 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Facial Landmark Detection via Cascaded Transformers
Paper and Code
Aug 23, 2022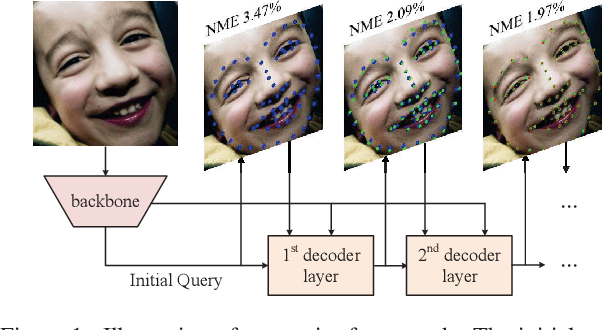
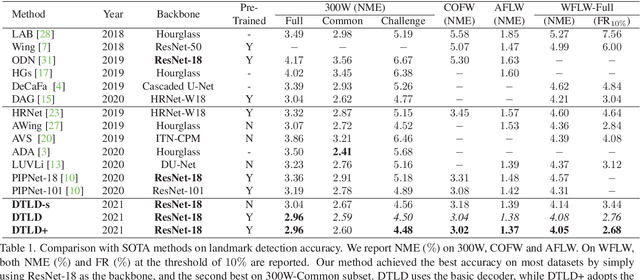
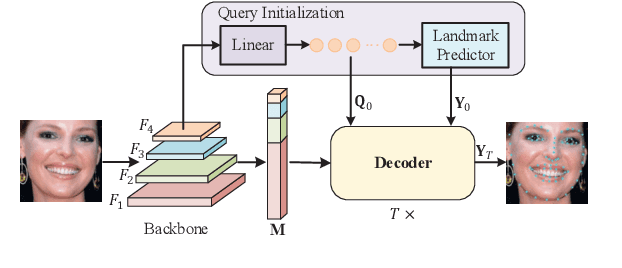

Accurate facial landmarks are essential prerequisites for many tasks related to human faces. In this paper, an accurate facial landmark detector is proposed based on cascaded transformers. We formulate facial landmark detection as a coordinate regression task such that the model can be trained end-to-end. With self-attention in transformers, our model can inherently exploit the structured relationships between landmarks, which would benefit landmark detection under challenging conditions such as large pose and occlusion. During cascaded refinement, our model is able to extract the most relevant image features around the target landmark for coordinate prediction, based on deformable attention mechanism, thus bringing more accurate alignment. In addition, we propose a novel decoder that refines image features and landmark positions simultaneously. With few parameter increasing, the detection performance improves further. Our model achieves new state-of-the-art performance on several standard facial landmark detection benchmarks, and shows good generalization ability in cross-dataset evaluation.