 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen In-memory Computing Meets Spiking Neural Networks -- A Perspective on Device-Circuit-System-and-Algorithm Co-design
Aug 22, 2024



This review explores the intersection of bio-plausible artificial intelligence in the form of Spiking Neural Networks (SNNs) with the analog In-Memory Computing (IMC) domain, highlighting their collective potential for low-power edge computing environments. Through detailed investigation at the device, circuit, and system levels, we highlight the pivotal synergies between SNNs and IMC architectures. Additionally, we emphasize the critical need for comprehensive system-level analyses, considering the inter-dependencies between algorithms, devices, circuit & system parameters, crucial for optimal performance. An in-depth analysis leads to identification of key system-level bottlenecks arising from device limitations which can be addressed using SNN-specific algorithm-hardware co-design techniques. This review underscores the imperative for holistic device to system design space co-exploration, highlighting the critical aspects of hardware and algorithm research endeavors for low-power neuromorphic solutions.
TReX- Reusing Vision Transformer's Attention for Efficient Xbar-based Computing
Aug 22, 2024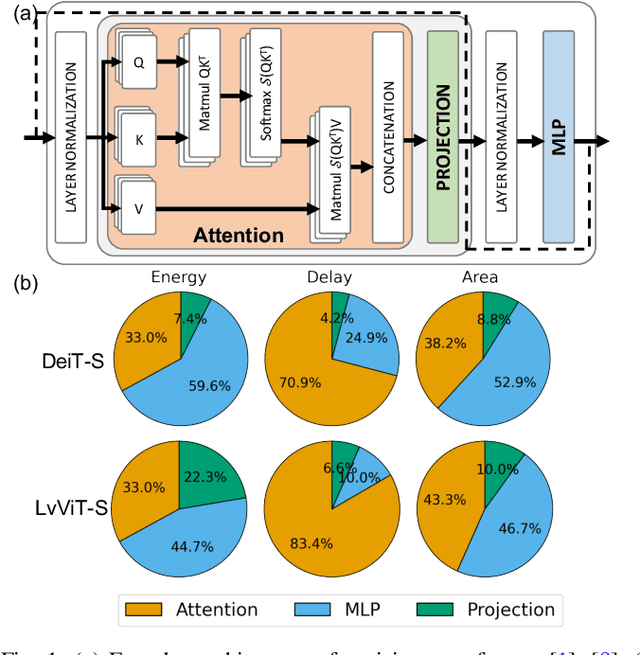
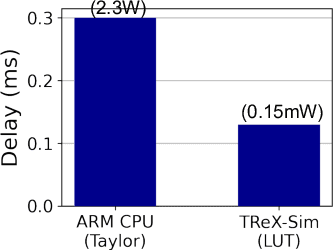
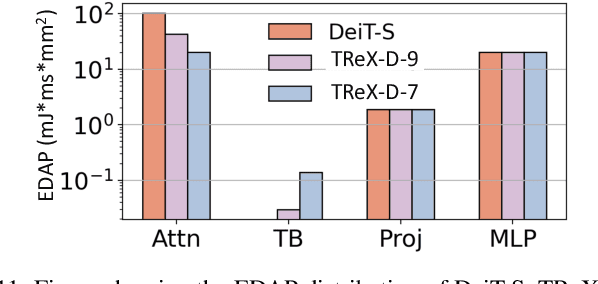
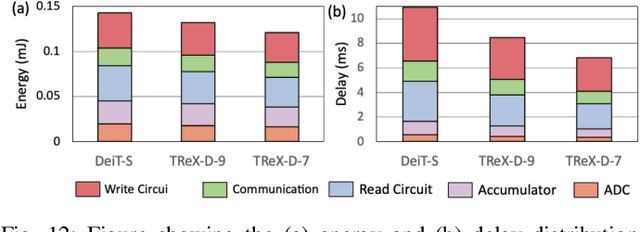
Due to the high computation overhead of Vision Transformers (ViTs), In-memory Computing architectures are being researched towards energy-efficient deployment in edge-computing scenarios. Prior works have proposed efficient algorithm-hardware co-design and IMC-architectural improvements to improve the energy-efficiency of IMC-implemented ViTs. However, all prior works have neglected the overhead and co-depencence of attention blocks on the accuracy-energy-delay-area of IMC-implemented ViTs. To this end, we propose TReX- an attention-reuse-driven ViT optimization framework that effectively performs attention reuse in ViT models to achieve optimal accuracy-energy-delay-area tradeoffs. TReX optimally chooses the transformer encoders for attention reuse to achieve near iso-accuracy performance while meeting the user-specified delay requirement. Based on our analysis on the Imagenet-1k dataset, we find that TReX achieves 2.3x (2.19x) EDAP reduction and 1.86x (1.79x) TOPS/mm2 improvement with ~1% accuracy drop in case of DeiT-S (LV-ViT-S) ViT models. Additionally, TReX achieves high accuracy at high EDAP reduction compared to state-of-the-art token pruning and weight sharing approaches. On NLP tasks such as CoLA, TReX leads to 2% higher non-ideal accuracy compared to baseline at 1.6x lower EDAP.
ClipFormer: Key-Value Clipping of Transformers on Memristive Crossbars for Write Noise Mitigation
Feb 04, 2024



