 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluencing Towards Stable Multi-Agent Interactions
Oct 05, 2021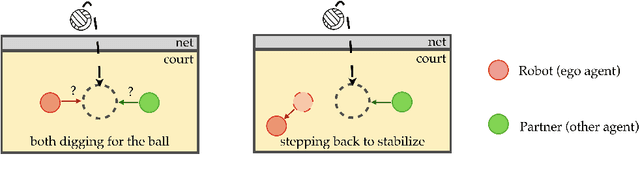


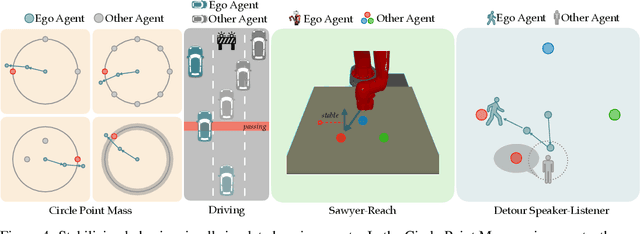
Learning in multi-agent environments is difficult due to the non-stationarity introduced by an opponent's or partner's changing behaviors. Instead of reactively adapting to the other agent's (opponent or partner) behavior, we propose an algorithm to proactively influence the other agent's strategy to stabilize -- which can restrain the non-stationarity caused by the other agent. We learn a low-dimensional latent representation of the other agent's strategy and the dynamics of how the latent strategy evolves with respect to our robot's behavior. With this learned dynamics model, we can define an unsupervised stability reward to train our robot to deliberately influence the other agent to stabilize towards a single strategy. We demonstrate the effectiveness of stabilizing in improving efficiency of maximizing the task reward in a variety of simulated environments, including autonomous driving, emergent communication, and robotic manipulation. We show qualitative results on our website: https://sites.google.com/view/stable-marl/.
Emergent Prosociality in Multi-Agent Games Through Gifting
May 13, 2021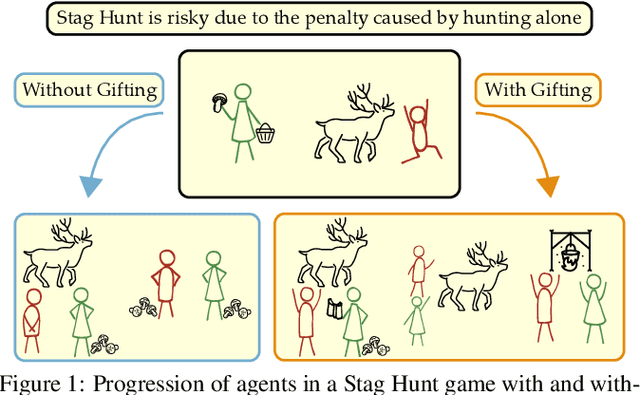
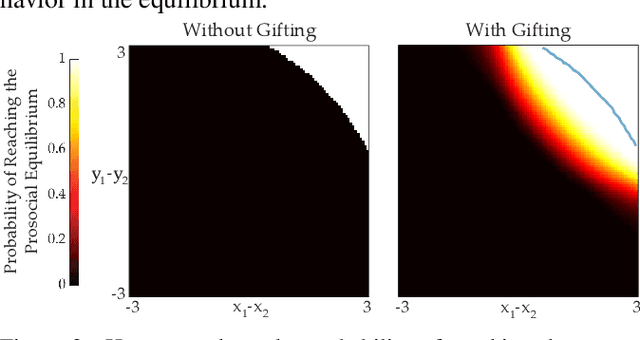

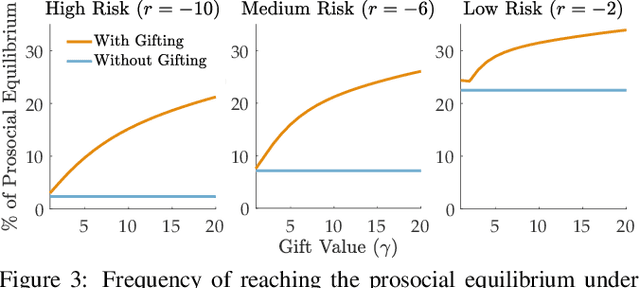
Coordination is often critical to forming prosocial behaviors -- behaviors that increase the overall sum of rewards received by all agents in a multi-agent game. However, state of the art reinforcement learning algorithms often suffer from converging to socially less desirable equilibria when multiple equilibria exist. Previous works address this challenge with explicit reward shaping, which requires the strong assumption that agents can be forced to be prosocial. We propose using a less restrictive peer-rewarding mechanism, gifting, that guides the agents toward more socially desirable equilibria while allowing agents to remain selfish and decentralized. Gifting allows each agent to give some of their reward to other agents. We employ a theoretical framework that captures the benefit of gifting in converging to the prosocial equilibrium by characterizing the equilibria's basins of attraction in a dynamical system. With gifting, we demonstrate increased convergence of high risk, general-sum coordination games to the prosocial equilibrium both via numerical analysis and experiments.
