 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Reorganizing and Rejuvenating CNNs for Increasing Model Capacity Utilization
Feb 13, 2021
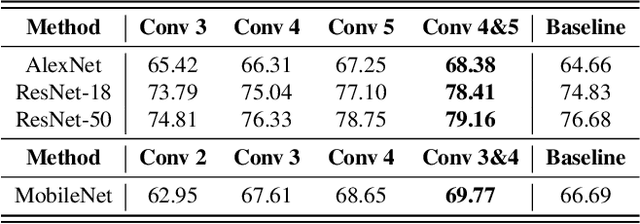


In this paper, we propose self-reorganizing and rejuvenating convolutional neural networks; a biologically inspired method for improving the computational resource utilization of neural networks. The proposed method utilizes the channel activations of a convolution layer in order to reorganize that layers parameters. The reorganized parameters are clustered to avoid parameter redundancies. As such, redundant neurons with similar activations are merged leaving room for the remaining parameters to rejuvenate. The rejuvenated parameters learn different features to supplement those learned by the reorganized surviving parameters. As a result, the network capacity utilization increases improving the baseline network performance without any changes to the network structure. The proposed method can be applied to various network architectures during the training stage, or applied to a pre-trained model improving its performance. Experimental results showed that the proposed method is model-agnostic and can be applied to any backbone architecture increasing its performance due to the elevated utilization of the network capacity.
Mode Variational LSTM Robust to Unseen Modes of Variation: Application to Facial Expression Recognition
Nov 16, 2018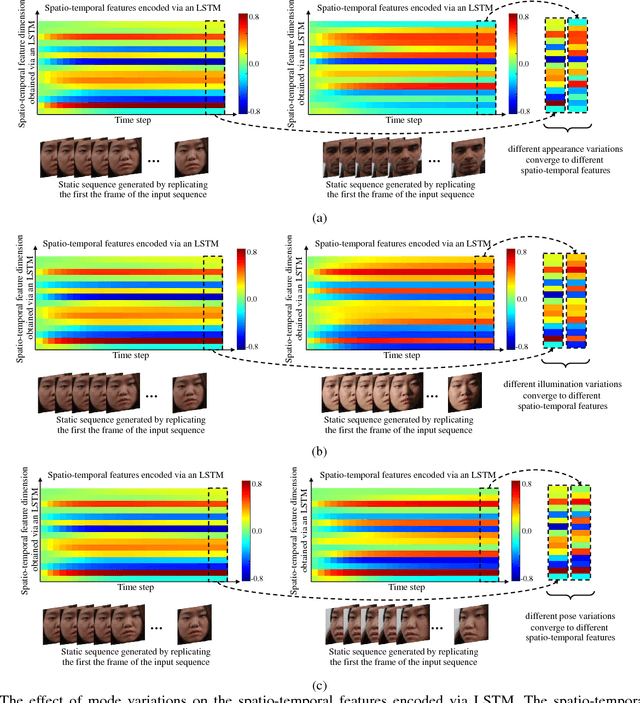



