 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriForces: Augmenting Atomistic GNNs for Transferable Representations
May 20, 2026Machine learning interatomic potentials (MLIPs) achieve excellent accuracy when trained on large Density Functional Theory (DFT) data. To be useful in practice, they must often be adapted to target chemistries using small and expensive task-specific datasets. However, MLIPs transfer inconsistently across domains, with representations that often loose accessible composition and structure information. To address this, we present TriForces, a model-agnostic three-stream framework that separates composition and structure information, combined with self-supervised learning to preserve transferable representations. TriForces improves performance on MatBench and QM9 over baselines without needing DFT labels and enables efficient similar structure retrieval through its learned latent space. On OMat24, in limited-data training regime, TriForces reduces energy MAE by 57% at 20K samples only and improves force MAE across sample sizes. We release pretrained TriForces variants across multiple MLIP architectures with code at https://github.com/Ramlaoui/triforces.
ORCAst: Operational High-Resolution Current Forecasts
Jan 21, 2025We present ORCAst, a multi-stage, multi-arm network for Operational high-Resolution Current forecAsts over one week. Producing real-time nowcasts and forecasts of ocean surface currents is a challenging problem due to indirect or incomplete information from satellite remote sensing data. Entirely trained on real satellite data and in situ measurements from drifters, our model learns to forecast global ocean surface currents using various sources of ground truth observations in a multi-stage learning procedure. Our multi-arm encoder-decoder model architecture allows us to first predict sea surface height and geostrophic currents from larger quantities of nadir and SWOT altimetry data, before learning to predict ocean surface currents from much more sparse in situ measurements from drifters. Training our model on specific regions improves performance. Our model achieves stronger nowcast and forecast performance in predicting ocean surface currents than various state-of-the-art methods.
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
May 16, 2024
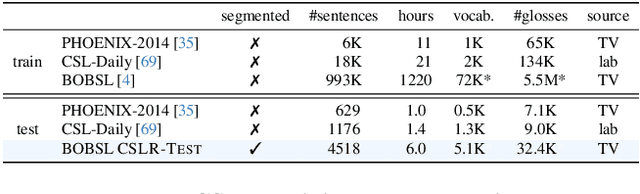
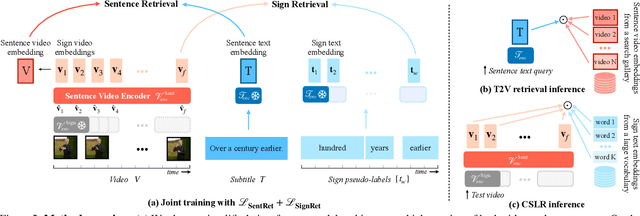

In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Weakly-supervised Fingerspelling Recognition in British Sign Language Videos
Nov 16, 2022



The goal of this work is to detect and recognize sequences of letters signed using fingerspelling in British Sign Language (BSL). Previous fingerspelling recognition methods have not focused on BSL, which has a very different signing alphabet (e.g., two-handed instead of one-handed) to American Sign Language (ASL). They also use manual annotations for training. In contrast to previous methods, our method only uses weak annotations from subtitles for training. We localize potential instances of fingerspelling using a simple feature similarity method, then automatically annotate these instances by querying subtitle words and searching for corresponding mouthing cues from the signer. We propose a Transformer architecture adapted to this task, with a multiple-hypothesis CTC loss function to learn from alternative annotation possibilities. We employ a multi-stage training approach, where we make use of an initial version of our trained model to extend and enhance our training data before re-training again to achieve better performance. Through extensive evaluations, we verify our method for automatic annotation and our model architecture. Moreover, we provide a human expert annotated test set of 5K video clips for evaluating BSL fingerspelling recognition methods to support sign language research.
Automatic dense annotation of large-vocabulary sign language videos
Aug 04, 2022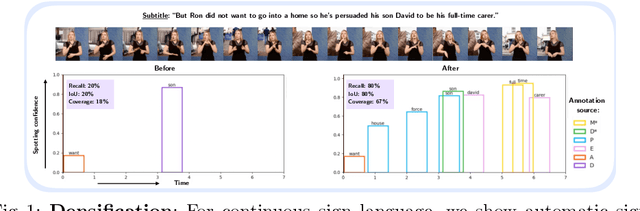

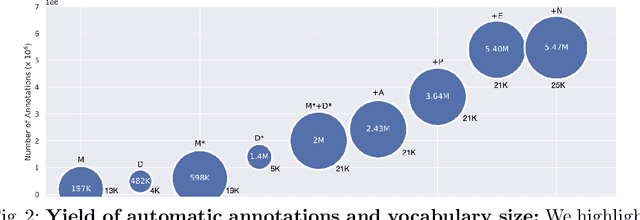
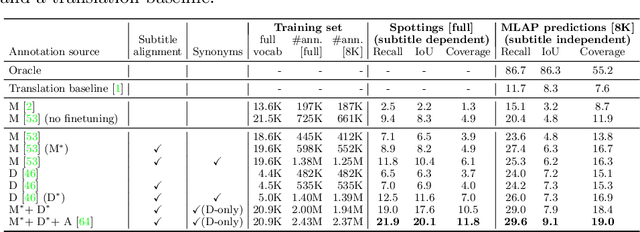
Recently, sign language researchers have turned to sign language interpreted TV broadcasts, comprising (i) a video of continuous signing and (ii) subtitles corresponding to the audio content, as a readily available and large-scale source of training data. One key challenge in the usability of such data is the lack of sign annotations. Previous work exploiting such weakly-aligned data only found sparse correspondences between keywords in the subtitle and individual signs. In this work, we propose a simple, scalable framework to vastly increase the density of automatic annotations. Our contributions are the following: (1) we significantly improve previous annotation methods by making use of synonyms and subtitle-signing alignment; (2) we show the value of pseudo-labelling from a sign recognition model as a way of sign spotting; (3) we propose a novel approach for increasing our annotations of known and unknown classes based on in-domain exemplars; (4) on the BOBSL BSL sign language corpus, we increase the number of confident automatic annotations from 670K to 5M. We make these annotations publicly available to support the sign language research community.
BBC-Oxford British Sign Language Dataset
Nov 05, 2021

