 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRF Challenge: The Data-Driven Radio Frequency Signal Separation Challenge
Sep 13, 2024



This paper addresses the critical problem of interference rejection in radio-frequency (RF) signals using a novel, data-driven approach that leverages state-of-the-art AI models. Traditionally, interference rejection algorithms are manually tailored to specific types of interference. This work introduces a more scalable data-driven solution and contains the following contributions. First, we present an insightful signal model that serves as a foundation for developing and analyzing interference rejection algorithms. Second, we introduce the RF Challenge, a publicly available dataset featuring diverse RF signals along with code templates, which facilitates data-driven analysis of RF signal problems. Third, we propose novel AI-based rejection algorithms, specifically architectures like UNet and WaveNet, and evaluate their performance across eight different signal mixture types. These models demonstrate superior performance exceeding traditional methods like matched filtering and linear minimum mean square error estimation by up to two orders of magnitude in bit-error rate. Fourth, we summarize the results from an open competition hosted at 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2024) based on the RF Challenge, highlighting the significant potential for continued advancements in this area. Our findings underscore the promise of deep learning algorithms in mitigating interference, offering a strong foundation for future research.
Score-based Source Separation with Applications to Digital Communication Signals
Jun 26, 2023



We propose a new method for separating superimposed sources using diffusion-based generative models. Our method relies only on separately trained statistical priors of independent sources to establish a new objective function guided by maximum a posteriori estimation with an $\alpha$-posterior, across multiple levels of Gaussian smoothing. Motivated by applications in radio-frequency (RF) systems, we are interested in sources with underlying discrete nature and the recovery of encoded bits from a signal of interest, as measured by the bit error rate (BER). Experimental results with RF mixtures demonstrate that our method results in a BER reduction of 95% over classical and existing learning-based methods. Our analysis demonstrates that our proposed method yields solutions that asymptotically approach the modes of an underlying discrete distribution. Furthermore, our method can be viewed as a multi-source extension to the recently proposed score distillation sampling scheme, shedding additional light on its use beyond conditional sampling.
On Neural Architectures for Deep Learning-based Source Separation of Co-Channel OFDM Signals
Mar 15, 2023


We study the single-channel source separation problem involving orthogonal frequency-division multiplexing (OFDM) signals, which are ubiquitous in many modern-day digital communication systems. Related efforts have been pursued in monaural source separation, where state-of-the-art neural architectures have been adopted to train an end-to-end separator for audio signals (as 1-dimensional time series). In this work, through a prototype problem based on the OFDM source model, we assess -- and question -- the efficacy of using audio-oriented neural architectures in separating signals based on features pertinent to communication waveforms. Perhaps surprisingly, we demonstrate that in some configurations, where perfect separation is theoretically attainable, these audio-oriented neural architectures perform poorly in separating co-channel OFDM waveforms. Yet, we propose critical domain-informed modifications to the network parameterization, based on insights from OFDM structures, that can confer about 30 dB improvement in performance.
Data-Driven Blind Synchronization and Interference Rejection for Digital Communication Signals
Sep 11, 2022



