 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Facial Landmark Detection via Cascaded Transformers
Aug 23, 2022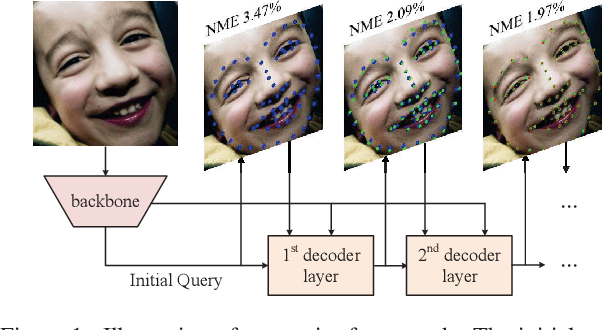
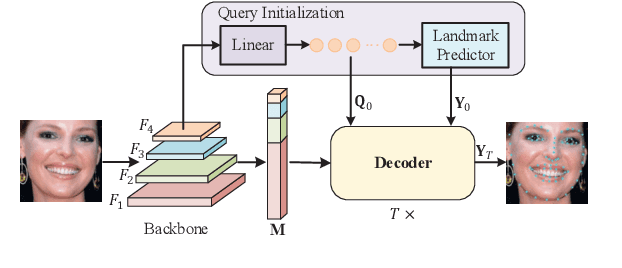

Accurate facial landmarks are essential prerequisites for many tasks related to human faces. In this paper, an accurate facial landmark detector is proposed based on cascaded transformers. We formulate facial landmark detection as a coordinate regression task such that the model can be trained end-to-end. With self-attention in transformers, our model can inherently exploit the structured relationships between landmarks, which would benefit landmark detection under challenging conditions such as large pose and occlusion. During cascaded refinement, our model is able to extract the most relevant image features around the target landmark for coordinate prediction, based on deformable attention mechanism, thus bringing more accurate alignment. In addition, we propose a novel decoder that refines image features and landmark positions simultaneously. With few parameter increasing, the detection performance improves further. Our model achieves new state-of-the-art performance on several standard facial landmark detection benchmarks, and shows good generalization ability in cross-dataset evaluation.
Pushing the Performance Limit of Scene Text Recognizer without Human Annotation
Apr 16, 2022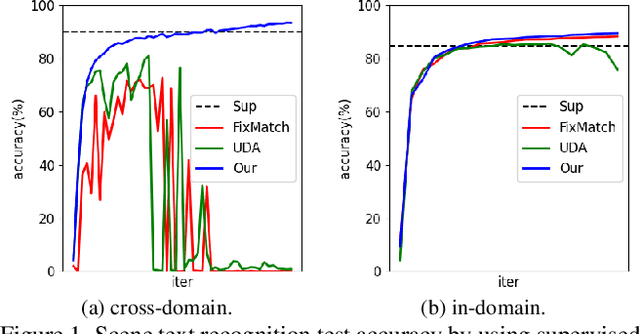
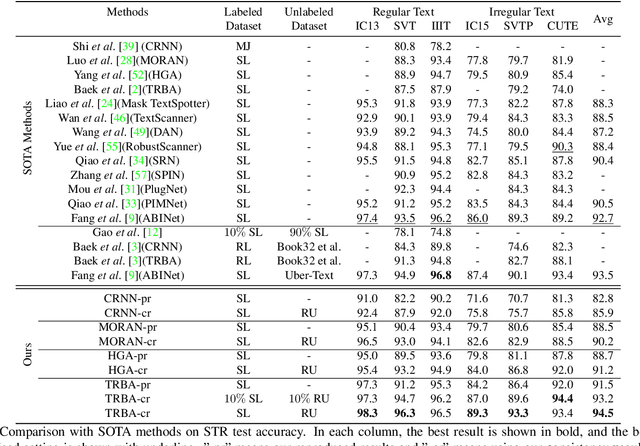
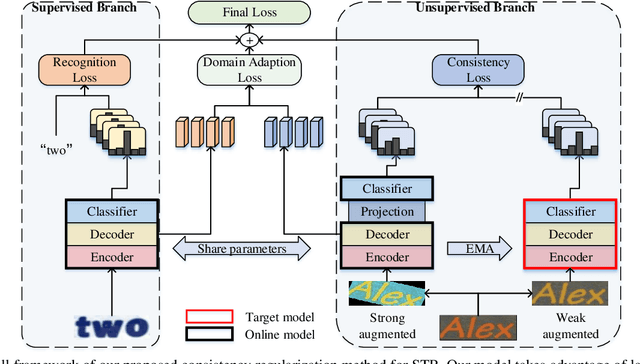
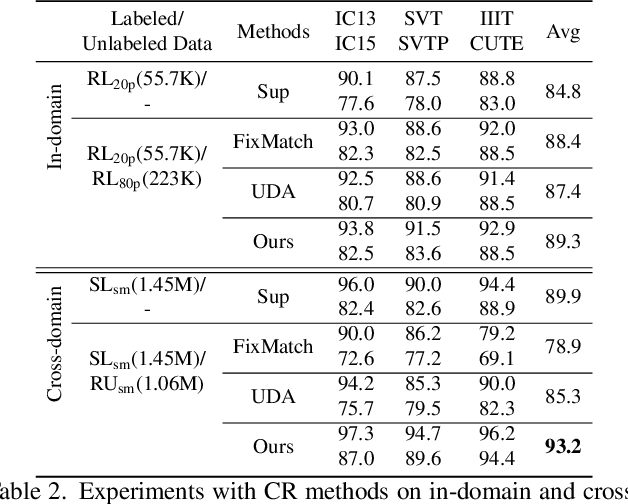
Scene text recognition (STR) attracts much attention over the years because of its wide application. Most methods train STR model in a fully supervised manner which requires large amounts of labeled data. Although synthetic data contributes a lot to STR, it suffers from the real-tosynthetic domain gap that restricts model performance. In this work, we aim to boost STR models by leveraging both synthetic data and the numerous real unlabeled images, exempting human annotation cost thoroughly. A robust consistency regularization based semi-supervised framework is proposed for STR, which can effectively solve the instability issue due to domain inconsistency between