Spatio-temporal feature encoding is essential for encoding the dynamics in video sequences. Recurrent neural networks, particularly long short-term memory (LSTM) units, have been popular as an efficient tool for encoding spatio-temporal features in sequences. In this work, we investigate the effect of mode variations on the encoded spatio-temporal features using LSTMs. We show that the LSTM retains information related to the mode variation in the sequence, which is irrelevant to the task at hand (e.g. classification facial expressions). Actually, the LSTM forget mechanism is not robust enough to mode variations and preserves information that could negatively affect the encoded spatio-temporal features. We propose the mode variational LSTM to encode spatio-temporal features robust to unseen modes of variation. The mode variational LSTM modifies the original LSTM structure by adding an additional cell state that focuses on encoding the mode variation in the input sequence. To efficiently regulate what features should be stored in the additional cell state, additional gating functionality is also introduced. The effectiveness of the proposed mode variational LSTM is verified using the facial expression recognition task. Comparative experiments on publicly available datasets verified that the proposed mode variational LSTM outperforms existing methods. Moreover, a new dynamic facial expression dataset with different modes of variation, including various modes like pose and illumination variations, was collected to comprehensively evaluate the proposed mode variational LSTM. Experimental results verified that the proposed mode variational LSTM encodes spatio-temporal features robust to unseen modes of variation.
Measurement of exceptional motion in VR video contents for VR sickness assessment using deep convolutional autoencoder
Apr 11, 2018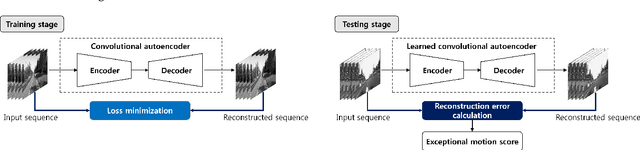
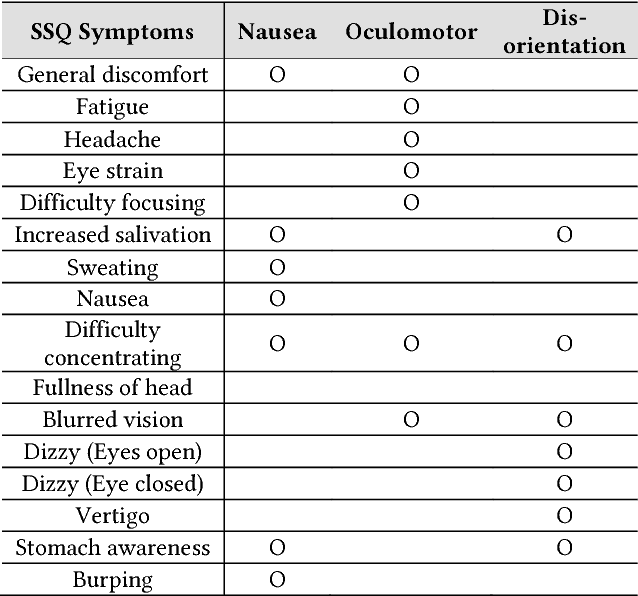
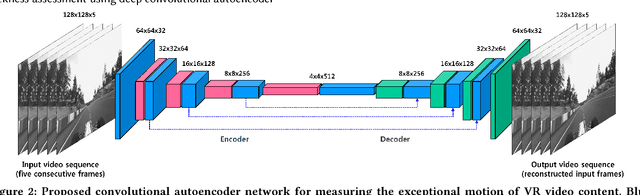

This paper proposes a new objective metric of exceptional motion in VR video contents for VR sickness assessment. In VR environment, VR sickness can be caused by several factors which are mismatched motion, field of view, motion parallax, viewing angle, etc. Similar to motion sickness, VR sickness can induce a lot of physical symptoms such as general discomfort, headache, stomach awareness, nausea, vomiting, fatigue, and disorientation. To address the viewing safety issues in virtual environment, it is of great importance to develop an objective VR sickness assessment method that predicts and analyses the degree of VR sickness induced by the VR content. The proposed method takes into account motion information that is one of the most important factors in determining the overall degree of VR sickness. In this paper, we detect the exceptional motion that is likely to induce VR sickness. Spatio-temporal features of the exceptional motion in the VR video content are encoded using a convolutional autoencoder. For objectively assessing the VR sickness, the level of exceptional motion in VR video content is measured by using the convolutional autoencoder as well. The effectiveness of the proposed method has been successfully evaluated by subjective assessment experiment using simulator sickness questionnaires (SSQ) in VR environment.
Differential Generative Adversarial Networks: Synthesizing Non-linear Facial Variations with Limited Number of Training Data
Dec 29, 2017
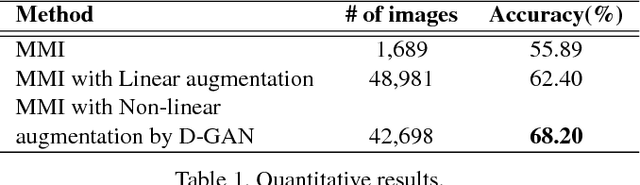


In face-related applications with a public available dataset, synthesizing non-linear facial variations (e.g., facial expression, head-pose, illumination, etc.) through a generative model is helpful in addressing the lack of training data. In reality, however, there is insufficient data to even train the generative model for face synthesis. In this paper, we propose Differential Generative Adversarial Networks (D-GAN) that can perform photo-realistic face synthesis even when training data is small. Two discriminators are devised to ensure the generator to approximate a face manifold, which can express face changes as it wants. Experimental results demonstrate that the proposed method is robust to the amount of training data and synthesized images are useful to improve the performance of a face expression classifier.
Dynamics Transfer GAN: Generating Video by Transferring Arbitrary Temporal Dynamics from a Source Video to a Single Target Image
Dec 10, 2017



