 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Pruning in Deep Neural Networks: A Small-World Approach
Paper and Code
Nov 11, 2019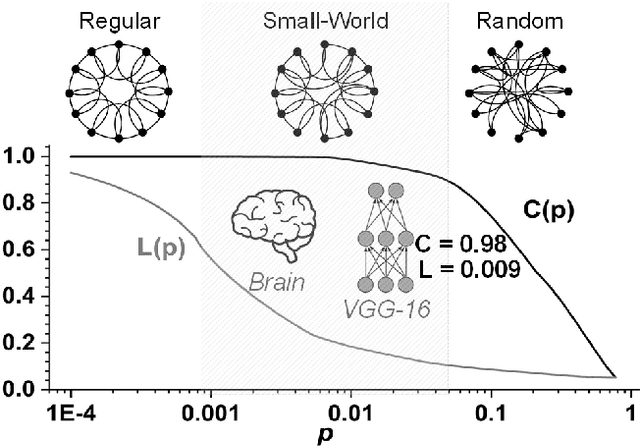

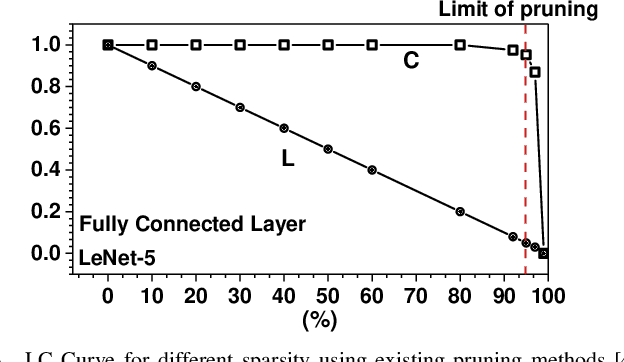
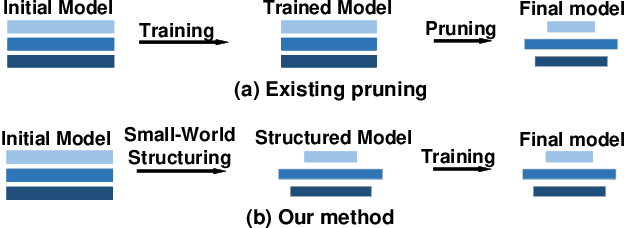
Deep Neural Networks (DNNs) are usually over-parameterized, causing excessive memory and interconnection cost on the hardware platform. Existing pruning approaches remove secondary parameters at the end of training to reduce the model size; but without exploiting the intrinsic network property, they still require the full interconnection to prepare the network. Inspired by the observation that brain networks follow the Small-World model, we propose a novel structural pruning scheme, which includes (1) hierarchically trimming the network into a Small-World model before training, (2) training the network for a given dataset, and (3) optimizing the network for accuracy. The new scheme effectively reduces both the model size and the interconnection needed before training, achieving a locally clustered and globally sparse model. We demonstrate our approach on LeNet-5 for MNIST and VGG-16 for CIFAR-10, decreasing the number of parameters to 2.3% and 9.02% of the baseline model, respectively.