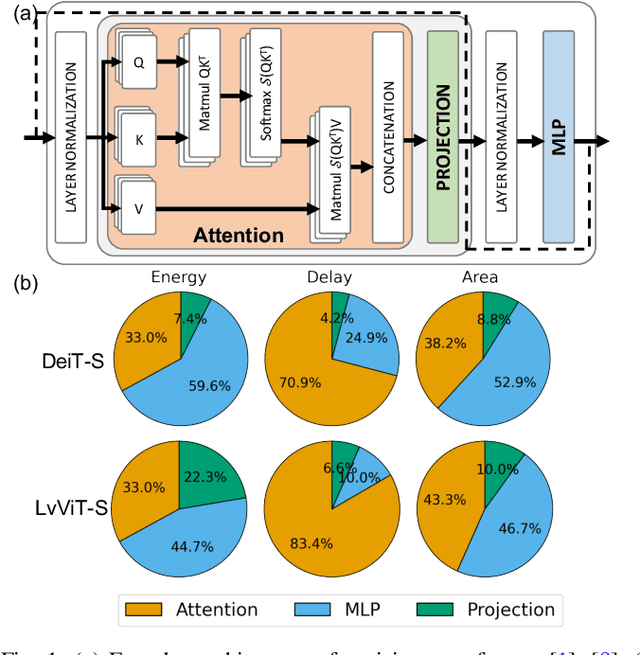
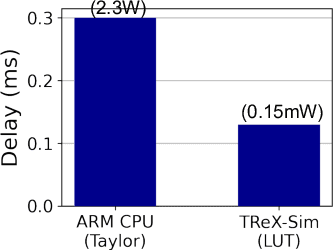
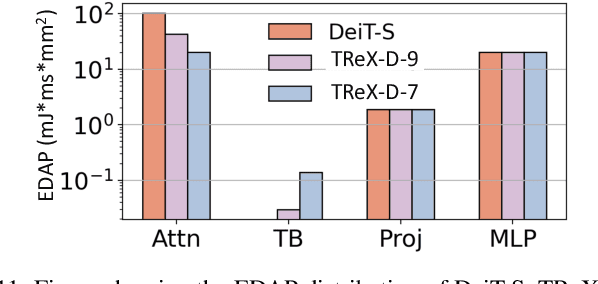
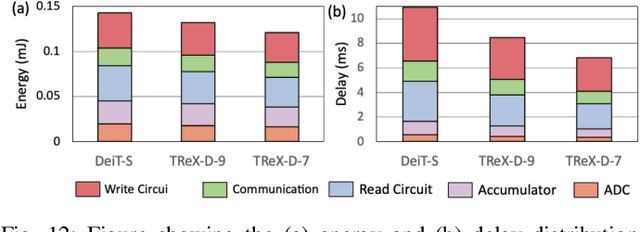
Due to the high computation overhead of Vision Transformers (ViTs), In-memory Computing architectures are being researched towards energy-efficient deployment in edge-computing scenarios. Prior works have proposed efficient algorithm-hardware co-design and IMC-architectural improvements to improve the energy-efficiency of IMC-implemented ViTs. However, all prior works have neglected the overhead and co-depencence of attention blocks on the accuracy-energy-delay-area of IMC-implemented ViTs. To this end, we propose TReX- an attention-reuse-driven ViT optimization framework that effectively performs attention reuse in ViT models to achieve optimal accuracy-energy-delay-area tradeoffs. TReX optimally chooses the transformer encoders for attention reuse to achieve near iso-accuracy performance while meeting the user-specified delay requirement. Based on our analysis on the Imagenet-1k dataset, we find that TReX achieves 2.3x (2.19x) EDAP reduction and 1.86x (1.79x) TOPS/mm2 improvement with ~1% accuracy drop in case of DeiT-S (LV-ViT-S) ViT models. Additionally, TReX achieves high accuracy at high EDAP reduction compared to state-of-the-art token pruning and weight sharing approaches. On NLP tasks such as CoLA, TReX leads to 2% higher non-ideal accuracy compared to baseline at 1.6x lower EDAP.