In this paper, we propose Dynamics Transfer GAN; a new method for generating video sequences based on generative adversarial learning. The spatial constructs of a generated video sequence are acquired from the target image. The dynamics of the generated video sequence are imported from a source video sequence, with arbitrary motion, and imposed onto the target image. To preserve the spatial construct of the target image, the appearance of the source video sequence is suppressed and only the dynamics are obtained before being imposed onto the target image. That is achieved using the proposed appearance suppressed dynamics feature. Moreover, the spatial and temporal consistencies of the generated video sequence are verified via two discriminator networks. One discriminator validates the fidelity of the generated frames appearance, while the other validates the dynamic consistency of the generated video sequence. Experiments have been conducted to verify the quality of the video sequences generated by the proposed method. The results verified that Dynamics Transfer GAN successfully transferred arbitrary dynamics of the source video sequence onto a target image when generating the output video sequence. The experimental results also showed that Dynamics Transfer GAN maintained the spatial constructs (appearance) of the target image while generating spatially and temporally consistent video sequences.
Learning Spatio-temporal Features with Partial Expression Sequences for on-the-Fly Prediction
Nov 29, 2017



Spatio-temporal feature encoding is essential for encoding facial expression dynamics in video sequences. At test time, most spatio-temporal encoding methods assume that a temporally segmented sequence is fed to a learned model, which could require the prediction to wait until the full sequence is available to an auxiliary task that performs the temporal segmentation. This causes a delay in predicting the expression. In an interactive setting, such as affective interactive agents, such delay in the prediction could not be tolerated. Therefore, training a model that can accurately predict the facial expression "on-the-fly" (as they are fed to the system) is essential. In this paper, we propose a new spatio-temporal feature learning method, which would allow prediction with partial sequences. As such, the prediction could be performed on-the-fly. The proposed method utilizes an estimated expression intensity to generate dense labels, which are used to regulate the prediction model training with a novel objective function. As results, the learned spatio-temporal features can robustly predict the expression with partial (incomplete) expression sequences, on-the-fly. Experimental results showed that the proposed method achieved higher recognition rates compared to the state-of-the-art methods on both datasets. More importantly, the results verified that the proposed method improved the prediction frames with partial expression sequence inputs.
Convolution with Logarithmic Filter Groups for Efficient Shallow CNN
Sep 14, 2017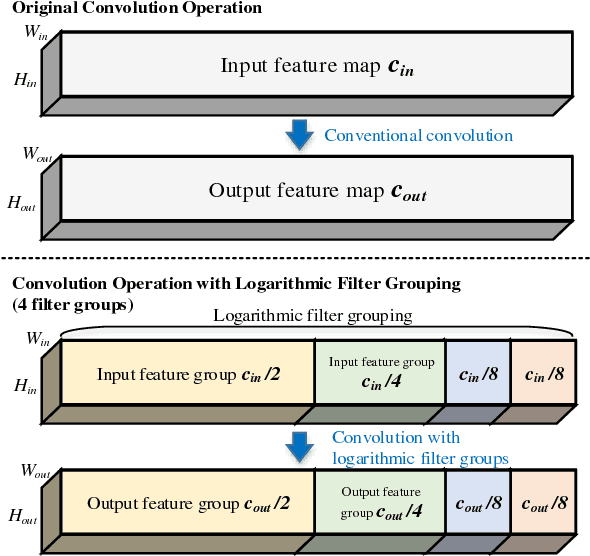


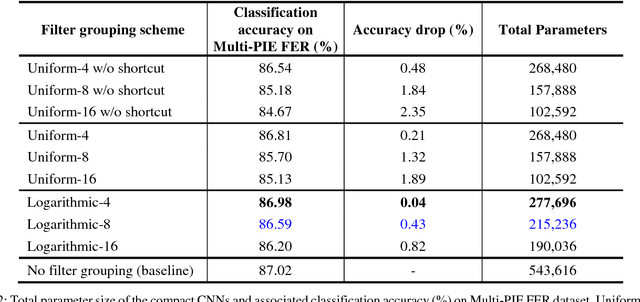
In convolutional neural networks (CNNs), the filter grouping in convolution layers is known to be useful to reduce the network parameter size. In this paper, we propose a new logarithmic filter grouping which can capture the nonlinearity of filter distribution in CNNs. The proposed logarithmic filter grouping is installed in shallow CNNs applicable in a mobile application. Experiments were performed with the shallow CNNs for classification tasks. Our classification results on Multi-PIE dataset for facial expression recognition and CIFAR-10 dataset for object classification reveal that the compact CNN with the proposed logarithmic filter grouping scheme outperforms the same network with the uniform filter grouping in terms of accuracy and parameter efficiency. Our results indicate that the efficiency of shallow CNNs can be improved by the proposed logarithmic filter grouping.