 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluencing Towards Stable Multi-Agent Interactions
Paper and Code
Oct 05, 2021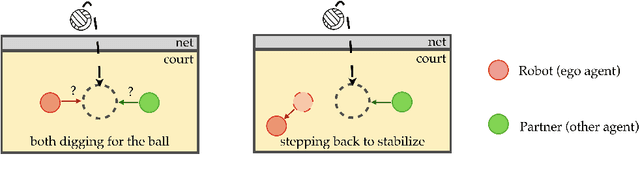


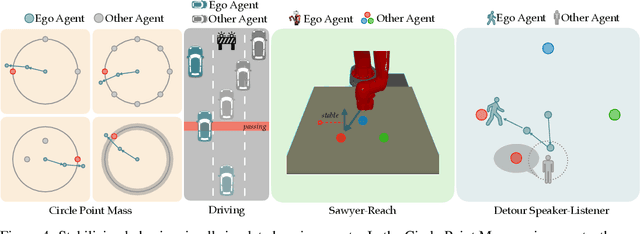
Learning in multi-agent environments is difficult due to the non-stationarity introduced by an opponent's or partner's changing behaviors. Instead of reactively adapting to the other agent's (opponent or partner) behavior, we propose an algorithm to proactively influence the other agent's strategy to stabilize -- which can restrain the non-stationarity caused by the other agent. We learn a low-dimensional latent representation of the other agent's strategy and the dynamics of how the latent strategy evolves with respect to our robot's behavior. With this learned dynamics model, we can define an unsupervised stability reward to train our robot to deliberately influence the other agent to stabilize towards a single strategy. We demonstrate the effectiveness of stabilizing in improving efficiency of maximizing the task reward in a variety of simulated environments, including autonomous driving, emergent communication, and robotic manipulation. We show qualitative results on our website: https://sites.google.com/view/stable-marl/.