 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeSim: An end-to-end Compute-in-Memory Hardware Evaluation Tool for Benchmarking Spiking Neural Networks
Oct 24, 2022SNNs are an active research domain towards energy efficient machine intelligence. Compared to conventional ANNs, SNNs use temporal spike data and bio-plausible neuronal activation functions such as Leaky-Integrate Fire/Integrate Fire (LIF/IF) for data processing. However, SNNs incur significant dot-product operations causing high memory and computation overhead in standard von-Neumann computing platforms. Today, In-Memory Computing (IMC) architectures have been proposed to alleviate the "memory-wall bottleneck" prevalent in von-Neumann architectures. Although recent works have proposed IMC-based SNN hardware accelerators, the following have been overlooked- 1) the adverse effects of crossbar non-ideality on SNN performance due to repeated analog dot-product operations over multiple time-steps, 2) hardware overheads of essential SNN-specific components such as the LIF/IF and data communication modules. To this end, we propose SpikeSim, a tool that can perform realistic performance, energy, latency and area evaluation of IMC-mapped SNNs. SpikeSim consists of a practical monolithic IMC architecture called SpikeFlow for mapping SNNs. Additionally, the non-ideality computation engine (NICE) and energy-latency-area (ELA) engine performs hardware-realistic evaluation of SpikeFlow-mapped SNNs. Based on 65nm CMOS implementation and experiments on CIFAR10, CIFAR100 and TinyImagenet datasets, we find that the LIF/IF neuronal module has significant area contribution (>11% of the total hardware area). We propose SNN topological modifications leading to 1.24x and 10x reduction in the neuronal module's area and the overall energy-delay-product value, respectively. Furthermore, in this work, we perform a holistic comparison between IMC implemented ANN and SNNs and conclude that lower number of time-steps are the key to achieve higher throughput and energy-efficiency for SNNs compared to 4-bit ANNs.
COIN: Communication-Aware In-Memory Acceleration for Graph Convolutional Networks
May 15, 2022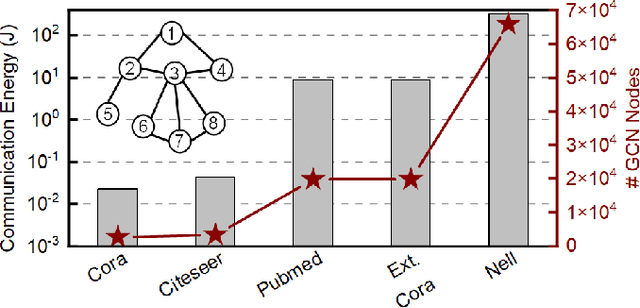
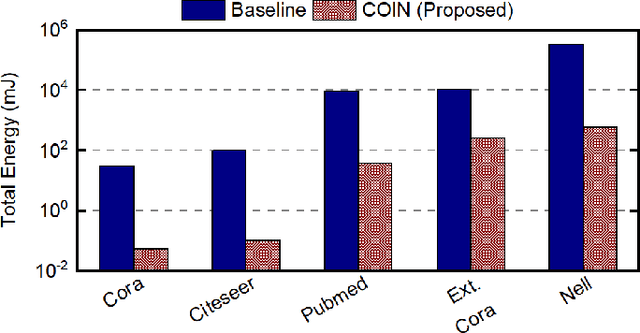
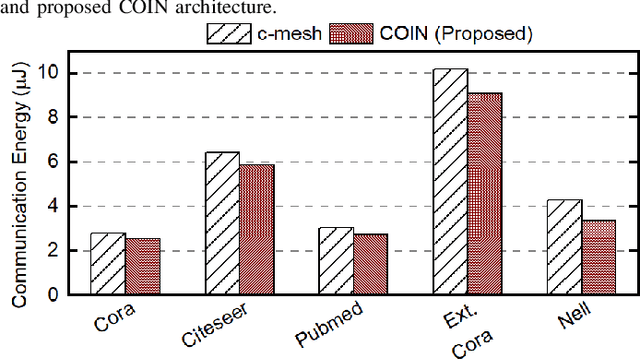
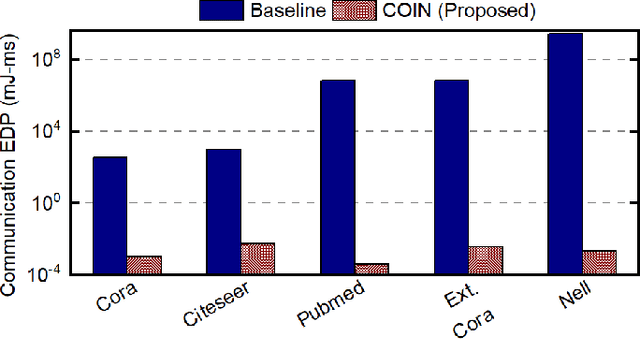