We study the potential of data-driven deep learning methods for separation of two communication signals from an observation of their mixture. In particular, we assume knowledge on the generation process of one of the signals, dubbed signal of interest (SOI), and no knowledge on the generation process of the second signal, referred to as interference. This form of the single-channel source separation problem is also referred to as interference rejection. We show that capturing high-resolution temporal structures (nonstationarities), which enables accurate synchronization to both the SOI and the interference, leads to substantial performance gains. With this key insight, we propose a domain-informed neural network (NN) design that is able to improve upon both "off-the-shelf" NNs and classical detection and interference rejection methods, as demonstrated in our simulations. Our findings highlight the key role communication-specific domain knowledge plays in the development of data-driven approaches that hold the promise of unprecedented gains.
Exploiting Temporal Structures of Cyclostationary Signals for Data-Driven Single-Channel Source Separation
Aug 22, 2022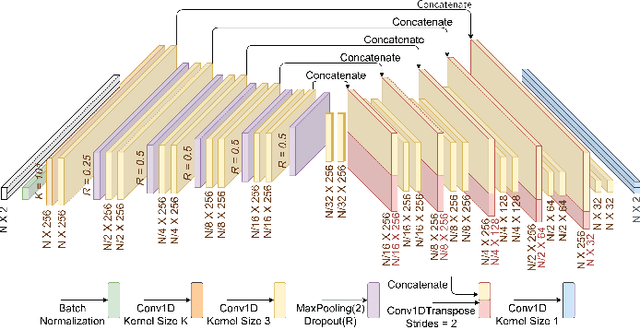
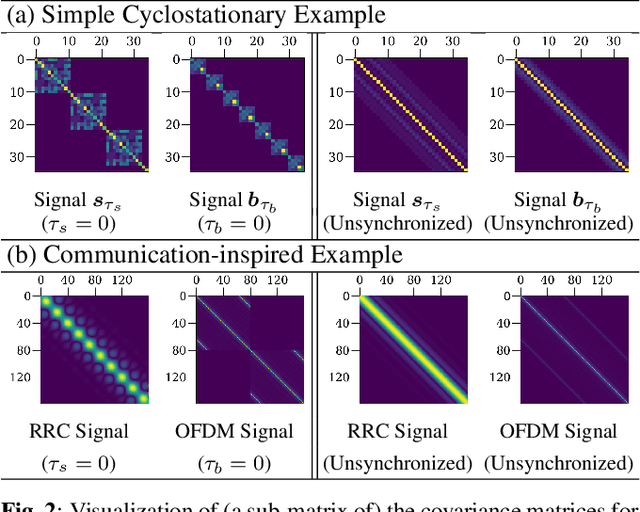
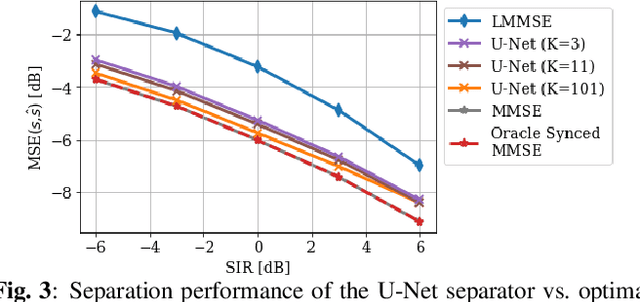
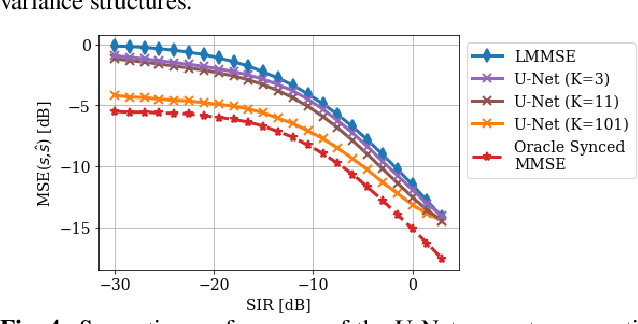
We study the problem of single-channel source separation (SCSS), and focus on cyclostationary signals, which are particularly suitable in a variety of application domains. Unlike classical SCSS approaches, we consider a setting where only examples of the sources are available rather than their models, inspiring a data-driven approach. For source models with underlying cyclostationary Gaussian constituents, we establish a lower bound on the attainable mean squared error (MSE) for any separation method, model-based or data-driven. Our analysis further reveals the operation for optimal separation and the associated implementation challenges. As a computationally attractive alternative, we propose a deep learning approach using a U-Net architecture, which is competitive with the minimum MSE estimator. We demonstrate in simulation that, with suitable domain-informed architectural choices, our U-Net method can approach the optimal performance with substantially reduced computational burden.