synthetic and real images. A character-level consistency regularization is designed to mitigate the misalignment between characters in sequence recognition. Extensive experiments on standard text recognition benchmarks demonstrate the effectiveness of the proposed method. It can steadily improve existing STR models, and boost an STR model to achieve new state-of-the-art results. To our best knowledge, this is the first consistency regularization based framework that applies successfully to STR.
Slot-VPS: Object-centric Representation Learning for Video Panoptic Segmentation
Dec 16, 2021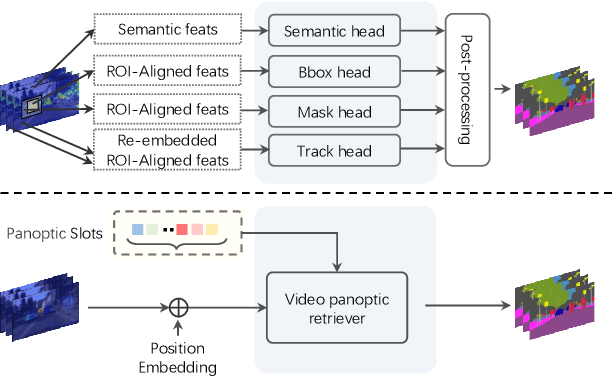
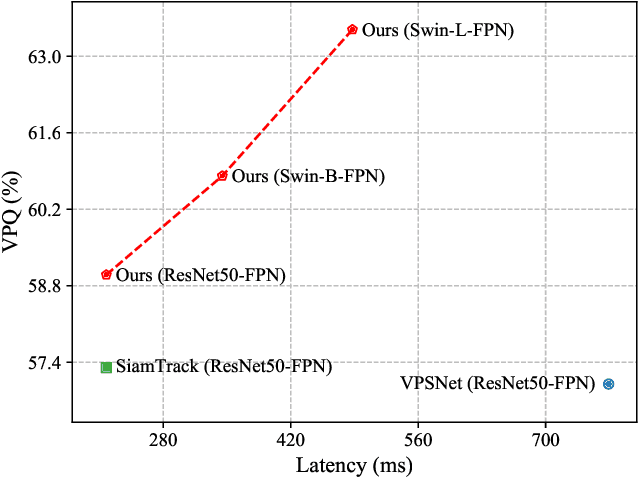
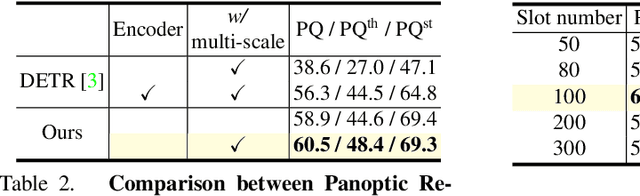
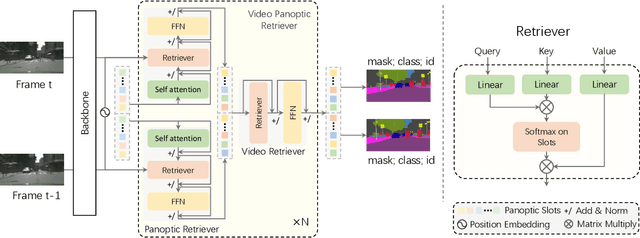
Video Panoptic Segmentation (VPS) aims at assigning a class label to each pixel, uniquely segmenting and identifying all object instances consistently across all frames. Classic solutions usually decompose the VPS task into several sub-tasks and utilize multiple surrogates (e.g. boxes and masks, centres and offsets) to represent objects. However, this divide-and-conquer strategy requires complex post-processing in both spatial and temporal domains and is vulnerable to failures from surrogate tasks. In this paper, inspired by object-centric learning which learns compact and robust object representations, we present Slot-VPS, the first end-to-end framework for this task. We encode all panoptic entities in a video, including both foreground instances and background semantics, with a unified representation called panoptic slots. The coherent spatio-temporal object's information is retrieved and encoded into the panoptic slots by the proposed Video Panoptic Retriever, enabling it to localize, segment, differentiate, and associate objects in a unified manner. Finally, the output panoptic slots can be directly converted into the class, mask, and object ID of panoptic objects in the video. We conduct extensive ablation studies and demonstrate the effectiveness of our approach on two benchmark datasets, Cityscapes-VPS (\textit{val} and test sets) and VIPER (\textit{val} set), achieving new state-of-the-art performance of 63.7, 63.3 and 56.2 VPQ, respectively.
