 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexMoRE: A Flexible Mixture of Rank-heterogeneous Experts for Efficient Federatedly-trained Large Language Models
Feb 09, 2026Recent advances in mixture-of-experts architectures have shown that individual experts models can be trained federatedly, i.e., in isolation from other experts by using a common base model to facilitate coordination. However, we hypothesize that full-sized experts may not be necessary for all domains and that instead low-rank adapters may be sufficient. Here, we introduce FlexMoRE, a Flexible Mixture of Rank-heterogenous Experts, which may be either full-sized experts or adapters of a suitable rank. We systematically investigate the trade-off between expert rank and downstream task performance by evaluating $6$ experts with ranks $2^0$ to $2^{14}$ resulting in experiments covering 150 mixtures (96 with 2 experts, 54 with 7 experts) that are evaluated across $120$ tasks. For our experiments, we build on FlexOlmo and turn its pre-trained experts into low-rank versions. Our regression analysis from expert rank to downstream task performance reveals that the best-performing rank is substantially higher for reasoning-heavy benchmarks than for knowledge-heavy benchmarks. These findings on rank sensitivity come with direct implications for memory efficiency: Using optimal ranks, FlexMoRE yields improved downstream task performance (average score $47.18$) compared to the baseline FlexOlmo-style mixture of full-sized experts (average score $45.46$) at less than one third the parameters ($10.75$B for FlexMoRE vs. $33.27$B for FlexOlmo). All code will be made available.
FlexDeMo: Decoupled Momentum Optimization for Fully and Hybrid Sharded Training
Feb 10, 2025
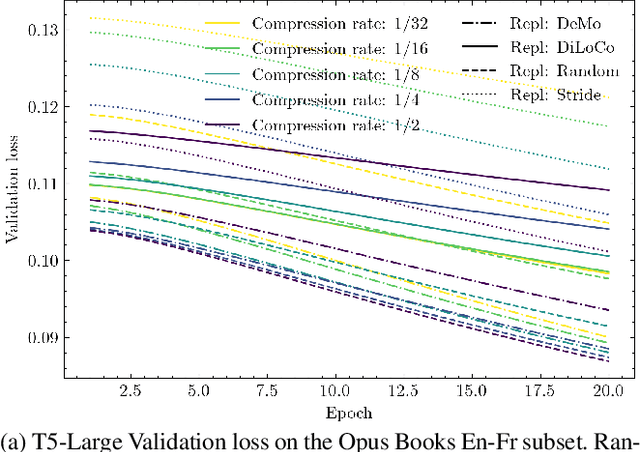


Training large neural network models requires extensive computational resources, often distributed across several nodes and accelerators. Recent findings suggest that it may be sufficient to only exchange the fast moving components of the gradients, while accumulating momentum locally (Decoupled Momentum, or DeMo). However, when considering larger models that do not fit on a single accelerate, the exchange of gradient information and the integration of DeMo needs to be reconsidered. Here, we propose employing a hybrid strategy, FlexDeMo, whereby nodes fully synchronize locally between different GPUs and inter-node communication is improved through only using the fast-moving components. This effectively combines previous hybrid sharding strategies with the advantages of decoupled momentum. Our experimental results show that FlexDeMo is on par with AdamW in terms of validation loss, demonstrating its viability.