Graph convolutional networks (GCNs) have shown remarkable learning capabilities when processing graph-structured data found inherently in many application areas. GCNs distribute the outputs of neural networks embedded in each vertex over multiple iterations to take advantage of the relations captured by the underlying graphs. Consequently, they incur a significant amount of computation and irregular communication overheads, which call for GCN-specific hardware accelerators. To this end, this paper presents a communication-aware in-memory computing architecture (COIN) for GCN hardware acceleration. Besides accelerating the computation using custom compute elements (CE) and in-memory computing, COIN aims at minimizing the intra- and inter-CE communication in GCN operations to optimize the performance and energy efficiency. Experimental evaluations with widely used datasets show up to 105x improvement in energy consumption compared to state-of-the-art GCN accelerator.
SIAM: Chiplet-based Scalable In-Memory Acceleration with Mesh for Deep Neural Networks
Aug 14, 2021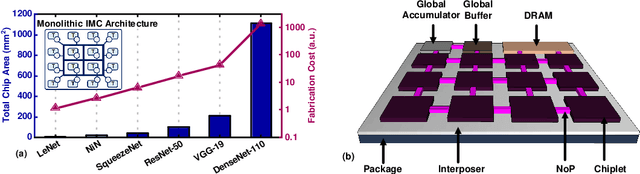
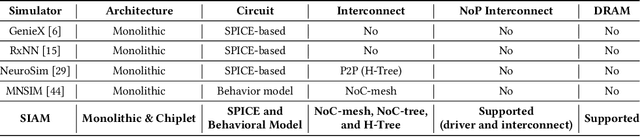
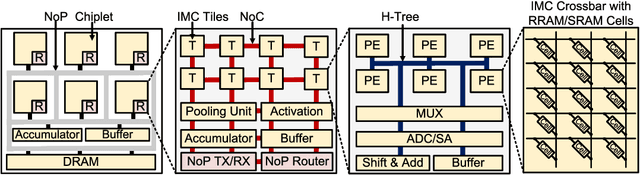
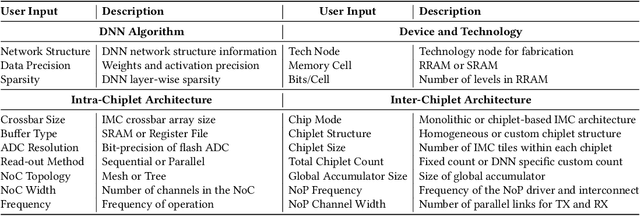
In-memory computing (IMC) on a monolithic chip for deep learning faces dramatic challenges on area, yield, and on-chip interconnection cost due to the ever-increasing model sizes. 2.5D integration or chiplet-based architectures interconnect multiple small chips (i.e., chiplets) to form a large computing system, presenting a feasible solution beyond a monolithic IMC architecture to accelerate large deep learning models. This paper presents a new benchmarking simulator, SIAM, to evaluate the performance of chiplet-based IMC architectures and explore the potential of such a paradigm shift in IMC architecture design. SIAM integrates device, circuit, architecture, network-on-chip (NoC), network-on-package (NoP), and DRAM access models to realize an end-to-end system. SIAM is scalable in its support of a wide range of deep neural networks (DNNs), customizable to various network structures and configurations, and capable of efficient design space exploration. We demonstrate the flexibility, scalability, and simulation speed of SIAM by benchmarking different state-of-the-art DNNs with CIFAR-10, CIFAR-100, and ImageNet datasets. We further calibrate the simulation results with a published silicon result, SIMBA. The chiplet-based IMC architecture obtained through SIAM shows 130$\times$ and 72$\times$ improvement in energy-efficiency for ResNet-50 on the ImageNet dataset compared to Nvidia V100 and T4 GPUs.
