 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization and Morphology in Multilingual Language Models: A~Comparative Analysis of mT5 and ByT5
Oct 15, 2024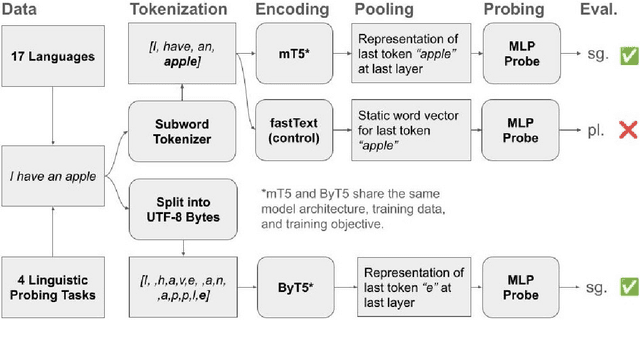

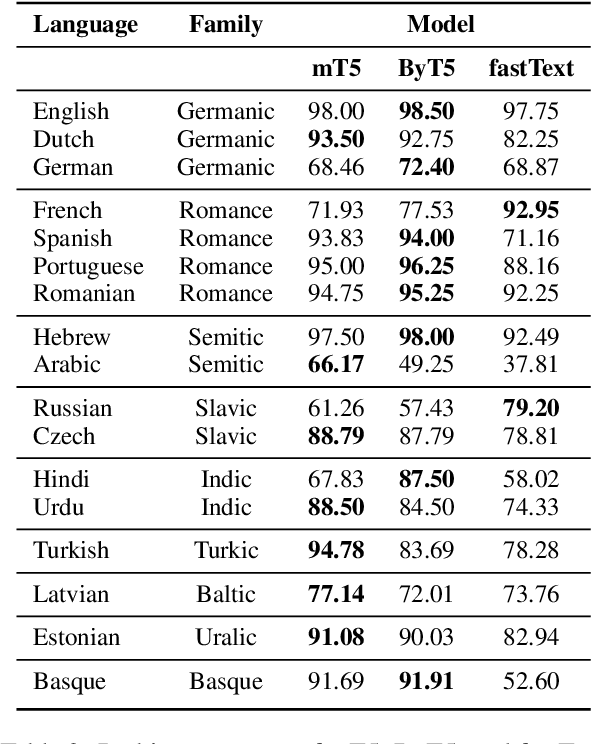
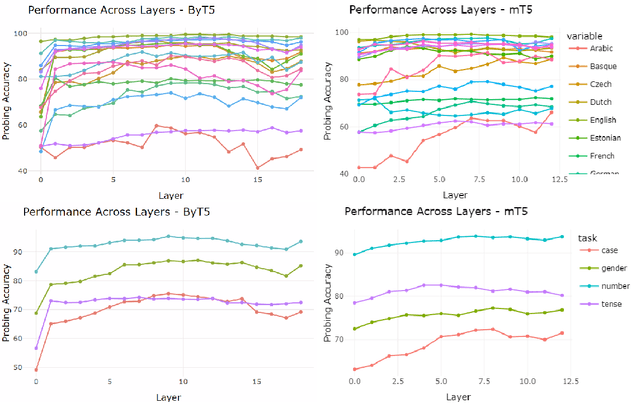
Morphology is a crucial factor for multilingual language modeling as it poses direct challenges for tokenization. Here, we seek to understand how tokenization influences the morphological knowledge encoded in multilingual language models. Specifically, we capture the impact of tokenization by contrasting two multilingual language models: mT5 and ByT5. The two models share the same architecture, training objective, and training data and only differ in their tokenization strategies: subword tokenization vs. character-level tokenization. Probing the morphological knowledge encoded in these models on four tasks and 17 languages, our analyses show that multilingual language models learn the morphological systems of some languages better than others despite similar average performance and that morphological information is encoded in the middle and late layers, where characted-based models need a few more layers to yield commensurate probing accuracy. Finally, we show that languages with more irregularities benefit more from having a higher share of the pre-training data.
