 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Text Classification (HTC) vs. eXtreme Multilabel Classification (XML): Two Sides of the Same Medal
Paper and Code
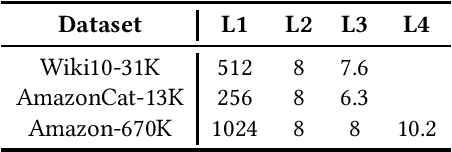
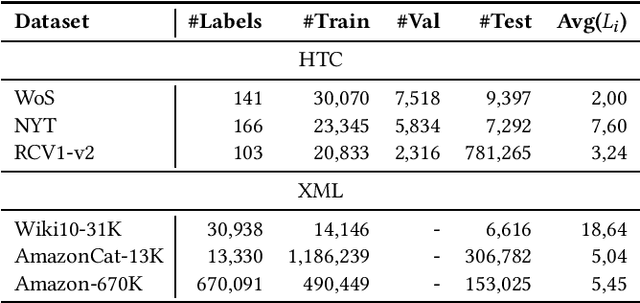
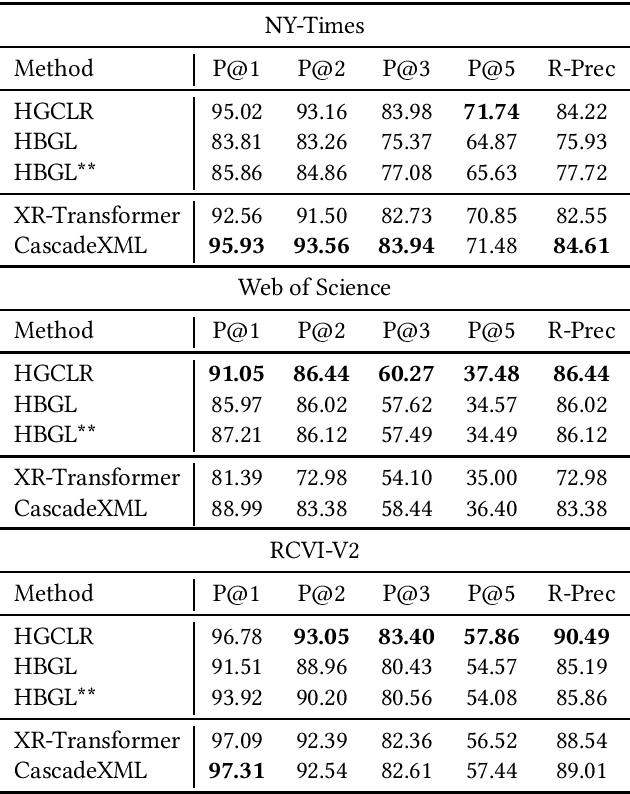
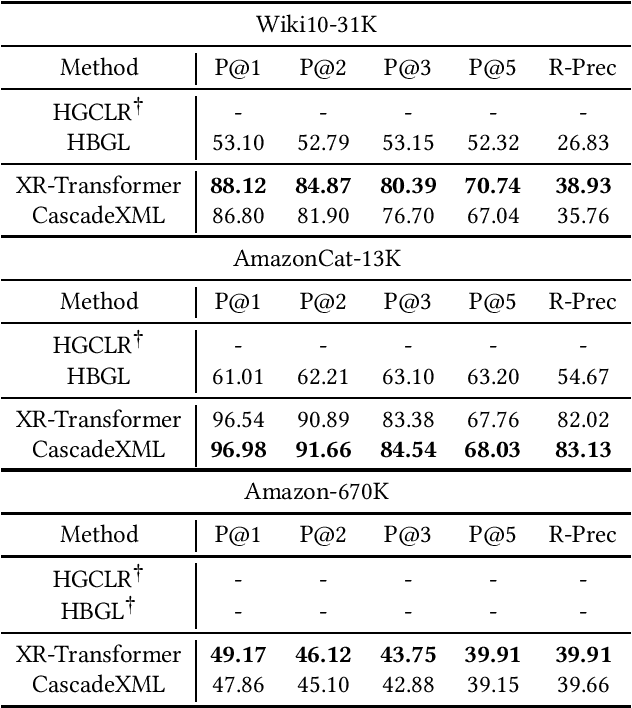
Assigning a subset of labels from a fixed pool of labels to a given input text is a text classification problem with many real-world applications, such as in recommender systems. Two separate research streams address this issue. Hierarchical Text Classification (HTC) focuses on datasets with smaller label pools of hundreds of entries, accompanied by a semantic label hierarchy. In contrast, eXtreme Multi-Label Text Classification (XML) considers very large label pools with up to millions of entries, in which the labels are not arranged in any particular manner. However, in XML, a common approach is to construct an artificial hierarchy without any semantic information before or during the training process. Here, we investigate how state-of-the-art models from one domain perform when trained and tested on datasets from the other domain. The HBGL and HGLCR models from the HTC domain are trained and tested on the datasets Wiki10-31K, AmazonCat-13K, and Amazon-670K from the XML domain. On the other side, the XML models CascadeXML and XR-Transformer are trained and tested on the datasets Web of Science, The New York Times Annotated Corpus, and RCV1-V2 from the HTC domain. HTC models, on the other hand, are not equipped to handle the size of XML datasets and achieve poor transfer results. The code and numerous files that are needed to reproduce our results can be obtained from https://github.com/FloHauss/XMC_HTC