 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model-Driven Lossless Compression Algorithm Resistant to Mismatch
Jan 25, 2026Due to the fundamental connection between next-symbol prediction and compression, modern predictive models, such as large language models (LLMs), can be combined with entropy coding to achieve compression rates that surpass those of standard compression algorithms. However, this approach relies on the assumption that the predictive model produces identical output distributions at both the encoder and decoder, since even small mismatches can cause the decoding to fail. This assumption often fails with complex predictive models, particularly those based on neural networks, a phenomenon referred to as non-determinism. In this work, we propose a new compression algorithm based on next-token prediction that is robust to arbitrarily large, but structured, prediction mismatches. We prove the correctness of the proposed scheme under a formal mismatch certification, characterize its theoretical performance, and validate it experimentally on real datasets. Our results demonstrate reliable operation within the certified mismatch regime while achieving compression ratios that exceed those of commonly used compression methods.
Data-Driven Blind Synchronization and Interference Rejection for Digital Communication Signals
Sep 11, 2022



We study the potential of data-driven deep learning methods for separation of two communication signals from an observation of their mixture. In particular, we assume knowledge on the generation process of one of the signals, dubbed signal of interest (SOI), and no knowledge on the generation process of the second signal, referred to as interference. This form of the single-channel source separation problem is also referred to as interference rejection. We show that capturing high-resolution temporal structures (nonstationarities), which enables accurate synchronization to both the SOI and the interference, leads to substantial performance gains. With this key insight, we propose a domain-informed neural network (NN) design that is able to improve upon both "off-the-shelf" NNs and classical detection and interference rejection methods, as demonstrated in our simulations. Our findings highlight the key role communication-specific domain knowledge plays in the development of data-driven approaches that hold the promise of unprecedented gains.
