 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
Paper and Code

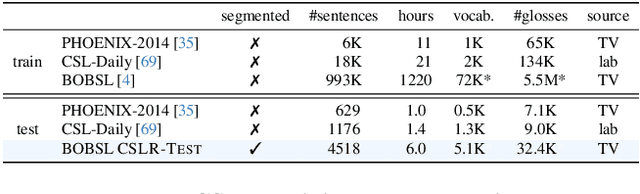
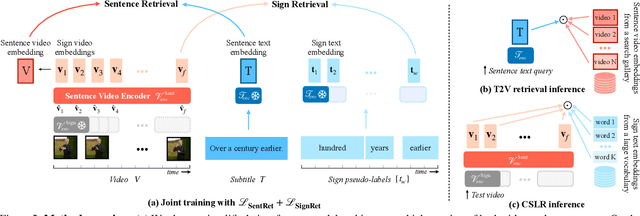

In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.