 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMI: Exploration with Mutual Information Maximizing State and Action Embeddings
Paper and Code
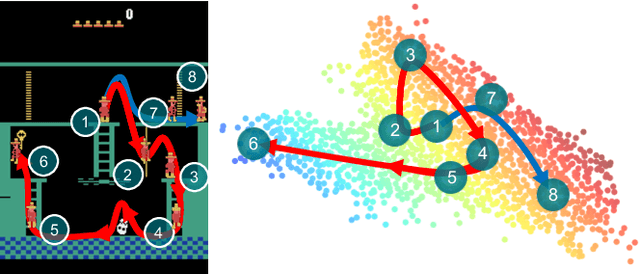
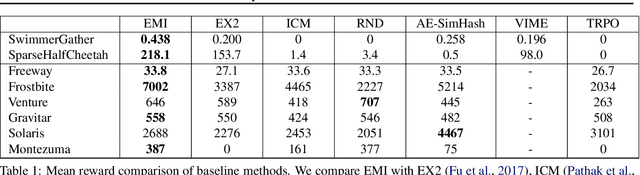
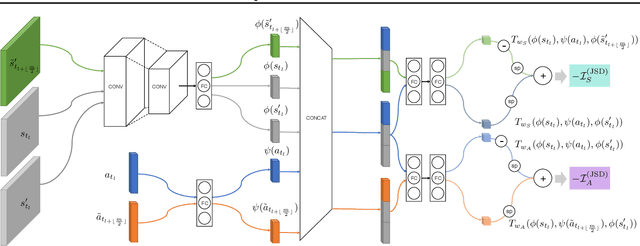
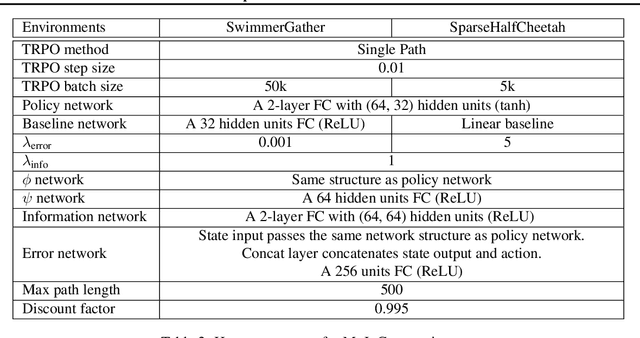
Policy optimization struggles when the reward feedback signal is very sparse and essentially becomes a random search algorithm until the agent accidentally stumbles upon a rewarding or the goal state. Recent works utilize intrinsic motivation to guide the exploration via generative models, predictive forward models, or more ad-hoc measures of surprise. We propose EMI, which is an exploration method that constructs embedding representation of states and actions that does not rely on generative decoding of the full observation but extracts predictive signals that can be used to guide exploration based on forward prediction in the representation space. Our experiments show the state of the art performance on challenging locomotion task with continuous control and on image-based exploration tasks with discrete actions on Atari.