 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMAD: Advancing E2E Driving with Anchored Offset Proposals and Simulation-Supervised Multi-target Scoring
May 29, 2025End-to-end autonomous driving faces persistent challenges in both generating diverse, rule-compliant trajectories and robustly selecting the optimal path from these options via learned, multi-faceted evaluation. To address these challenges, we introduce HMAD, a framework integrating a distinctive Bird's-Eye-View (BEV) based trajectory proposal mechanism with learned multi-criteria scoring. HMAD leverages BEVFormer and employs learnable anchored queries, initialized from a trajectory dictionary and refined via iterative offset decoding (inspired by DiffusionDrive), to produce numerous diverse and stable candidate trajectories. A key innovation, our simulation-supervised scorer module, then evaluates these proposals against critical metrics including no at-fault collisions, drivable area compliance, comfortableness, and overall driving quality (i.e., extended PDM score). Demonstrating its efficacy, HMAD achieves a 44.5% driving score on the CVPR 2025 private test set. This work highlights the benefits of effectively decoupling robust trajectory generation from comprehensive, safety-aware learned scoring for advanced autonomous driving.
Slot-VPS: Object-centric Representation Learning for Video Panoptic Segmentation
Dec 16, 2021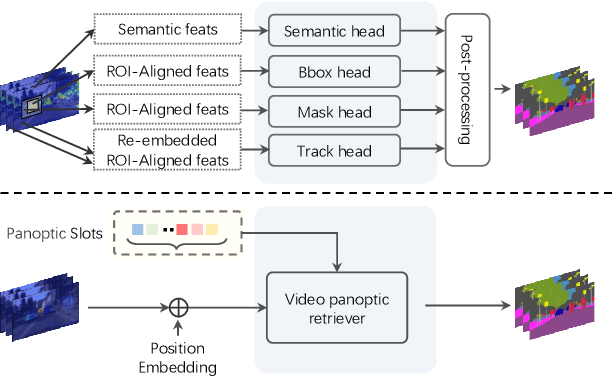
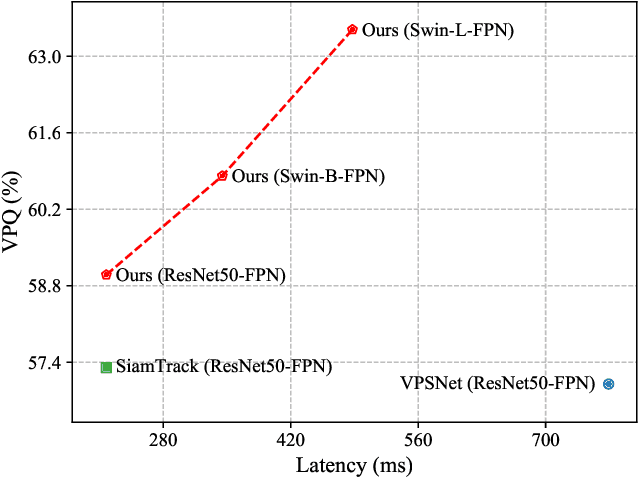
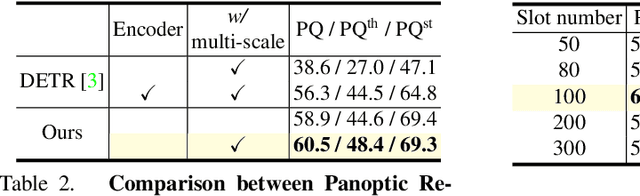
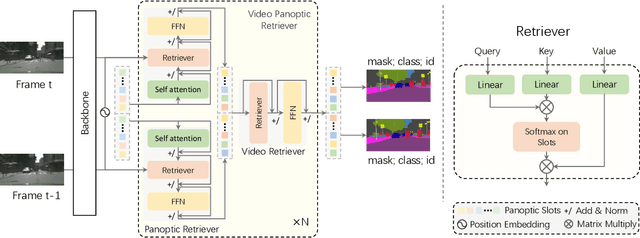
Video Panoptic Segmentation (VPS) aims at assigning a class label to each pixel, uniquely segmenting and identifying all object instances consistently across all frames. Classic solutions usually decompose the VPS task into several sub-tasks and utilize multiple surrogates (e.g. boxes and masks, centres and offsets) to represent objects. However, this divide-and-conquer strategy requires complex post-processing in both spatial and temporal domains and is vulnerable to failures from surrogate tasks. In this paper, inspired by object-centric learning which learns compact and robust object representations, we present Slot-VPS, the first end-to-end framework for this task. We encode all panoptic entities in a video, including both foreground instances and background semantics, with a unified representation called panoptic slots. The coherent spatio-temporal object's information is retrieved and encoded into the panoptic slots by the proposed Video Panoptic Retriever, enabling it to localize, segment, differentiate, and associate objects in a unified manner. Finally, the output panoptic slots can be directly converted into the class, mask, and object ID of panoptic objects in the video. We conduct extensive ablation studies and demonstrate the effectiveness of our approach on two benchmark datasets, Cityscapes-VPS (\textit{val} and test sets) and VIPER (\textit{val} set), achieving new state-of-the-art performance of 63.7, 63.3 and 56.2 VPQ, respectively.