 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning unbiased zero-shot semantic segmentation networks via transductive transfer
Paper and Code

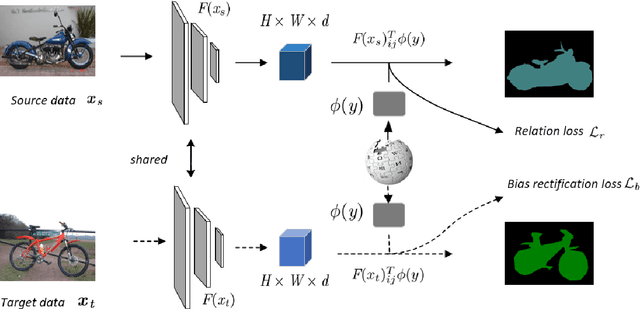
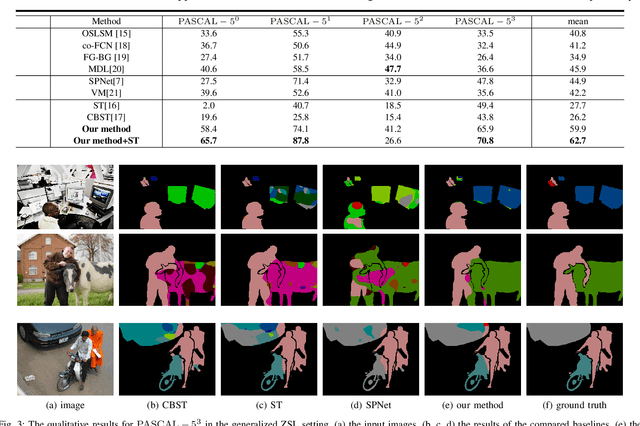
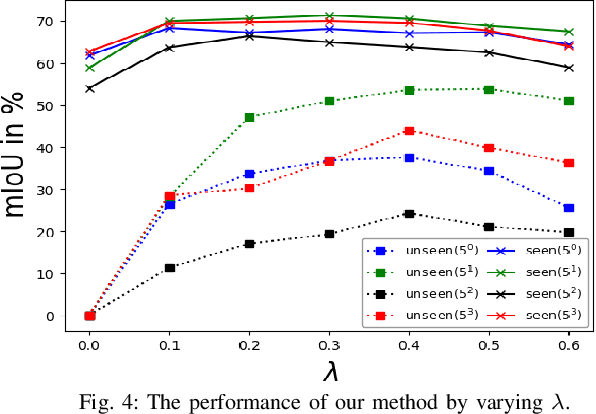
Semantic segmentation, which aims to acquire a detailed understanding of images, is an essential issue in computer vision. However, in practical scenarios, new categories that are different from the categories in training usually appear. Since it is impractical to collect labeled data for all categories, how to conduct zero-shot learning in semantic segmentation establishes an important problem. Although the attribute embedding of categories can promote effective knowledge transfer across different categories, the prediction of segmentation network reveals obvious bias to seen categories. In this paper, we propose an easy-to-implement transductive approach to alleviate the prediction bias in zero-shot semantic segmentation. Our method assumes that both the source images with full pixel-level labels and unlabeled target images are available during training. To be specific, the source images are used to learn the relationship between visual images and semantic embeddings, while the target images are used to alleviate the prediction bias towards seen categories. We conduct comprehensive experiments on diverse split s of the PASCAL dataset. The experimental results clearly demonstrate the effectiveness of our method.