Self-Reorganizing and Rejuvenating CNNs for Increasing Model Capacity Utilization
Feb 13, 2021
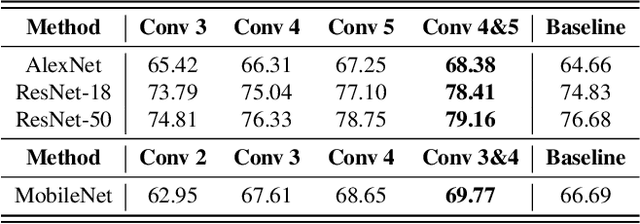


In this paper, we propose self-reorganizing and rejuvenating convolutional neural networks; a biologically inspired method for improving the computational resource utilization of neural networks. The proposed method utilizes the channel activations of a convolution layer in order to reorganize that layers parameters. The reorganized parameters are clustered to avoid parameter redundancies. As such, redundant neurons with similar activations are merged leaving room for the remaining parameters to rejuvenate. The rejuvenated parameters learn different features to supplement those learned by the reorganized surviving parameters. As a result, the network capacity utilization increases improving the baseline network performance without any changes to the network structure. The proposed method can be applied to various network architectures during the training stage, or applied to a pre-trained model improving its performance. Experimental results showed that the proposed method is model-agnostic and can be applied to any backbone architecture increasing its performance due to the elevated utilization of the network capacity.
A Generalized and Robust Method Towards Practical Gaze Estimation on Smart Phone
Oct 16, 2019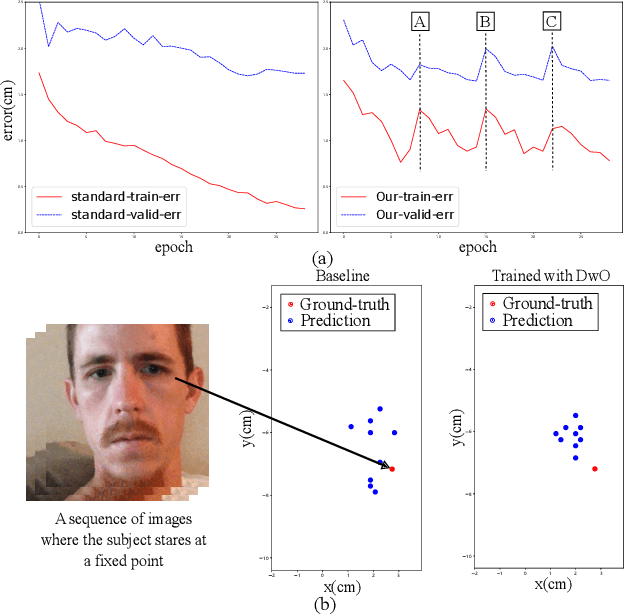
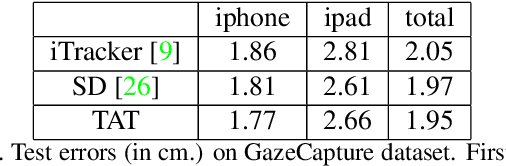
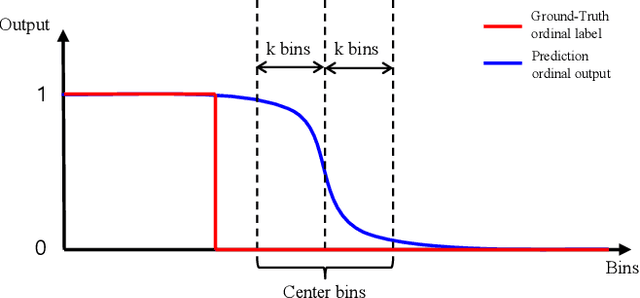
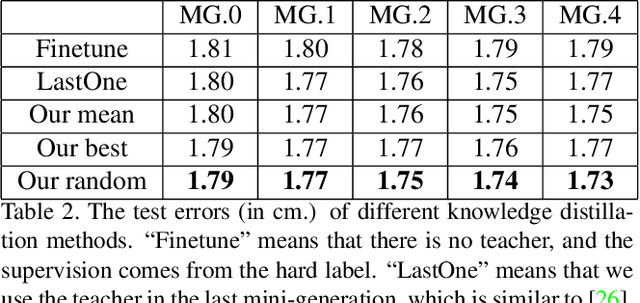
Gaze estimation for ordinary smart phone, e.g. estimating where the user is looking at on the phone screen, can be applied in various applications. However, the widely used appearance-based CNN methods still have two issues for practical adoption. First, due to the limited dataset, gaze estimation is very likely to suffer from over-fitting, leading to poor accuracy at run time. Second, the current methods are usually not robust, i.e. their prediction results having notable jitters even when the user is performing gaze fixation, which degrades user experience