Incentivizing Routing Choices for Safe and Efficient Transportation in the Face of the COVID-19 Pandemic
Dec 28, 2020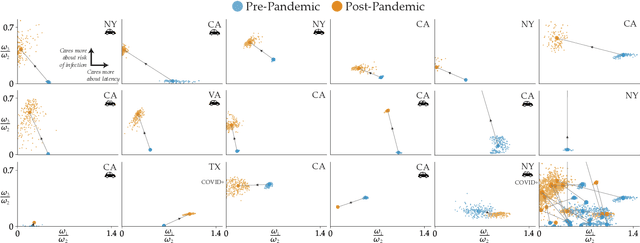
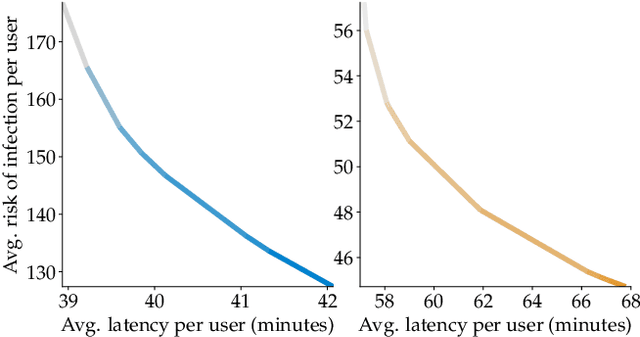
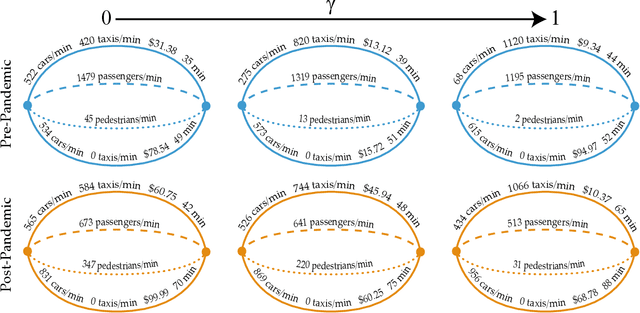
The COVID-19 pandemic has severely affected many aspects of people's daily lives. While many countries are in a re-opening stage, some effects of the pandemic on people's behaviors are expected to last much longer, including how they choose between different transport options. Experts predict considerably delayed recovery of the public transport options, as people try to avoid crowded places. In turn, significant increases in traffic congestion are expected, since people are likely to prefer using their own vehicles or taxis as opposed to riskier and more crowded options such as the railway. In this paper, we propose to use financial incentives to set the tradeoff between risk of infection and congestion to achieve safe and efficient transportation networks. To this end, we formulate a network optimization problem to optimize taxi fares. For our framework to be useful in various cities and times of the day without much designer effort, we also propose a data-driven approach to learn human preferences about transport options, which is then used in our taxi fare optimization. Our user studies and simulation experiments show our framework is able to minimize congestion and risk of infection.
Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving
Jul 01, 2020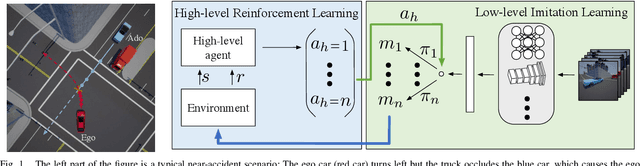
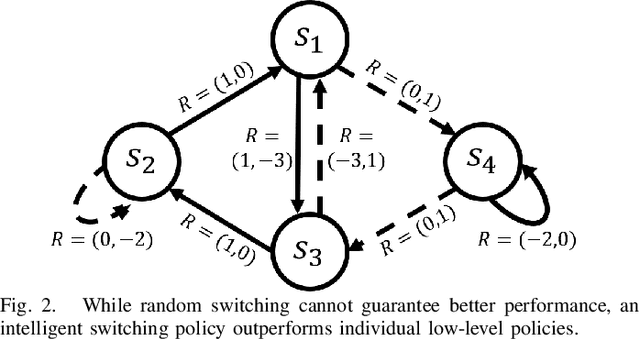
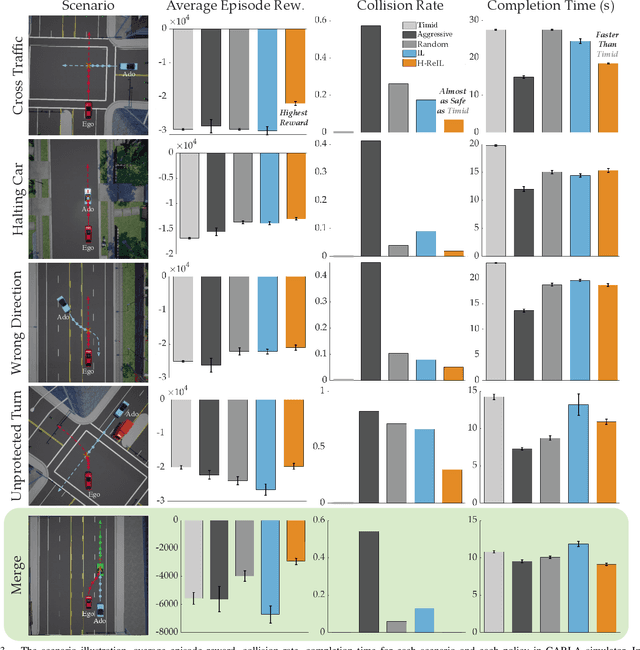
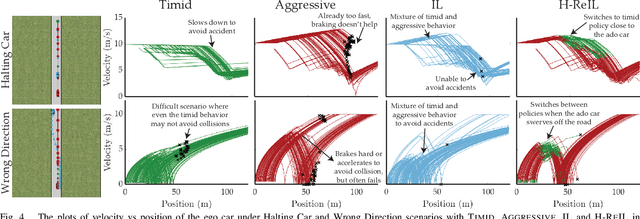
Autonomous driving has achieved significant progress in recent years, but autonomous cars are still unable to tackle high-risk situations where a potential accident is likely. In such near-accident scenarios, even a minor change in the vehicle's actions may result in drastically different consequences. To avoid unsafe actions in near-accident scenarios, we need to fully explore the environment. However, reinforcement learning (RL) and imitation learning (IL), two widely-used policy learning methods, cannot model rapid phase transitions and are not scalable to fully cover all the states. To address driving in near-accident scenarios, we propose a hierarchical reinforcement and imitation learning (H-ReIL) approach that consists of low-level policies learned by IL for discrete driving modes, and a high-level policy learned by RL that switches between different driving modes. Our approach exploits the advantages of both IL and RL by integrating them into a unified learning framework. Experimental results and user studies suggest our approach can achieve higher efficiency and safety compared to other methods. Analyses of the policies demonstrate our high-level policy appropriately switches between different low-level policies in near-accident driving situations.