Transformers have revolutionized various real-world applications from natural language processing to computer vision. However, traditional von-Neumann computing paradigm faces memory and bandwidth limitations in accelerating transformers owing to their massive model sizes. To this end, In-memory Computing (IMC) crossbars based on Non-volatile Memories (NVMs), due to their ability to perform highly parallelized Matrix-Vector-Multiplications (MVMs) with high energy-efficiencies, have emerged as a promising solution for accelerating transformers. However, analog MVM operations in crossbars introduce non-idealities, such as stochastic read & write noise, which affect the inference accuracy of the deployed transformers. Specifically, we find pre-trained Vision Transformers (ViTs) to be vulnerable on crossbars due to the impact of write noise on the dynamically-generated Key (K) and Value (V) matrices in the attention layers, an effect not accounted for in prior studies. We, thus, propose ClipFormer, a transformation on the K and V matrices during inference, to boost the non-ideal accuracies of pre-trained ViT models. ClipFormer requires no additional hardware and training overhead and is amenable to transformers deployed on any memristive crossbar platform. Our experiments on Imagenet-1k dataset using pre-trained DeiT-S transformers, subjected to standard training and variation-aware-training, show >10-40% higher non-ideal accuracies at the high write noise regime by applying ClipFormer.
TT-SNN: Tensor Train Decomposition for Efficient Spiking Neural Network Training
Jan 15, 2024
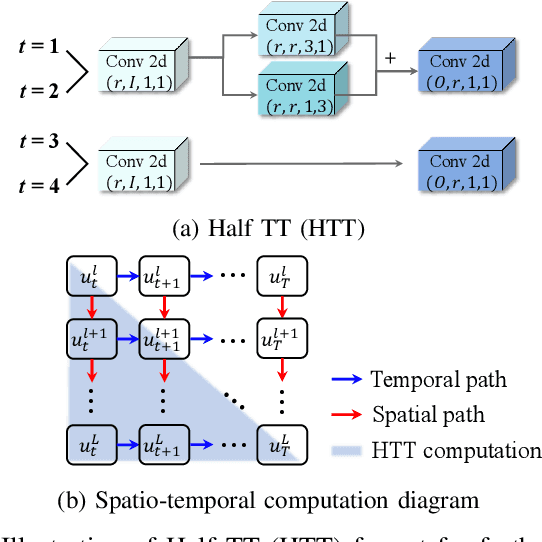


Spiking Neural Networks (SNNs) have gained significant attention as a potentially energy-efficient alternative for standard neural networks with their sparse binary activation. However, SNNs suffer from memory and computation overhead due to spatio-temporal dynamics and multiple backpropagation computations across timesteps during training. To address this issue, we introduce Tensor Train Decomposition for Spiking Neural Networks (TT-SNN), a method that reduces model size through trainable weight decomposition, resulting in reduced storage, FLOPs, and latency. In addition, we propose a parallel computation pipeline as an alternative to the typical sequential tensor computation, which can be flexibly integrated into various existing SNN architectures. To the best of our knowledge, this is the first of its kind application of tensor decomposition in SNNs. We validate our method using both static and dynamic datasets, CIFAR10/100 and N-Caltech101, respectively. We also propose a TT-SNN-tailored training accelerator to fully harness the parallelism in TT-SNN. Our results demonstrate substantial reductions in parameter size (7.98X), FLOPs (9.25X), training time (17.7%), and training energy (28.3%) during training for the N-Caltech101 dataset, with negligible accuracy degradation.
Are SNNs Truly Energy-efficient? $-$ A Hardware Perspective
Sep 06, 2023