greatly. For the first issue, we propose a new tolerant and talented (TAT) training scheme, which is an iterative random knowledge distillation framework enhanced with cosine similarity pruning and aligned orthogonal initialization. The knowledge distillation is a tolerant teaching process providing diverse and informative supervision. The enhanced pruning and initialization is a talented learning process prompting the network to escape from the local minima and re-born from a better start. For the second issue, we define a new metric to measure the robustness of gaze estimator, and propose an adversarial training based Disturbance with Ordinal loss (DwO) method to improve it. The experimental results show that our TAT method achieves state-of-the-art performance on GazeCapture dataset, and that our DwO method improves the robustness while keeping comparable accuracy.
Joint Training of Low-Precision Neural Network with Quantization Interval Parameters
Aug 20, 2018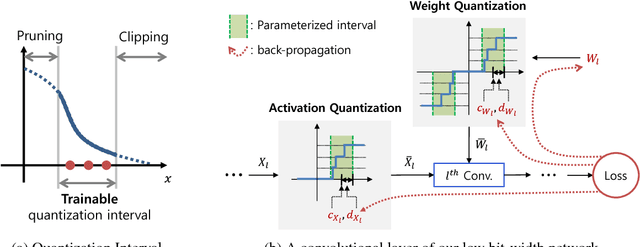
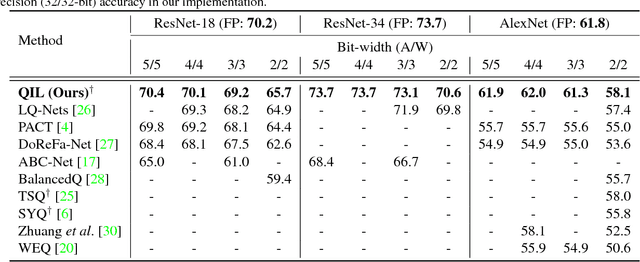
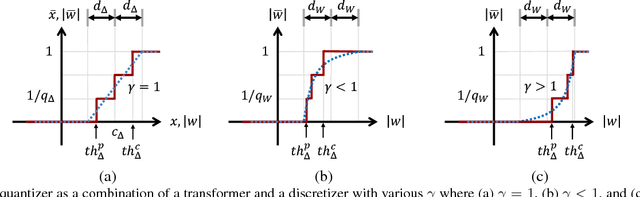
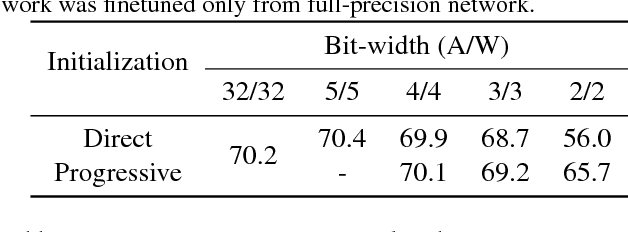
Optimization for low-precision neural network is an important technique for deep convolutional neural network models to be deployed to mobile devices. In order to realize convolutional layers with the simple bit-wise operations, both activation and weight parameters need to be quantized with a low bit-precision. In this paper, we propose a novel optimization method for low-precision neural network which trains both activation quantization parameters and the quantized model weights. We parameterize the quantization intervals of the weights and the activations and train the parameters with the full-precision weights by directly minimizing the training loss rather than minimizing the quantization error. Thanks to the joint optimization of quantization parameters and model weights, we obtain the highly accurate low-precision network given a target bitwidth. We demonstrated the effectiveness of our method on two benchmarks: CIFAR-10 and ImageNet.