 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient end-to-end learning for quantizable representations
Paper and Code
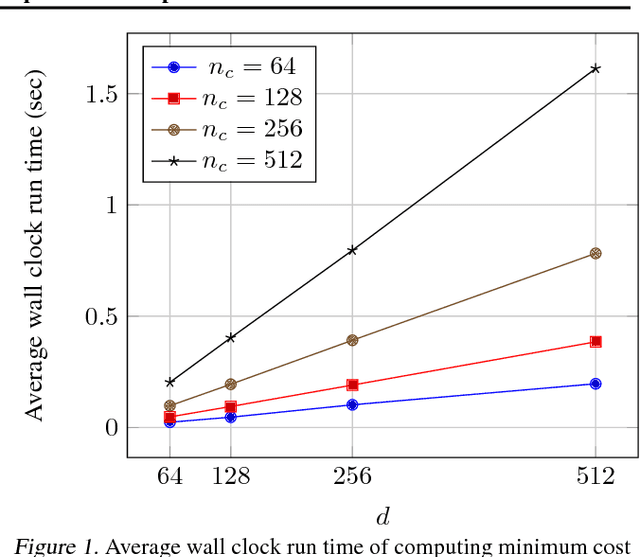

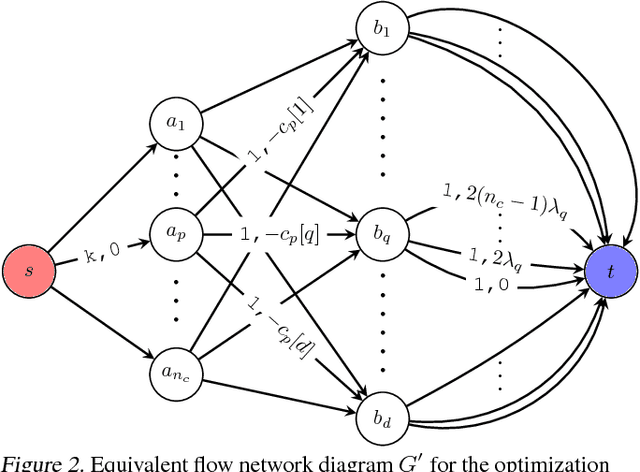

Embedding representation learning via neural networks is at the core foundation of modern similarity based search. While much effort has been put in developing algorithms for learning binary hamming code representations for search efficiency, this still requires a linear scan of the entire dataset per each query and trades off the search accuracy through binarization. To this end, we consider the problem of directly learning a quantizable embedding representation and the sparse binary hash code end-to-end which can be used to construct an efficient hash table not only providing significant search reduction in the number of data but also achieving the state of the art search accuracy outperforming previous state of the art deep metric learning methods. We also show that finding the optimal sparse binary hash code in a mini-batch can be computed exactly in polynomial time by solving a minimum cost flow problem. Our results on Cifar-100 and on ImageNet datasets show the state of the art search accuracy in precision@k and NMI metrics while providing up to 98X and 478X search speedup respectively over exhaustive linear search. The source code is available at https://github.com/maestrojeong/Deep-Hash-Table-ICML18