Spiking Neural Networks (SNNs) have gained attention for their energy-efficient machine learning capabilities, utilizing bio-inspired activation functions and sparse binary spike-data representations. While recent SNN algorithmic advances achieve high accuracy on large-scale computer vision tasks, their energy-efficiency claims rely on certain impractical estimation metrics. This work studies two hardware benchmarking platforms for large-scale SNN inference, namely SATA and SpikeSim. SATA is a sparsity-aware systolic-array accelerator, while SpikeSim evaluates SNNs implemented on In-Memory Computing (IMC) based analog crossbars. Using these tools, we find that the actual energy-efficiency improvements of recent SNN algorithmic works differ significantly from their estimated values due to various hardware bottlenecks. We identify and address key roadblocks to efficient SNN deployment on hardware, including repeated computations & data movements over timesteps, neuronal module overhead, and vulnerability of SNNs towards crossbar non-idealities.
Examining the Role and Limits of Batchnorm Optimization to Mitigate Diverse Hardware-noise in In-memory Computing
May 28, 2023In-Memory Computing (IMC) platforms such as analog crossbars are gaining focus as they facilitate the acceleration of low-precision Deep Neural Networks (DNNs) with high area- & compute-efficiencies. However, the intrinsic non-idealities in crossbars, which are often non-deterministic and non-linear, degrade the performance of the deployed DNNs. In addition to quantization errors, most frequently encountered non-idealities during inference include crossbar circuit-level parasitic resistances and device-level non-idealities such as stochastic read noise and temporal drift. In this work, our goal is to closely examine the distortions caused by these non-idealities on the dot-product operations in analog crossbars and explore the feasibility of a nearly training-less solution via crossbar-aware fine-tuning of batchnorm parameters in real-time to mitigate the impact of the non-idealities. This enables reduction in hardware costs in terms of memory and training energy for IMC noise-aware retraining of the DNN weights on crossbars.
* Accepted in Great Lakes Symposium on VLSI 2023 (GLSVLSI 2023) conference
Input-Aware Dynamic Timestep Spiking Neural Networks for Efficient In-Memory Computing
May 27, 2023



Spiking Neural Networks (SNNs) have recently attracted widespread research interest as an efficient alternative to traditional Artificial Neural Networks (ANNs) because of their capability to process sparse and binary spike information and avoid expensive multiplication operations. Although the efficiency of SNNs can be realized on the In-Memory Computing (IMC) architecture, we show that the energy cost and latency of SNNs scale linearly with the number of timesteps used on IMC hardware. Therefore, in order to maximize the efficiency of SNNs, we propose input-aware Dynamic Timestep SNN (DT-SNN), a novel algorithmic solution to dynamically determine the number of timesteps during inference on an input-dependent basis. By calculating the entropy of the accumulated output after each timestep, we can compare it to a predefined threshold and decide if the information processed at the current timestep is sufficient for a confident prediction. We deploy DT-SNN on an IMC architecture and show that it incurs negligible computational overhead. We demonstrate that our method only uses 1.46 average timesteps to achieve the accuracy of a 4-timestep static SNN while reducing the energy-delay-product by 80%.
Sharing Leaky-Integrate-and-Fire Neurons for Memory-Efficient Spiking Neural Networks
May 26, 2023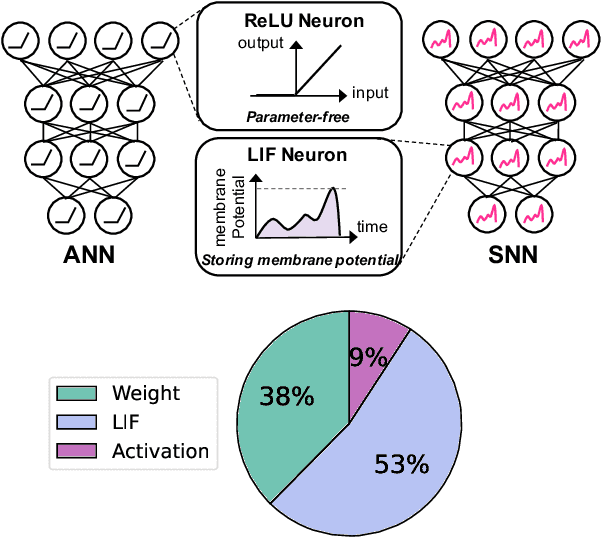



Spiking Neural Networks (SNNs) have gained increasing attention as energy-efficient neural networks owing to their binary and asynchronous computation. However, their non-linear activation, that is Leaky-Integrate-and-Fire (LIF) neuron, requires additional memory to store a membrane voltage to capture the temporal dynamics of spikes. Although the required memory cost for LIF neurons significantly increases as the input dimension goes larger, a technique to reduce memory for LIF neurons has not been explored so far. To address this, we propose a simple and effective solution, EfficientLIF-Net, which shares the LIF neurons across different layers and channels. Our EfficientLIF-Net achieves comparable accuracy with the standard SNNs while bringing up to ~4.3X forward memory efficiency and ~21.9X backward memory efficiency for LIF neurons. We conduct experiments on various datasets including CIFAR10, CIFAR100, TinyImageNet, ImageNet-100, and N-Caltech101. Furthermore, we show that our approach also offers advantages on Human Activity Recognition (HAR) datasets, which heavily rely on temporal information.
Do We Really Need a Large Number of Visual Prompts?
May 26, 2023