ClipFormer: Key-Value Clipping of Transformers on Memristive Crossbars for Write Noise Mitigation
Feb 04, 2024



Transformers have revolutionized various real-world applications from natural language processing to computer vision. However, traditional von-Neumann computing paradigm faces memory and bandwidth limitations in accelerating transformers owing to their massive model sizes. To this end, In-memory Computing (IMC) crossbars based on Non-volatile Memories (NVMs), due to their ability to perform highly parallelized Matrix-Vector-Multiplications (MVMs) with high energy-efficiencies, have emerged as a promising solution for accelerating transformers. However, analog MVM operations in crossbars introduce non-idealities, such as stochastic read & write noise, which affect the inference accuracy of the deployed transformers. Specifically, we find pre-trained Vision Transformers (ViTs) to be vulnerable on crossbars due to the impact of write noise on the dynamically-generated Key (K) and Value (V) matrices in the attention layers, an effect not accounted for in prior studies. We, thus, propose ClipFormer, a transformation on the K and V matrices during inference, to boost the non-ideal accuracies of pre-trained ViT models. ClipFormer requires no additional hardware and training overhead and is amenable to transformers deployed on any memristive crossbar platform. Our experiments on Imagenet-1k dataset using pre-trained DeiT-S transformers, subjected to standard training and variation-aware-training, show >10-40% higher non-ideal accuracies at the high write noise regime by applying ClipFormer.
Are SNNs Truly Energy-efficient? $-$ A Hardware Perspective
Sep 06, 2023



Spiking Neural Networks (SNNs) have gained attention for their energy-efficient machine learning capabilities, utilizing bio-inspired activation functions and sparse binary spike-data representations. While recent SNN algorithmic advances achieve high accuracy on large-scale computer vision tasks, their energy-efficiency claims rely on certain impractical estimation metrics. This work studies two hardware benchmarking platforms for large-scale SNN inference, namely SATA and SpikeSim. SATA is a sparsity-aware systolic-array accelerator, while SpikeSim evaluates SNNs implemented on In-Memory Computing (IMC) based analog crossbars. Using these tools, we find that the actual energy-efficiency improvements of recent SNN algorithmic works differ significantly from their estimated values due to various hardware bottlenecks. We identify and address key roadblocks to efficient SNN deployment on hardware, including repeated computations & data movements over timesteps, neuronal module overhead, and vulnerability of SNNs towards crossbar non-idealities.
Examining the Role and Limits of Batchnorm Optimization to Mitigate Diverse Hardware-noise in In-memory Computing
May 28, 2023In-Memory Computing (IMC) platforms such as analog crossbars are gaining focus as they facilitate the acceleration of low-precision Deep Neural Networks (DNNs) with high area- & compute-efficiencies. However, the intrinsic non-idealities in crossbars, which are often non-deterministic and non-linear, degrade the performance of the deployed DNNs. In addition to quantization errors, most frequently encountered non-idealities during inference include crossbar circuit-level parasitic resistances and device-level non-idealities such as stochastic read noise and temporal drift. In this work, our goal is to closely examine the distortions caused by these non-idealities on the dot-product operations in analog crossbars and explore the feasibility of a nearly training-less solution via crossbar-aware fine-tuning of batchnorm parameters in real-time to mitigate the impact of the non-idealities. This enables reduction in hardware costs in terms of memory and training energy for IMC noise-aware retraining of the DNN weights on crossbars.
* Accepted in Great Lakes Symposium on VLSI 2023 (GLSVLSI 2023) conference
XPert: Peripheral Circuit & Neural Architecture Co-search for Area and Energy-efficient Xbar-based Computing
Mar 30, 2023



The hardware-efficiency and accuracy of Deep Neural Networks (DNNs) implemented on In-memory Computing (IMC) architectures primarily depend on the DNN architecture and the peripheral circuit parameters. It is therefore essential to holistically co-search the network and peripheral parameters to achieve optimal performance. To this end, we propose XPert, which co-searches network architecture in tandem with peripheral parameters such as the type and precision of analog-to-digital converters, crossbar column sharing and the layer-specific input precision using an optimization-based design space exploration. Compared to VGG16 baselines, XPert achieves 10.24x (4.7x) lower EDAP, 1.72x (1.62x) higher TOPS/W,1.93x (3x) higher TOPS/mm2 at 92.46% (56.7%) accuracy for CIFAR10 (TinyImagenet) datasets. The code for this paper is available at https://github.com/Intelligent-Computing-Lab-Yale/XPert.
