 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFA: Structure Aware Face Animation
Paper and Code


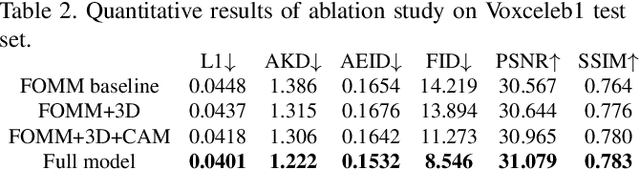

Recent success of generative adversarial networks (GAN) has made great progress on the face animation task. However, the complex scene structure of a face image still makes it a challenge to generate videos with face poses significantly deviating from the source image. On one hand, without knowing the facial geometric structure, generated face images might be improperly distorted. On the other hand, some area of the generated image might be occluded in the source image, which makes it difficult for GAN to generate realistic appearance. To address these problems, we propose a structure aware face animation (SAFA) method which constructs specific geometric structures to model different components of a face image. Following the well recognized motion based face animation technique, we use a 3D morphable model (3DMM) to model the face, multiple affine transforms to model the other foreground components like hair and beard, and an identity transform to model the background. The 3DMM geometric embedding not only helps generate realistic structure for the driving scene, but also contributes to better perception of occluded area in the generated image. Besides, we further propose to exploit the widely studied inpainting technique to faithfully recover the occluded image area. Both quantitative and qualitative experiment results have shown the superiority of our method. Code is available at https://github.com/Qiulin-W/SAFA.