Exploiting Temporal Structures of Cyclostationary Signals for Data-Driven Single-Channel Source Separation
Aug 22, 2022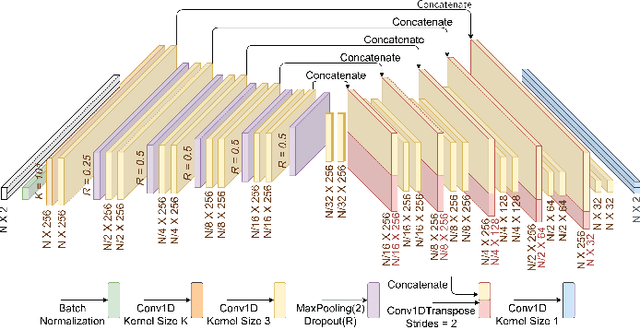
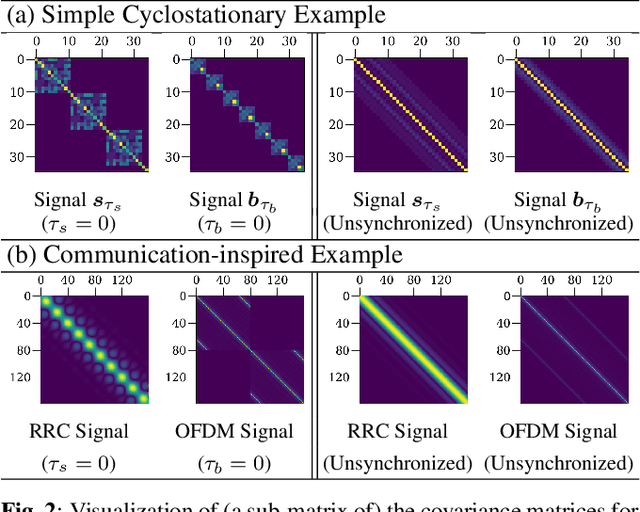
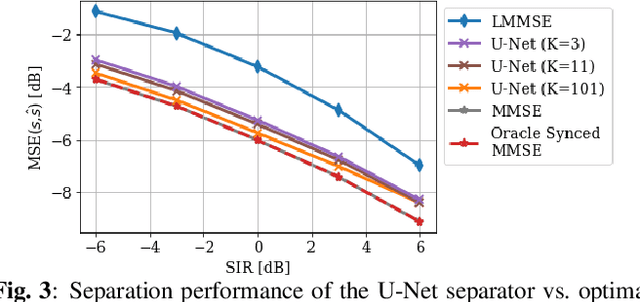
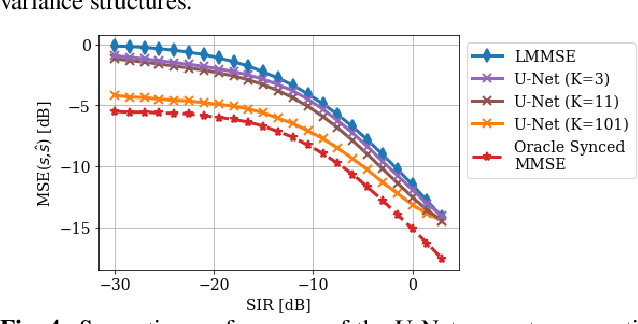
We study the problem of single-channel source separation (SCSS), and focus on cyclostationary signals, which are particularly suitable in a variety of application domains. Unlike classical SCSS approaches, we consider a setting where only examples of the sources are available rather than their models, inspiring a data-driven approach. For source models with underlying cyclostationary Gaussian constituents, we establish a lower bound on the attainable mean squared error (MSE) for any separation method, model-based or data-driven. Our analysis further reveals the operation for optimal separation and the associated implementation challenges. As a computationally attractive alternative, we propose a deep learning approach using a U-Net architecture, which is competitive with the minimum MSE estimator. We demonstrate in simulation that, with suitable domain-informed architectural choices, our U-Net method can approach the optimal performance with substantially reduced computational burden.
Generative Visual Rationales
Apr 04, 2018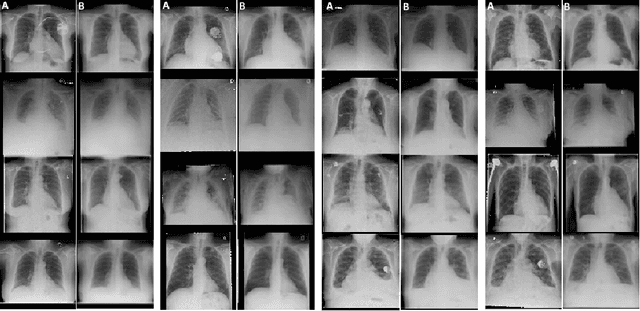
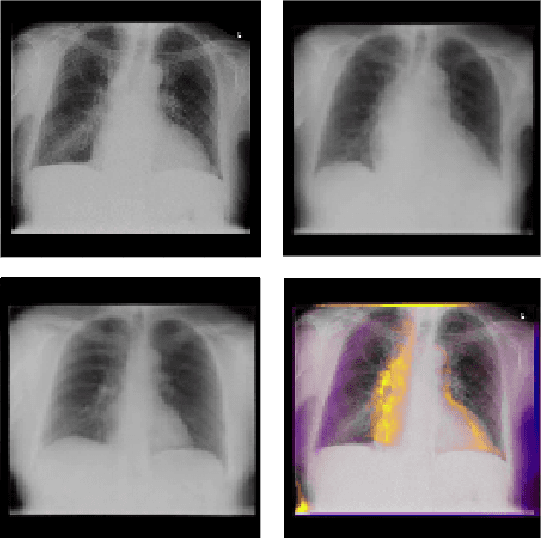
Interpretability and small labelled datasets are key issues in the practical application of deep learning, particularly in areas such as medicine. In this paper, we present a semi-supervised technique that addresses both these issues by leveraging large unlabelled datasets to encode and decode images into a dense latent representation. Using chest radiography as an example, we apply this encoder to other labelled datasets and apply simple models to the latent vectors to learn algorithms to identify heart failure. For each prediction, we generate visual rationales by optimizing a latent representation to minimize the prediction of disease while constrained by a similarity measure in image space. Decoding the resultant latent representation produces an image without apparent disease. The difference between the original decoding and the altered image forms an interpretable visual rationale for the algorithm's prediction on that image. We also apply our method to the MNIST dataset and compare the generated rationales to other techniques described in the literature.