Due to increasing interest in adapting models on resource-constrained edges, parameter-efficient transfer learning has been widely explored. Among various methods, Visual Prompt Tuning (VPT), prepending learnable prompts to input space, shows competitive fine-tuning performance compared to training of full network parameters. However, VPT increases the number of input tokens, resulting in additional computational overhead. In this paper, we analyze the impact of the number of prompts on fine-tuning performance and self-attention operation in a vision transformer architecture. Through theoretical and empirical analysis we show that adding more prompts does not lead to linear performance improvement. Further, we propose a Prompt Condensation (PC) technique that aims to prevent performance degradation from using a small number of prompts. We validate our methods on FGVC and VTAB-1k tasks and show that our approach reduces the number of prompts by ~70% while maintaining accuracy.
MINT: Multiplier-less Integer Quantization for Spiking Neural Networks
May 20, 2023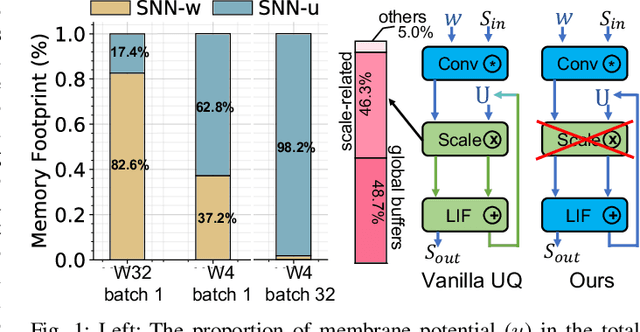
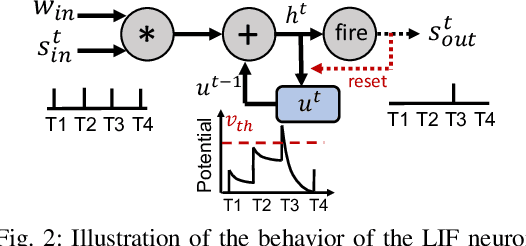
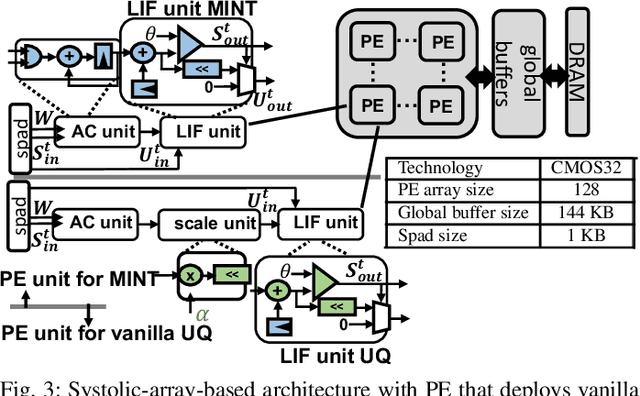
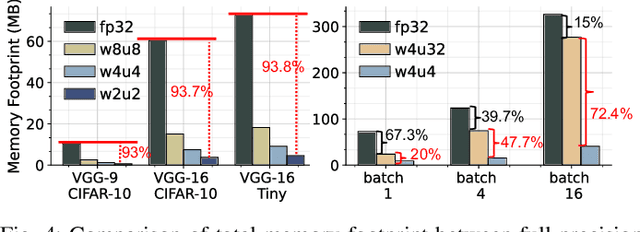
We propose Multiplier-less INTeger (MINT) quantization, an efficient uniform quantization scheme for the weights and membrane potentials in spiking neural networks (SNNs). Unlike prior SNN quantization works, MINT quantizes the memory-hungry membrane potentials to extremely low bit-width (2-bit) to significantly reduce the total memory footprint. Additionally, MINT quantization shares the quantization scale between the weights and membrane potentials, eliminating the need for multipliers and floating arithmetic units, which are required by the standard uniform quantization. Experimental results demonstrate that our proposed method achieves accuracy that matches other state-of-the-art SNN quantization works while outperforming them on total memory footprint and hardware cost at deployment time. For instance, 2-bit MINT VGG-16 achieves 48.6% accuracy on TinyImageNet (0.28% better than the full-precision baseline) with approximately 93.8% reduction in total memory footprint from the full-precision model; meanwhile, our model reduces area by 93% and dynamic power by 98% compared to other SNN quantization counterparts.