 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization and Morphology in Multilingual Language Models: A~Comparative Analysis of mT5 and ByT5
Paper and Code
Oct 15, 2024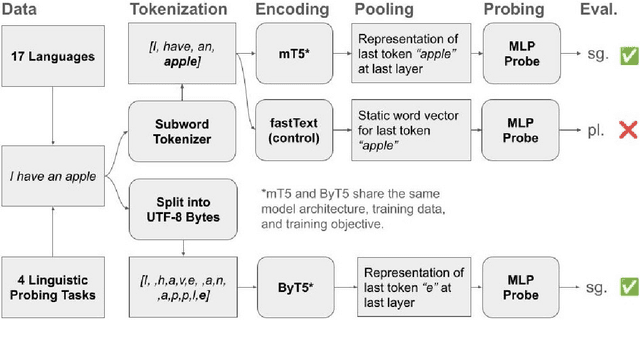

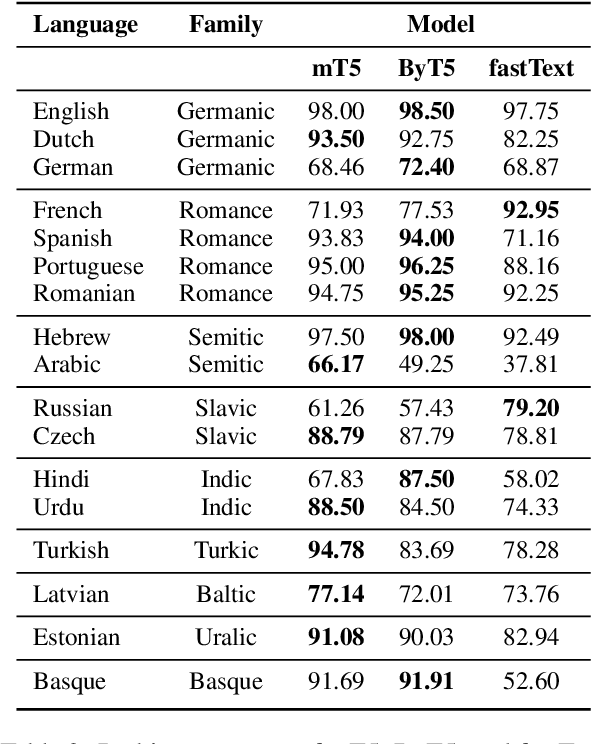
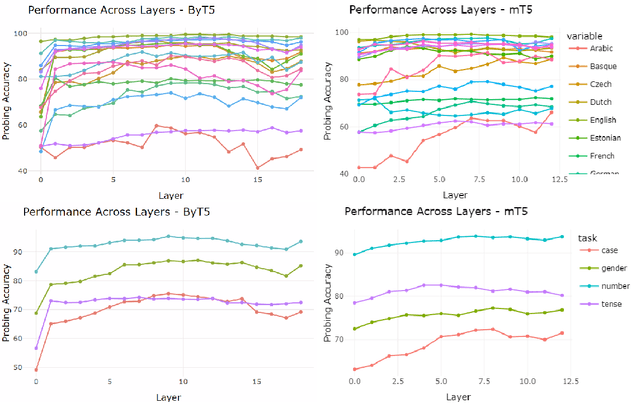
Morphology is a crucial factor for multilingual language modeling as it poses direct challenges for tokenization. Here, we seek to understand how tokenization influences the morphological knowledge encoded in multilingual language models. Specifically, we capture the impact of tokenization by contrasting two multilingual language models: mT5 and ByT5. The two models share the same architecture, training objective, and training data and only differ in their tokenization strategies: subword tokenization vs. character-level tokenization. Probing the morphological knowledge encoded in these models on four tasks and 17 languages, our analyses show that multilingual language models learn the morphological systems of some languages better than others despite similar average performance and that morphological information is encoded in the middle and late layers, where characted-based models need a few more layers to yield commensurate probing accuracy. Finally, we show that languages with more irregularities benefit more from having a higher share of the pre-training data.