 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Group-Aware Hashing for Fast Recommender Systems
Dec 23, 2025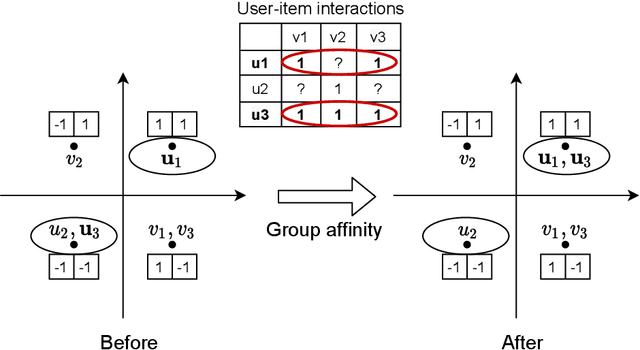

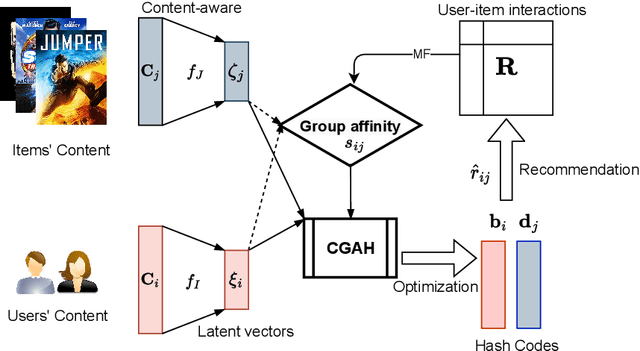
The fast online recommendation is critical for applications with large-scale databases; meanwhile, it is challenging to provide accurate recommendations in sparse scenarios. Hash technique has shown its superiority for speeding up the online recommendation by bit operations on Hamming distance computations. However, existing hashing-based recommendations suffer from low accuracy, especially with sparse settings, due to the limited representation capability of each bit and neglected inherent relations among users and items. To this end, this paper lodges a Collaborative Group-Aware Hashing (CGAH) method for both collaborative filtering (namely CGAH-CF) and content-aware recommendations (namely CGAH) by integrating the inherent group information to alleviate the sparse issue. Firstly, we extract inherent group affinities of users and items by classifying their latent vectors into different groups. Then, the preference is formulated as the inner product of the group affinity and the similarity of hash codes. By learning hash codes with the inherent group information, CGAH obtains more effective hash codes than other discrete methods with sparse interactive data. Extensive experiments on three public datasets show the superior performance of our proposed CGAH and CGAH-CF over the state-of-the-art discrete collaborative filtering methods and discrete content-aware recommendations under different sparse settings.
Attribute-formed Class-specific Concept Space: Endowing Language Bottleneck Model with Better Interpretability and Scalability
Mar 26, 2025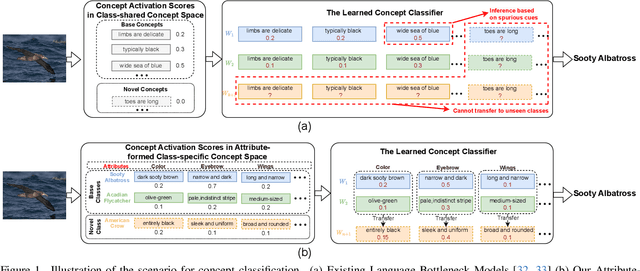

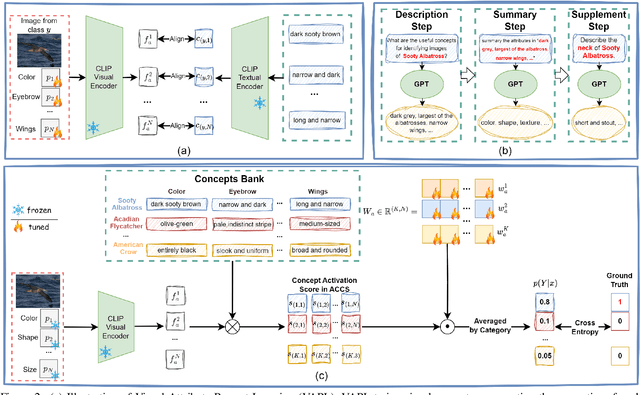

Language Bottleneck Models (LBMs) are proposed to achieve interpretable image recognition by classifying images based on textual concept bottlenecks. However, current LBMs simply list all concepts together as the bottleneck layer, leading to the spurious cue inference problem and cannot generalized to unseen classes. To address these limitations, we propose the Attribute-formed Language Bottleneck Model (ALBM). ALBM organizes concepts in the attribute-formed class-specific space, where concepts are descriptions of specific attributes for specific classes. In this way, ALBM can avoid the spurious cue inference problem