 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOIN: Communication-Aware In-Memory Acceleration for Graph Convolutional Networks
May 15, 2022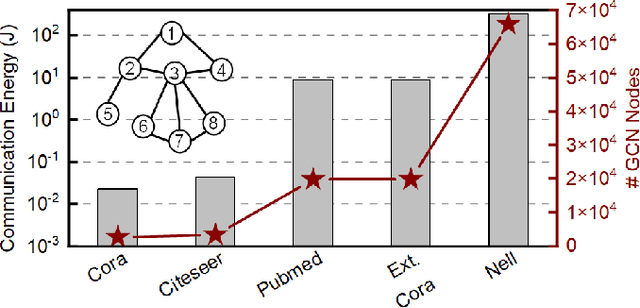
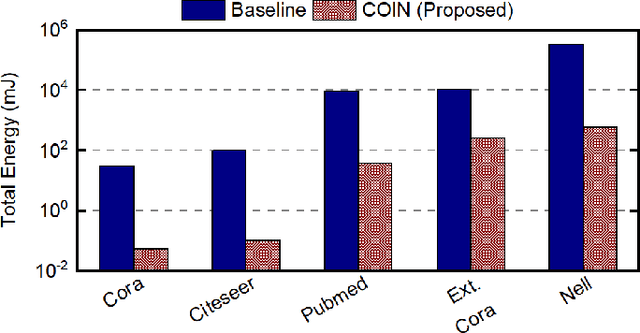
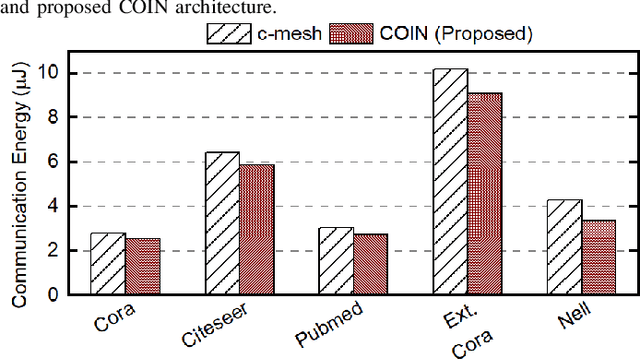
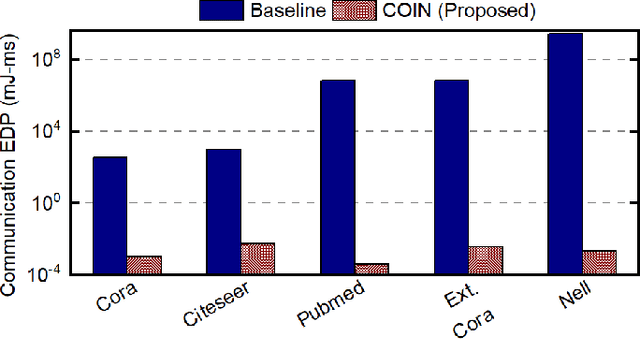
Graph convolutional networks (GCNs) have shown remarkable learning capabilities when processing graph-structured data found inherently in many application areas. GCNs distribute the outputs of neural networks embedded in each vertex over multiple iterations to take advantage of the relations captured by the underlying graphs. Consequently, they incur a significant amount of computation and irregular communication overheads, which call for GCN-specific hardware accelerators. To this end, this paper presents a communication-aware in-memory computing architecture (COIN) for GCN hardware acceleration. Besides accelerating the computation using custom compute elements (CE) and in-memory computing, COIN aims at minimizing the intra- and inter-CE communication in GCN operations to optimize the performance and energy efficiency. Experimental evaluations with widely used datasets show up to 105x improvement in energy consumption compared to state-of-the-art GCN accelerator.