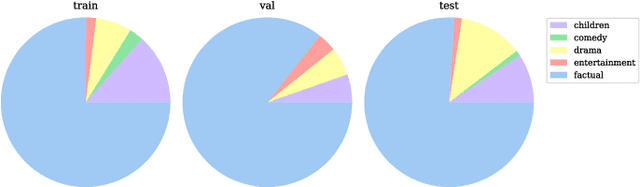
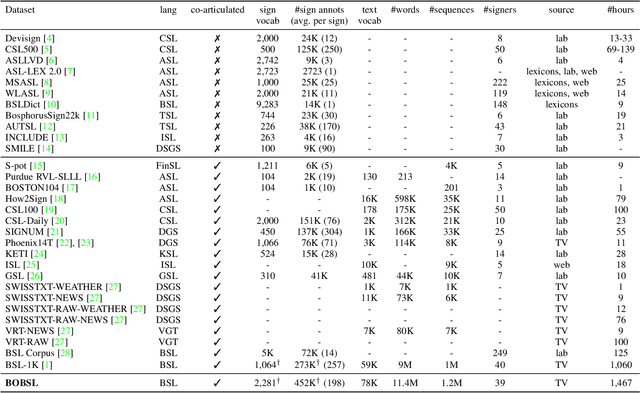
In this work, we introduce the BBC-Oxford British Sign Language (BOBSL) dataset, a large-scale video collection of British Sign Language (BSL). BOBSL is an extended and publicly released dataset based on the BSL-1K dataset introduced in previous work. We describe the motivation for the dataset, together with statistics and available annotations. We conduct experiments to provide baselines for the tasks of sign recognition, sign language alignment, and sign language translation. Finally, we describe several strengths and limitations of the data from the perspectives of machine learning and linguistics, note sources of bias present in the dataset, and discuss potential applications of BOBSL in the context of sign language technology. The dataset is available at https://www.robots.ox.ac.uk/~vgg/data/bobsl/.
Aligning Subtitles in Sign Language Videos
May 06, 2021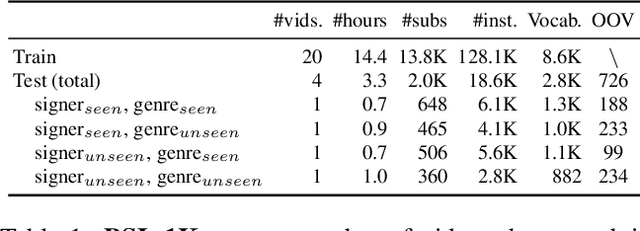
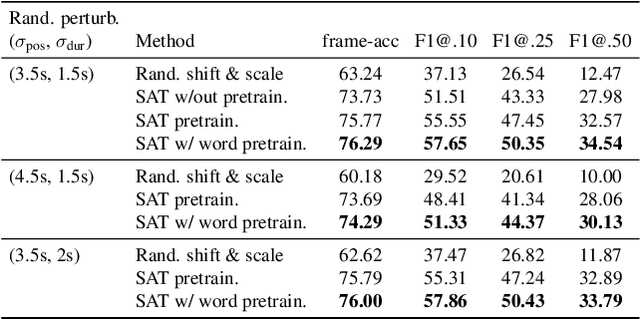
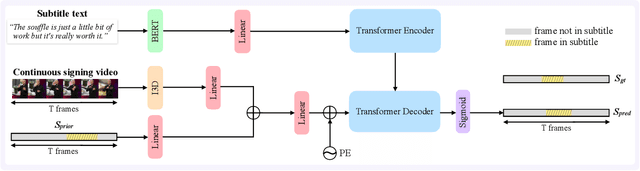
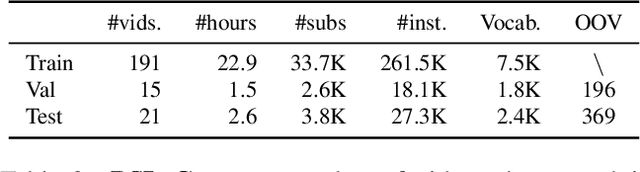
The goal of this work is to temporally align asynchronous subtitles in sign language videos. In particular, we focus on sign-language interpreted TV broadcast data comprising (i) a video of continuous signing, and (ii) subtitles corresponding to the audio content. Previous work exploiting such weakly-aligned data only considered finding keyword-sign correspondences, whereas we aim to localise a complete subtitle text in continuous signing. We propose a Transformer architecture tailored for this task, which we train on manually annotated alignments covering over 15K subtitles that span 17.7 hours of video. We use BERT subtitle embeddings and CNN video representations learned for sign recognition to encode the two signals, which interact through a series of attention layers. Our model outputs frame-level predictions, i.e., for each video frame, whether it belongs to the queried subtitle or not. Through extensive evaluations, we show substantial improvements over existing alignment baselines that do not make use of subtitle text embeddings for learning. Our automatic alignment model opens up possibilities for advancing machine translation of sign languages via providing continuously synchronized video-text data.