Impact of On-Chip Interconnect on In-Memory Acceleration of Deep Neural Networks
Jul 06, 2021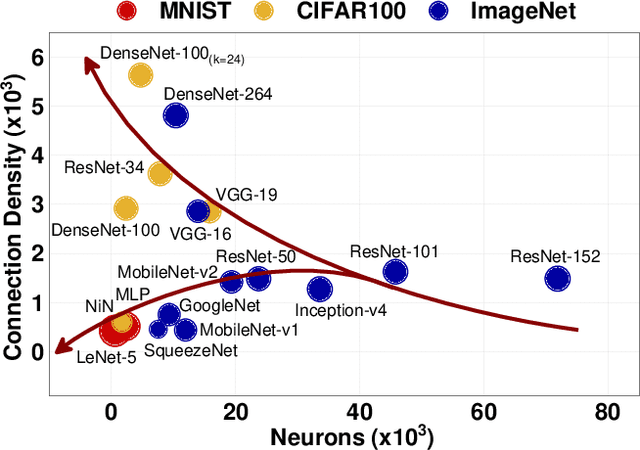
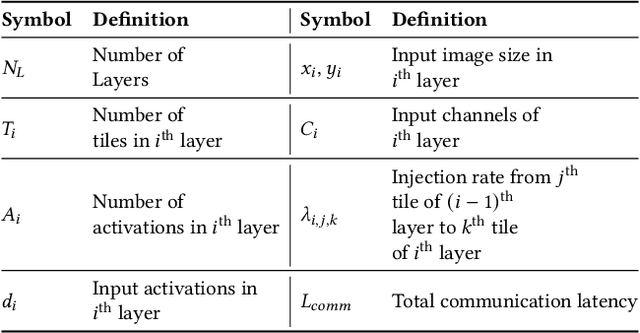
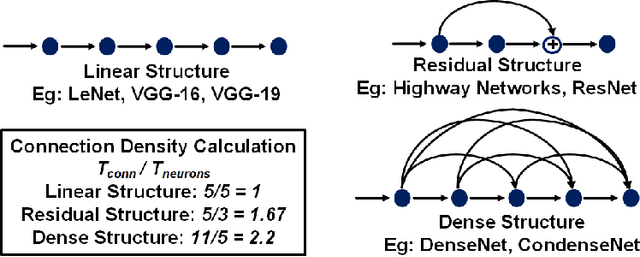

With the widespread use of Deep Neural Networks (DNNs), machine learning algorithms have evolved in two diverse directions -- one with ever-increasing connection density for better accuracy and the other with more compact sizing for energy efficiency. The increase in connection density increases on-chip data movement, which makes efficient on-chip communication a critical function of the DNN accelerator. The contribution of this work is threefold. First, we illustrate that the point-to-point (P2P)-based interconnect is incapable of handling a high volume of on-chip data movement for DNNs. Second, we evaluate P2P and network-on-chip (NoC) interconnect (with a regular topology such as a mesh) for SRAM- and ReRAM-based in-memory computing (IMC) architectures for a range of DNNs. This analysis shows the necessity for the optimal interconnect choice for an IMC DNN accelerator. Finally, we perform an experimental evaluation for different DNNs to empirically obtain the performance of the IMC architecture with both NoC-tree and NoC-mesh. We conclude that, at the tile level, NoC-tree is appropriate for compact DNNs employed at the edge, and NoC-mesh is necessary to accelerate DNNs with high connection density. Furthermore, we propose a technique to determine the optimal choice of interconnect for any given DNN. In this technique, we use analytical models of NoC to evaluate end-to-end communication latency of any given DNN. We demonstrate that the interconnect optimization in the IMC architecture results in up to 6$\times$ improvement in energy-delay-area product for VGG-19 inference compared to the state-of-the-art ReRAM-based IMC architectures.
