 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeSim: An end-to-end Compute-in-Memory Hardware Evaluation Tool for Benchmarking Spiking Neural Networks
Oct 24, 2022SNNs are an active research domain towards energy efficient machine intelligence. Compared to conventional ANNs, SNNs use temporal spike data and bio-plausible neuronal activation functions such as Leaky-Integrate Fire/Integrate Fire (LIF/IF) for data processing. However, SNNs incur significant dot-product operations causing high memory and computation overhead in standard von-Neumann computing platforms. Today, In-Memory Computing (IMC) architectures have been proposed to alleviate the "memory-wall bottleneck" prevalent in von-Neumann architectures. Although recent works have proposed IMC-based SNN hardware accelerators, the following have been overlooked- 1) the adverse effects of crossbar non-ideality on SNN performance due to repeated analog dot-product operations over multiple time-steps, 2) hardware overheads of essential SNN-specific components such as the LIF/IF and data communication modules. To this end, we propose SpikeSim, a tool that can perform realistic performance, energy, latency and area evaluation of IMC-mapped SNNs. SpikeSim consists of a practical monolithic IMC architecture called SpikeFlow for mapping SNNs. Additionally, the non-ideality computation engine (NICE) and energy-latency-area (ELA) engine performs hardware-realistic evaluation of SpikeFlow-mapped SNNs. Based on 65nm CMOS implementation and experiments on CIFAR10, CIFAR100 and TinyImagenet datasets, we find that the LIF/IF neuronal module has significant area contribution (>11% of the total hardware area). We propose SNN topological modifications leading to 1.24x and 10x reduction in the neuronal module's area and the overall energy-delay-product value, respectively. Furthermore, in this work, we perform a holistic comparison between IMC implemented ANN and SNNs and conclude that lower number of time-steps are the key to achieve higher throughput and energy-efficiency for SNNs compared to 4-bit ANNs.
Split Federated Learning on Micro-controllers: A Keyword Spotting Showcase
Oct 04, 2022

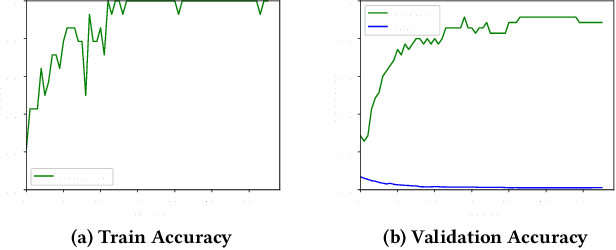
Nowadays, AI companies improve service quality by aggressively collecting users' data generated by edge devices, which jeopardizes data privacy. To prevent this, Federated Learning is proposed as a private learning scheme, using which users can locally train the model without collecting users' raw data to servers. However, for machine-learning applications on edge devices that have hard memory constraints, implementing a large model using FL is infeasible. To meet the memory requirement, a recent collaborative learning scheme named split federal learning is a potential solution since it keeps a small model on the device and keeps the rest of the model on the server. In this work, we implement a simply SFL framework on the Arduino board and verify its correctness on the Chinese digits audio dataset for keyword spotting application with over 90% accuracy. Furthermore, on the English digits audio dataset, our SFL implementation achieves 13.89% higher accuracy compared to a state-of-the-art FL implementation.