* Accepted to Design and Automation Conference (DAC)
XploreNAS: Explore Adversarially Robust & Hardware-efficient Neural Architectures for Non-ideal Xbars
Feb 15, 2023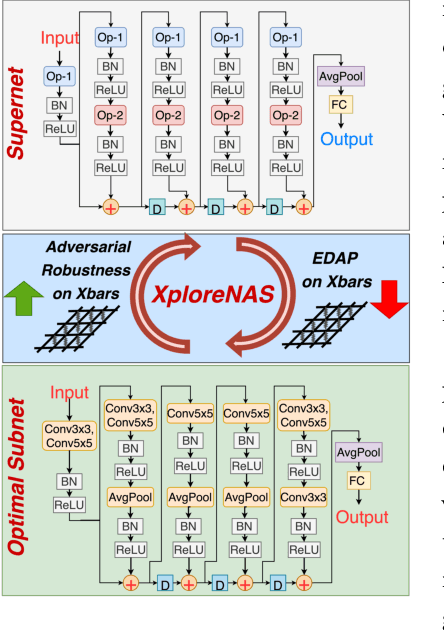
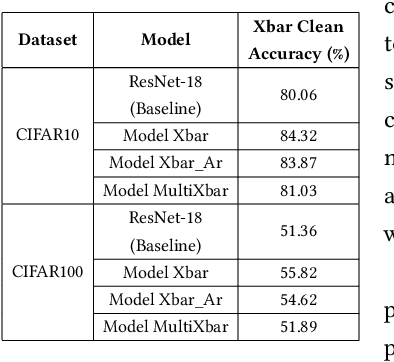
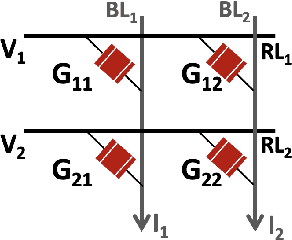
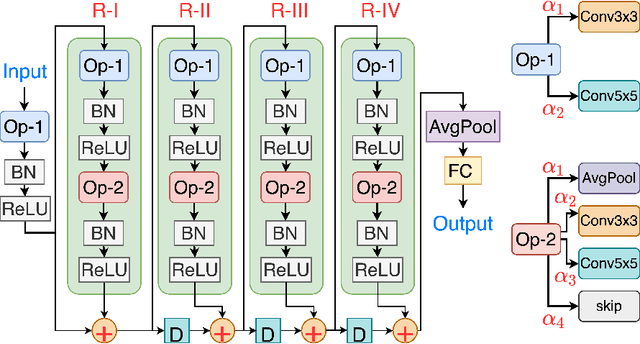
Compute In-Memory platforms such as memristive crossbars are gaining focus as they facilitate acceleration of Deep Neural Networks (DNNs) with high area and compute-efficiencies. However, the intrinsic non-idealities associated with the analog nature of computing in crossbars limits the performance of the deployed DNNs. Furthermore, DNNs are shown to be vulnerable to adversarial attacks leading to severe security threats in their large-scale deployment. Thus, finding adversarially robust DNN architectures for non-ideal crossbars is critical to the safe and secure deployment of DNNs on the edge. This work proposes a two-phase algorithm-hardware co-optimization approach called XploreNAS that searches for hardware-efficient & adversarially robust neural architectures for non-ideal crossbar platforms. We use the one-shot Neural Architecture Search (NAS) approach to train a large Supernet with crossbar-awareness and sample adversarially robust Subnets therefrom, maintaining competitive hardware-efficiency. Our experiments on crossbars with benchmark datasets (SVHN, CIFAR10 & CIFAR100) show upto ~8-16% improvement in the adversarial robustness of the searched Subnets against a baseline ResNet-18 model subjected to crossbar-aware adversarial training. We benchmark our robust Subnets for Energy-Delay-Area-Products (EDAPs) using the Neurosim tool and find that with additional hardware-efficiency driven optimizations, the Subnets attain ~1.5-1.6x lower EDAPs than ResNet-18 baseline.
DeepCAM: A Fully CAM-based Inference Accelerator with Variable Hash Lengths for Energy-efficient Deep Neural Networks
Feb 09, 2023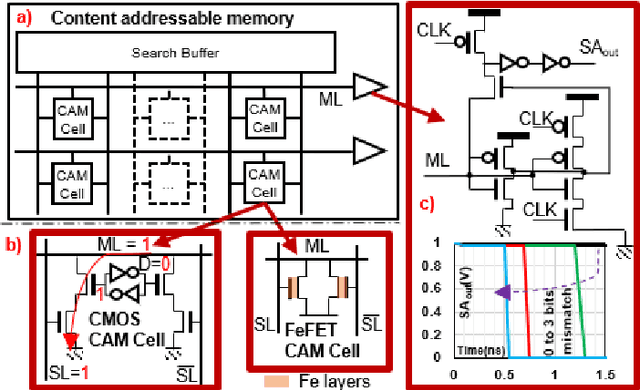
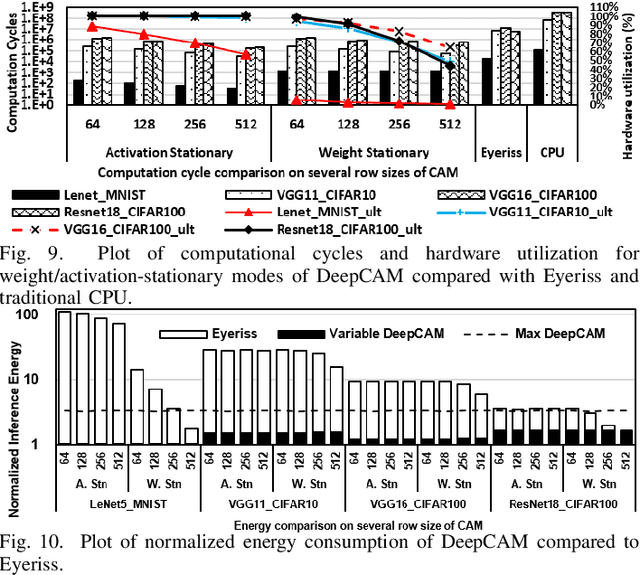
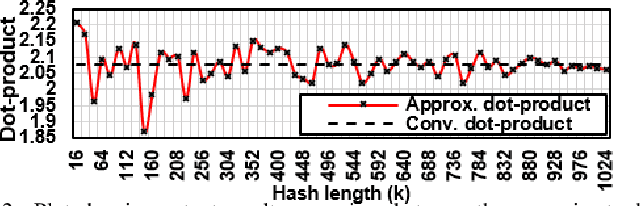
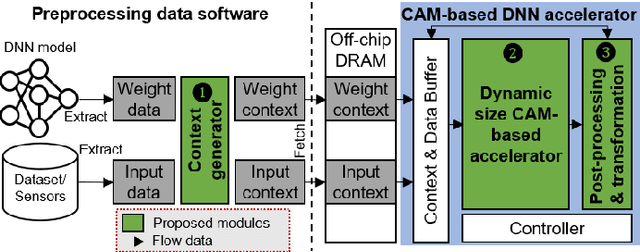
With ever increasing depth and width in deep neural networks to achieve state-of-the-art performance, deep learning computation has significantly grown, and dot-products remain dominant in overall computation time. Most prior works are built on conventional dot-product where weighted input summation is used to represent the neuron operation. However, another implementation of dot-product based on the notion of angles and magnitudes in the Euclidean space has attracted limited attention. This paper proposes DeepCAM, an inference accelerator built on two critical innovations to alleviate the computation time bottleneck of convolutional