Structural Pruning in Deep Neural Networks: A Small-World Approach
Nov 11, 2019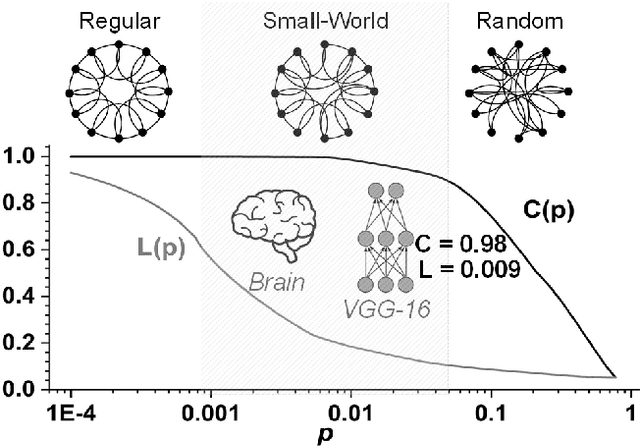

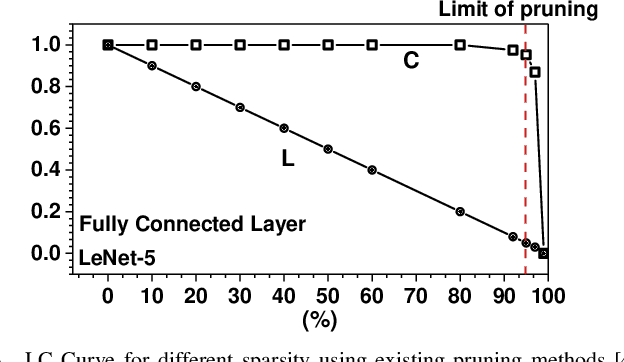
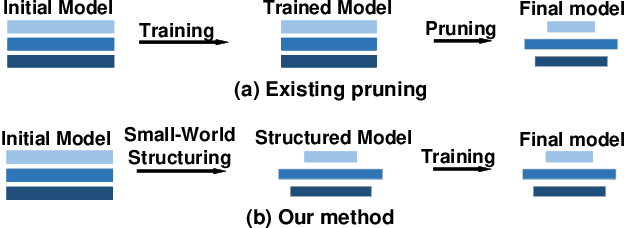
Deep Neural Networks (DNNs) are usually over-parameterized, causing excessive memory and interconnection cost on the hardware platform. Existing pruning approaches remove secondary parameters at the end of training to reduce the model size; but without exploiting the intrinsic network property, they still require the full interconnection to prepare the network. Inspired by the observation that brain networks follow the Small-World model, we propose a novel structural pruning scheme, which includes (1) hierarchically trimming the network into a Small-World model before training, (2) training the network for a given dataset, and (3) optimizing the network for accuracy. The new scheme effectively reduces both the model size and the interconnection needed before training, achieving a locally clustered and globally sparse model. We demonstrate our approach on LeNet-5 for MNIST and VGG-16 for CIFAR-10, decreasing the number of parameters to 2.3% and 9.02% of the baseline model, respectively.