Emergent communication and learning pressures in language models: a language evolution perspective
Mar 21, 2024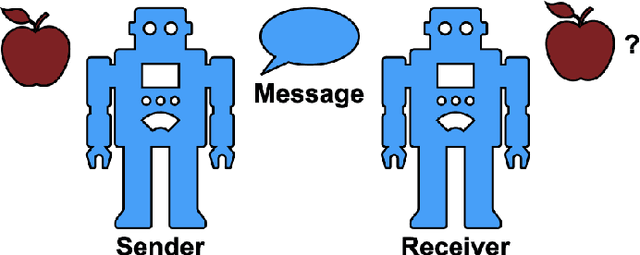
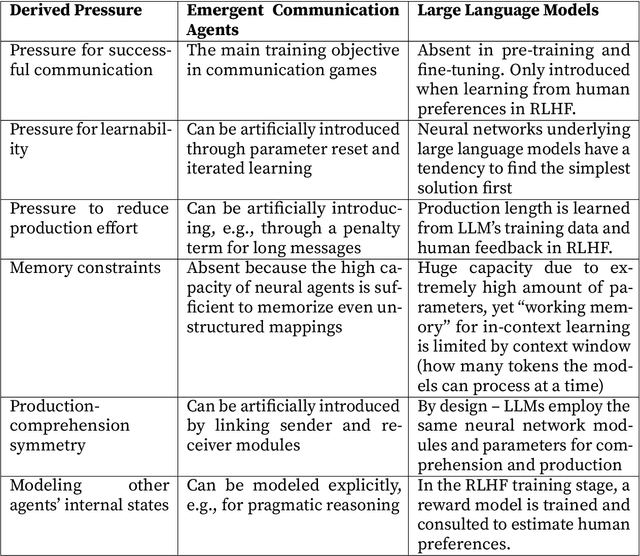
Language models and humans are two types of learning systems. Finding or facilitating commonalities could enable major breakthroughs in our understanding of the acquisition and evolution of language. Many theories of language evolution rely heavily on learning biases and learning pressures. Yet due to substantial differences in learning pressures, it is questionable whether the similarity between humans and machines is sufficient for insights to carry over and to be worth testing with human participants. Here, we review the emergent communication literature, a subfield of multi-agent reinforcement learning, from a language evolution perspective. We find that the emergent communication literature excels at designing and adapting models to recover initially absent linguistic phenomena of natural languages. Based on a short literature review, we identify key pressures that have recovered initially absent human patterns in emergent communication models: communicative success, efficiency, learnability, and other psycho-/sociolinguistic factors. We argue that this may serve as inspiration for how to design language models for language acquisition and language evolution research.
What makes a language easy to deep-learn?
Feb 23, 2023Neural networks drive the success of natural language processing. A fundamental property of natural languages is their compositional structure, allowing us to describe new meanings systematically. However, neural networks notoriously struggle with systematic generalization and do not necessarily benefit from a compositional structure in emergent communication simulations. Here, we test how neural networks compare to humans in learning and generalizing a new language. We do this by closely replicating an artificial language learning study (conducted originally with human participants) and evaluating the memorization and generalization capabilities of deep neural networks with respect to the degree of structure in the input language. Our results show striking similarities between humans and deep neural networks: More structured linguistic input leads to more systematic generalization and better convergence between humans and neural network agents and between different neural agents. We then replicate this structure bias found in humans and our recurrent neural networks with a Transformer-based large language model (GPT-3), showing a similar benefit for structured linguistic input regarding generalization systematicity and memorization errors. These findings show that the underlying structure of languages is crucial for systematic generalization. Due to the correlation between community size and linguistic structure in natural languages, our findings underscore the challenge of automated processing of low-resource languages. Nevertheless, the similarity between humans and machines opens new avenues for language evolution research.
Emergent Communication for Understanding Human Language Evolution: What's Missing?
Apr 22, 2022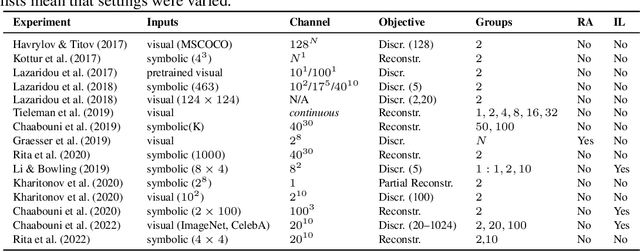
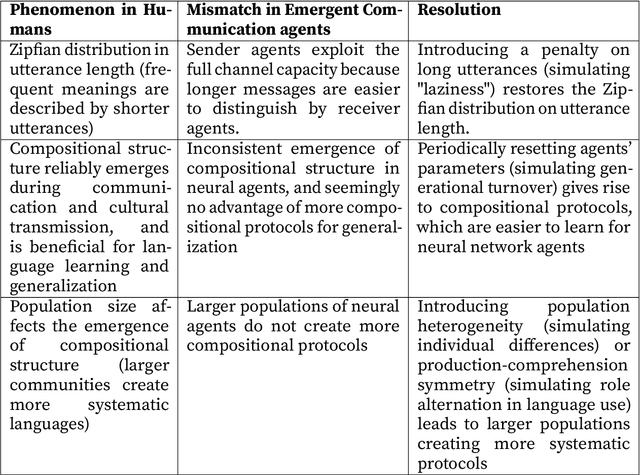
Emergent communication protocols among humans and artificial neural network agents do not yet share the same properties and show some critical mismatches in results. We describe three important phenomena with respect to the emergence and benefits of compositionality: ease-of-learning, generalization, and group size effects (i.e., larger groups create more systematic languages). The latter two are not fully replicated with neural agents, which hinders the use of neural emergent communication for language evolution research. We argue that one possible reason for these mismatches is that key cognitive and communicative constraints of humans are not yet integrated. Specifically, in humans, memory constraints and the alternation between the roles of speaker and listener underlie the emergence of linguistic structure, yet these constraints are typically absent in neural simulations. We suggest that introducing such communicative and cognitive constraints would promote more linguistically plausible behaviors with neural agents.