by classifying solely based on the essential concepts of each class. In addition, the cross-class unified attribute set also ensures that the concept spaces of different classes have strong correlations, as a result, the learned concept classifier can be easily generalized to unseen classes. Moreover, to further improve interpretability, we propose Visual Attribute Prompt Learning (VAPL) to extract visual features on fine-grained attributes. Furthermore, to avoid labor-intensive concept annotation, we propose the Description, Summary, and Supplement (DSS) strategy to automatically generate high-quality concept sets with a complete and precise attribute. Extensive experiments on 9 widely used few-shot benchmarks demonstrate the interpretability, transferability, and performance of our approach. The code and collected concept sets are available at https://github.com/tiggers23/ALBM.
Partial-label Learning with Mixed Closed-set and Open-set Out-of-candidate Examples
Jul 02, 2023
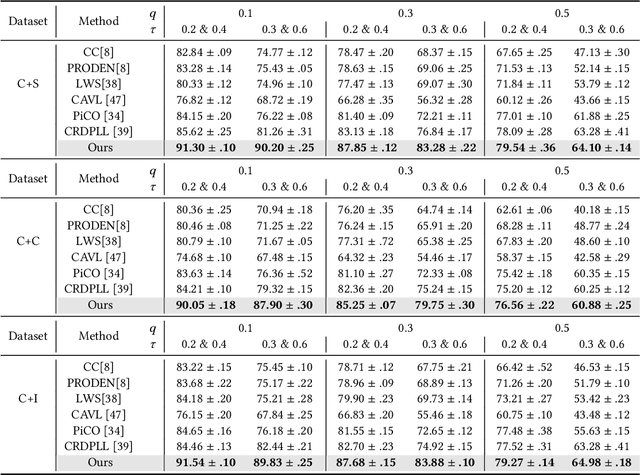
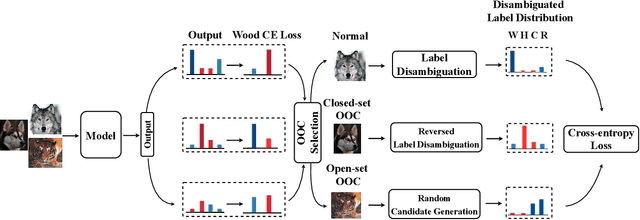
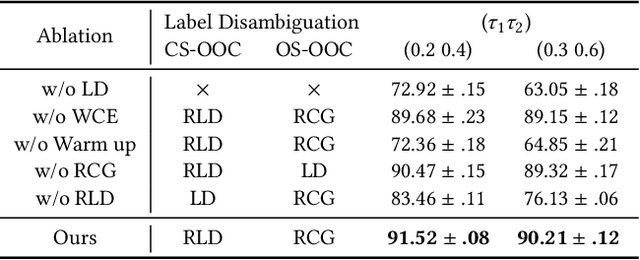
Partial-label learning (PLL) relies on a key assumption that the true label of each training example must be in the candidate label set. This restrictive assumption may be violated in complex real-world scenarios, and thus the true label of some collected examples could be unexpectedly outside the assigned candidate label set. In this paper, we term the examples whose true label is outside the candidate label set OOC (out-of-candidate) examples, and pioneer a new PLL study to learn with OOC examples. We consider two types of OOC examples in reality, i.e., the closed-set/open-set OOC examples whose true label is inside/outside the known label space. To solve this new PLL problem, we first calculate the wooden cross-entropy loss from candidate and non-candidate labels respectively, and dynamically differentiate the two types of OOC examples based on specially designed criteria. Then, for closed-set OOC examples, we conduct reversed label disambiguation in the non-candidate label set; for open-set OOC examples, we leverage them for training by utilizing an effective regularization strategy that dynamically assigns random candidate labels from the candidate label set. In this way, the two types of OOC examples can be differentiated and further leveraged for model training. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art PLL methods.
