 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesebis at ArchEHR-QA 2026: How Much Can You Do Locally? Evaluating Grounded EHR QA on a Single Notebook
Mar 14, 2026Clinical question answering over electronic health records (EHRs) can help clinicians and patients access relevant medical information more efficiently. However, many recent approaches rely on large cloud-based models, which are difficult to deploy in clinical environments due to privacy constraints and computational requirements. In this work, we investigate how far grounded EHR question answering can be pushed when restricted to a single notebook. We participate in all four subtasks of the ArchEHR-QA 2026 shared task and evaluate several approaches designed to run on commodity hardware. All experiments are conducted locally without external APIs or cloud infrastructure. Our results show that such systems can achieve competitive performance on the shared task leaderboards. In particular, our submissions perform above average in two subtasks, and we observe that smaller models can approach the performance of much larger systems when properly configured. These findings suggest that privacy-preserving EHR QA systems running fully locally are feasible with current models and commodity hardware. The source code is available at https://github.com/ibrahimey/ArchEHR-QA-2026.
CRAWLDoc: A Dataset for Robust Ranking of Bibliographic Documents
Jun 04, 2025Publication databases rely on accurate metadata extraction from diverse web sources, yet variations in web layouts and data formats present challenges for metadata providers. This paper introduces CRAWLDoc, a new method for contextual ranking of linked web documents. Starting with a publication's URL, such as a digital object identifier, CRAWLDoc retrieves the landing page and all linked web resources, including PDFs, ORCID profiles, and supplementary materials. It embeds these resources, along with anchor texts and the URLs, into a unified representation. For evaluating CRAWLDoc, we have created a new, manually labeled dataset of 600 publications from six top publishers in computer science. Our method CRAWLDoc demonstrates a robust and layout-independent ranking of relevant documents across publishers and data formats. It lays the foundation for improved metadata extraction from web documents with various layouts and formats. Our source code and dataset can be accessed at https://github.com/FKarl/CRAWLDoc.
Continual Learning for Encoder-only Language Models via a Discrete Key-Value Bottleneck
Dec 11, 2024Continual learning remains challenging across various natural language understanding tasks. When models are updated with new training data, they risk catastrophic forgetting of prior knowledge. In the present work, we introduce a discrete key-value bottleneck for encoder-only language models, allowing for efficient continual learning by requiring only localized updates. Inspired by the success of a discrete key-value bottleneck in vision, we address new and NLP-specific challenges. We experiment with different bottleneck architectures to find the most suitable variants regarding language, and present a generic discrete key initialization technique for NLP that is task independent. We evaluate the discrete key-value bottleneck in four continual learning NLP scenarios and demonstrate that it alleviates catastrophic forgetting. We showcase that it offers competitive performance to other popular continual learning methods, with lower computational costs.
GenCodeSearchNet: A Benchmark Test Suite for Evaluating Generalization in Programming Language Understanding
Nov 16, 2023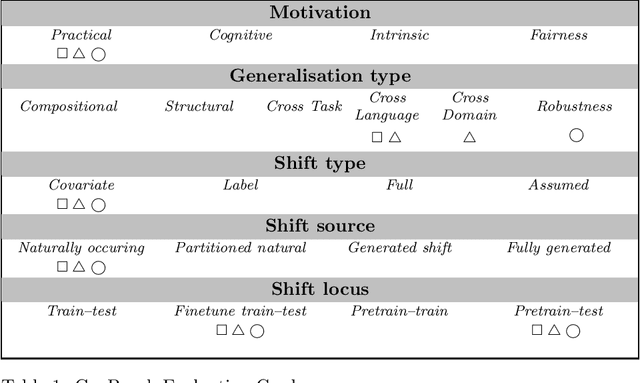
Language models can serve as a valuable tool for software developers to increase productivity. Large generative models can be used for code generation and code completion, while smaller encoder-only models are capable of performing code search tasks using natural language queries.These capabilities are heavily influenced by the quality and diversity of the available training data. Source code datasets used for training usually focus on the most popular languages and testing is mostly conducted on the same distributions, often overlooking low-resource programming languages. Motivated by the NLP generalization taxonomy proposed by Hupkes et.\,al., we propose a new benchmark dataset called GenCodeSearchNet (GeCS) which builds upon existing natural language code search datasets to systemically evaluate the programming language understanding generalization capabilities of language models. As part of the full dataset, we introduce a new, manually curated subset StatCodeSearch that focuses on R, a popular but so far underrepresented programming language that is often used by researchers outside the field of computer science. For evaluation and comparison, we collect several baseline results using fine-tuned BERT-style models and GPT-style large language models in a zero-shot setting.
Transformers are Short Text Classifiers: A Study of Inductive Short Text Classifiers on Benchmarks and Real-world Datasets
Dec 06, 2022Short text classification is a crucial and challenging aspect of Natural Language Processing. For this reason, there are numerous highly specialized short text classifiers. However, in recent short text research, State of the Art (SOTA) methods for traditional text classification, particularly the pure use of Transformers, have been unexploited. In this work, we examine the performance of a variety of short text classifiers as well as the top performing traditional text classifier. We further investigate the effects on two new real-world short text datasets in an effort to address the issue of becoming overly dependent on benchmark datasets with a limited number of characteristics. Our experiments unambiguously demonstrate that Transformers achieve SOTA accuracy on short text classification tasks, raising the question of whether specialized short text techniques are necessary.