 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Performance Limit of Scene Text Recognizer without Human Annotation
Paper and Code
Apr 16, 2022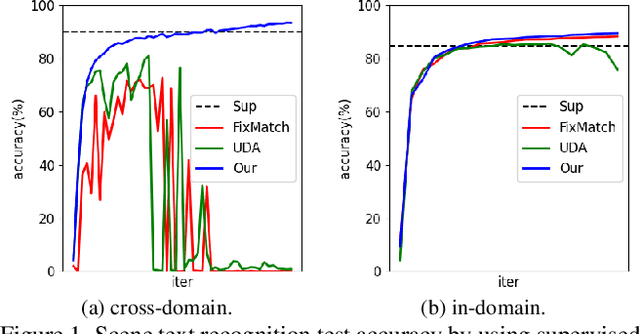
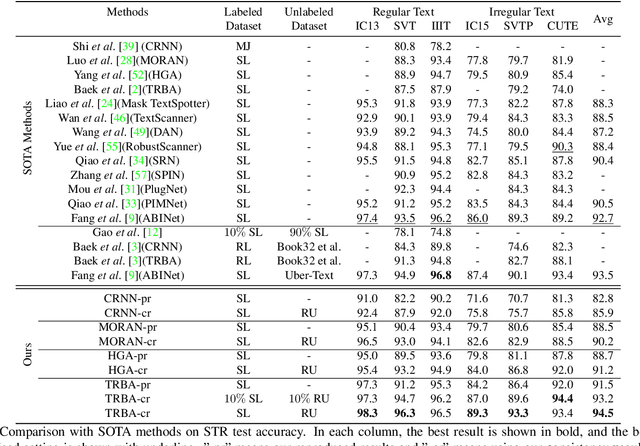
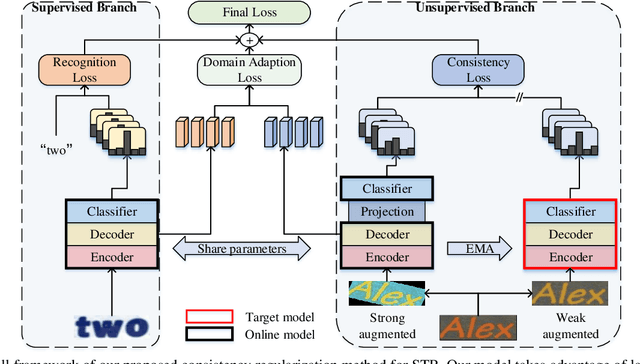
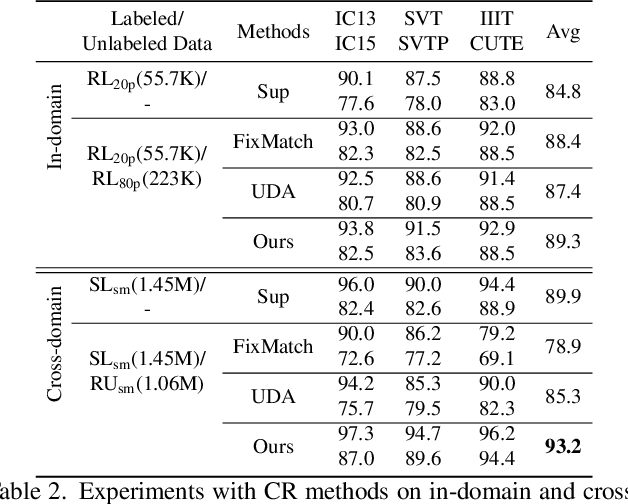
Scene text recognition (STR) attracts much attention over the years because of its wide application. Most methods train STR model in a fully supervised manner which requires large amounts of labeled data. Although synthetic data contributes a lot to STR, it suffers from the real-tosynthetic domain gap that restricts model performance. In this work, we aim to boost STR models by leveraging both synthetic data and the numerous real unlabeled images, exempting human annotation cost thoroughly. A robust consistency regularization based semi-supervised framework is proposed for STR, which can effectively solve the instability issue due to domain inconsistency between synthetic and real images. A character-level consistency regularization is designed to mitigate the misalignment between characters in sequence recognition. Extensive experiments on standard text recognition benchmarks demonstrate the effectiveness of the proposed method. It can steadily improve existing STR models, and boost an STR model to achieve new state-of-the-art results. To our best knowledge, this is the first consistency regularization based framework that applies successfully to STR.