Learning unbiased zero-shot semantic segmentation networks via transductive transfer
Jul 01, 2020
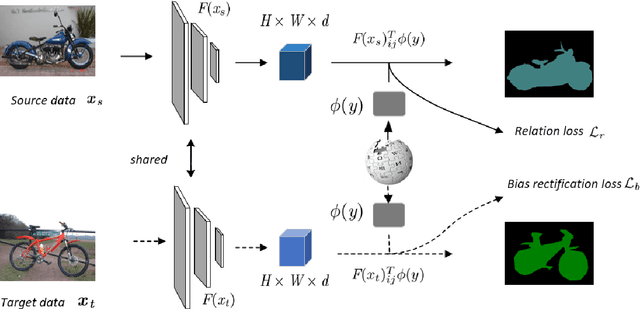
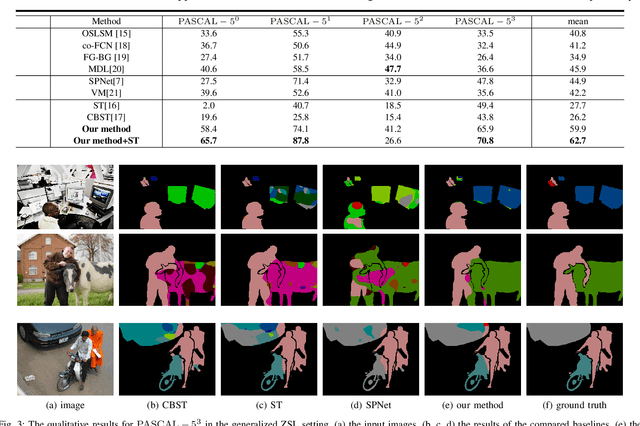
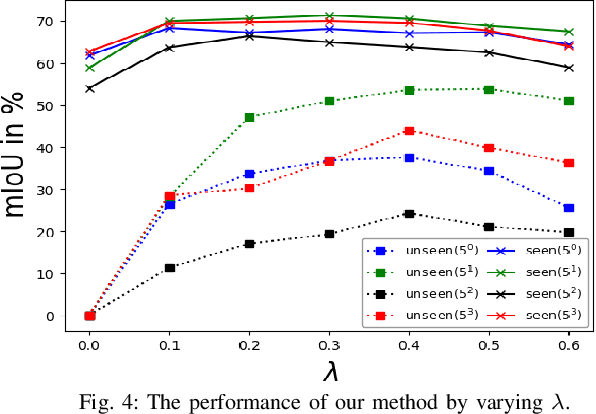
Semantic segmentation, which aims to acquire a detailed understanding of images, is an essential issue in computer vision. However, in practical scenarios, new categories that are different from the categories in training usually appear. Since it is impractical to collect labeled data for all categories, how to conduct zero-shot learning in semantic segmentation establishes an important problem. Although the attribute embedding of categories can promote effective knowledge transfer across different categories, the prediction of segmentation network reveals obvious bias to seen categories. In this paper, we propose an easy-to-implement transductive approach to alleviate the prediction bias in zero-shot semantic segmentation. Our method assumes that both the source images with full pixel-level labels and unlabeled target images are available during training. To be specific, the source images are used to learn the relationship between visual images and semantic embeddings, while the target images are used to alleviate the prediction bias towards seen categories. We conduct comprehensive experiments on diverse split s of the PASCAL dataset. The experimental results clearly demonstrate the effectiveness of our method.
