 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-of-Mixture Training: Training One-Step Generative Models Made Simple
Feb 13, 2025



We propose Score-of-Mixture Training (SMT), a novel framework for training one-step generative models by minimizing a class of divergences called the $\alpha$-skew Jensen-Shannon divergence. At its core, SMT estimates the score of mixture distributions between real and fake samples across multiple noise levels. Similar to consistency models, our approach supports both training from scratch (SMT) and distillation using a pretrained diffusion model, which we call Score-of-Mixture Distillation (SMD). It is simple to implement, requires minimal hyperparameter tuning, and ensures stable training. Experiments on CIFAR-10 and ImageNet 64x64 show that SMT/SMD are competitive with and can even outperform existing methods.
RF Challenge: The Data-Driven Radio Frequency Signal Separation Challenge
Sep 13, 2024



This paper addresses the critical problem of interference rejection in radio-frequency (RF) signals using a novel, data-driven approach that leverages state-of-the-art AI models. Traditionally, interference rejection algorithms are manually tailored to specific types of interference. This work introduces a more scalable data-driven solution and contains the following contributions. First, we present an insightful signal model that serves as a foundation for developing and analyzing interference rejection algorithms. Second, we introduce the RF Challenge, a publicly available dataset featuring diverse RF signals along with code templates, which facilitates data-driven analysis of RF signal problems. Third, we propose novel AI-based rejection algorithms, specifically architectures like UNet and WaveNet, and evaluate their performance across eight different signal mixture types. These models demonstrate superior performance exceeding traditional methods like matched filtering and linear minimum mean square error estimation by up to two orders of magnitude in bit-error rate. Fourth, we summarize the results from an open competition hosted at 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2024) based on the RF Challenge, highlighting the significant potential for continued advancements in this area. Our findings underscore the promise of deep learning algorithms in mitigating interference, offering a strong foundation for future research.
Score-based Source Separation with Applications to Digital Communication Signals
Jun 26, 2023



We propose a new method for separating superimposed sources using diffusion-based generative models. Our method relies only on separately trained statistical priors of independent sources to establish a new objective function guided by maximum a posteriori estimation with an $\alpha$-posterior, across multiple levels of Gaussian smoothing. Motivated by applications in radio-frequency (RF) systems, we are interested in sources with underlying discrete nature and the recovery of encoded bits from a signal of interest, as measured by the bit error rate (BER). Experimental results with RF mixtures demonstrate that our method results in a BER reduction of 95% over classical and existing learning-based methods. Our analysis demonstrates that our proposed method yields solutions that asymptotically approach the modes of an underlying discrete distribution. Furthermore, our method can be viewed as a multi-source extension to the recently proposed score distillation sampling scheme, shedding additional light on its use beyond conditional sampling.
Self-Supervised Representations for Singing Voice Conversion
Mar 21, 2023A singing voice conversion model converts a song in the voice of an arbitrary source singer to the voice of a target singer. Recently, methods that leverage self-supervised audio representations such as HuBERT and Wav2Vec 2.0 have helped further the state-of-the-art. Though these methods produce more natural and melodic singing outputs, they often rely on confusion and disentanglement losses to render the self-supervised representations speaker and pitch-invariant. In this paper, we circumvent disentanglement training and propose a new model that leverages ASR fine-tuned self-supervised representations as inputs to a HiFi-GAN neural vocoder for singing voice conversion. We experiment with different f0 encoding schemes and show that an f0 harmonic generation module that uses a parallel bank of transposed convolutions (PBTC) alongside ASR fine-tuned Wav2Vec 2.0 features results in the best singing voice conversion quality. Additionally, the model is capable of making a spoken voice sing. We also show that a simple f0 shifting scheme during inference helps retain singer identity and bolsters the performance of our singing voice conversion model. Our results are backed up by extensive MOS studies that compare different ablations and baselines.
Detecting Audio Attacks on ASR Systems with Dropout Uncertainty
Jun 02, 2020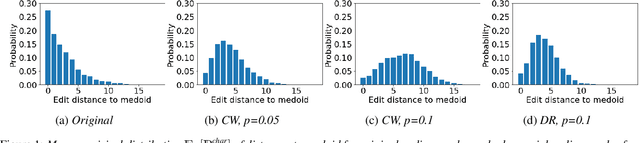
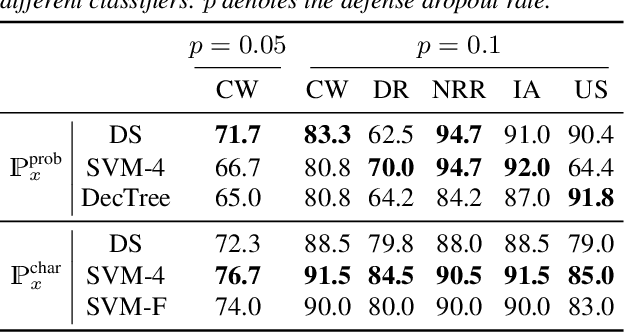
Various adversarial audio attacks have recently been developed to fool automatic speech recognition (ASR) systems. We here propose a defense against such attacks based on the uncertainty introduced by dropout in neural networks. We show that our defense is able to detect attacks created through optimized perturbations and frequency masking on a state-of-the-art end-to-end ASR system. Furthermore, the defense can be made robust against attacks that are immune to noise reduction. We test our defense on Mozilla's CommonVoice dataset, the UrbanSound dataset, and an excerpt of the LibriSpeech dataset, showing that it achieves high detection accuracy in a wide range of scenarios.