neural networks. The first innovation is an approximate dot-product built on computations in the Euclidean space that can replace addition and multiplication with simple bit-wise operations. The second innovation is a dynamic size content addressable memory-based (CAM-based) accelerator to perform bit-wise operations and accelerate the CNNs with a lower computation time. Our experiments on benchmark image recognition datasets demonstrate that DeepCAM is up to 523x and 3498x faster than Eyeriss and traditional CPUs like Intel Skylake, respectively. Furthermore, the energy consumed by our DeepCAM approach is 2.16x to 109x less compared to Eyeriss.
* Accepted to Design, Automation and Test in Europe (DATE) Conference, 2023
SpikeSim: An end-to-end Compute-in-Memory Hardware Evaluation Tool for Benchmarking Spiking Neural Networks
Oct 24, 2022SNNs are an active research domain towards energy efficient machine intelligence. Compared to conventional ANNs, SNNs use temporal spike data and bio-plausible neuronal activation functions such as Leaky-Integrate Fire/Integrate Fire (LIF/IF) for data processing. However, SNNs incur significant dot-product operations causing high memory and computation overhead in standard von-Neumann computing platforms. Today, In-Memory Computing (IMC) architectures have been proposed to alleviate the "memory-wall bottleneck" prevalent in von-Neumann architectures. Although recent works have proposed IMC-based SNN hardware accelerators, the following have been overlooked- 1) the adverse effects of crossbar non-ideality on SNN performance due to repeated analog dot-product operations over multiple time-steps, 2) hardware overheads of essential SNN-specific components such as the LIF/IF and data communication modules. To this end, we propose SpikeSim, a tool that can perform realistic performance, energy, latency and area evaluation of IMC-mapped SNNs. SpikeSim consists of a practical monolithic IMC architecture called SpikeFlow for mapping SNNs. Additionally, the non-ideality computation engine (NICE) and energy-latency-area (ELA) engine performs hardware-realistic evaluation of SpikeFlow-mapped SNNs. Based on 65nm CMOS implementation and experiments on CIFAR10, CIFAR100 and TinyImagenet datasets, we find that the LIF/IF neuronal module has significant area contribution (>11% of the total hardware area). We propose SNN topological modifications leading to 1.24x and 10x reduction in the neuronal module's area and the overall energy-delay-product value, respectively. Furthermore, in this work, we perform a holistic comparison between IMC implemented ANN and SNNs and conclude that lower number of time-steps are the key to achieve higher throughput and energy-efficiency for SNNs compared to 4-bit ANNs.