Learning Cross-domain Semantic-Visual Relation for Transductive Zero-Shot Learning
Mar 31, 2020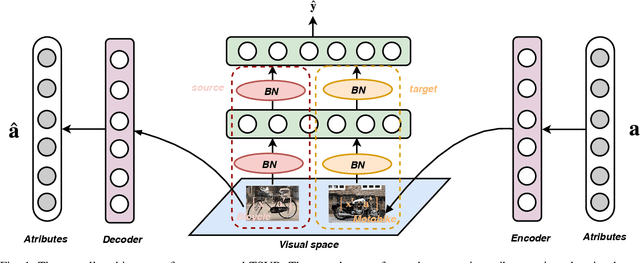
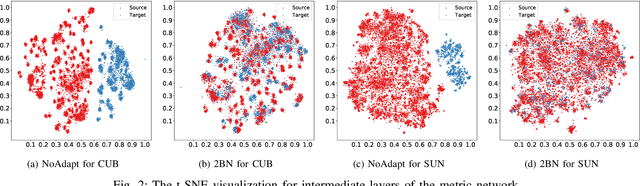
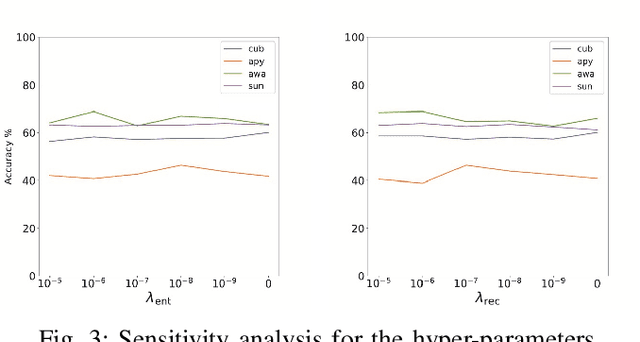
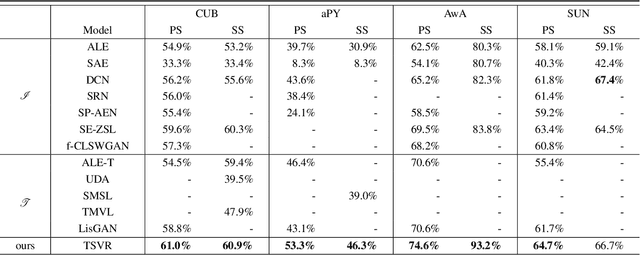
Zero-Shot Learning (ZSL) aims to learn recognition models for recognizing new classes without labeled data. In this work, we propose a novel approach dubbed Transferrable Semantic-Visual Relation (TSVR) to facilitate the cross-category transfer in transductive ZSL. Our approach draws on an intriguing insight connecting two challenging problems, i.e. domain adaptation and zero-shot learning. Domain adaptation aims to transfer knowledge across two different domains (i.e., source domain and target domain) that share the identical task/label space. For ZSL, the source and target domains have different tasks/label spaces. Hence, ZSL is usually considered as a more difficult transfer setting compared with domain adaptation. Although the existing ZSL approaches use semantic attributes of categories to bridge the source and target domains, their performances are far from satisfactory due to the large domain gap between different categories. In contrast, our method directly transforms ZSL into a domain adaptation task through redrawing ZSL as predicting the similarity/dissimilarity labels for the pairs of semantic attributes and visual features. For this redrawn domain adaptation problem, we propose to use a domain-specific batch normalization component to reduce the domain discrepancy of semantic-visual pairs. Experimental results over diverse ZSL benchmarks clearly demonstrate the superiority of our method.