 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect Collisions for Continuum Manipulators without a Prior Model
Aug 12, 2019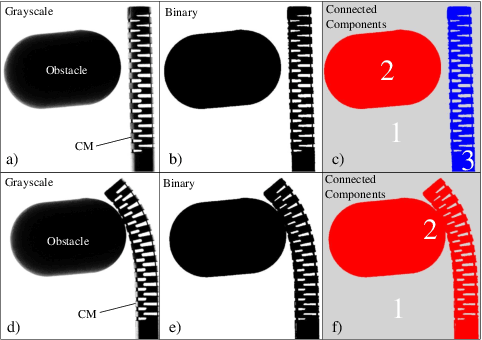
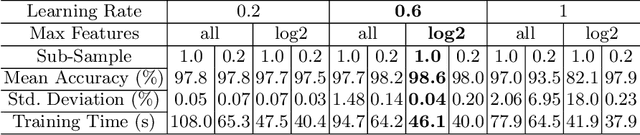
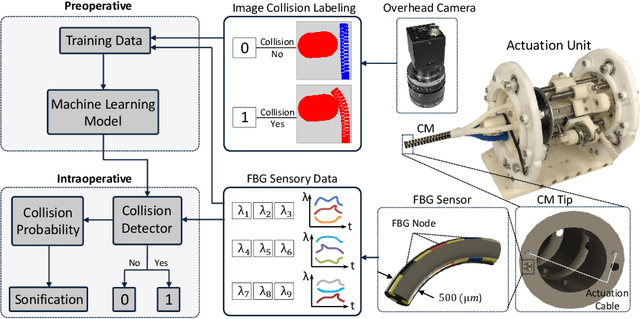
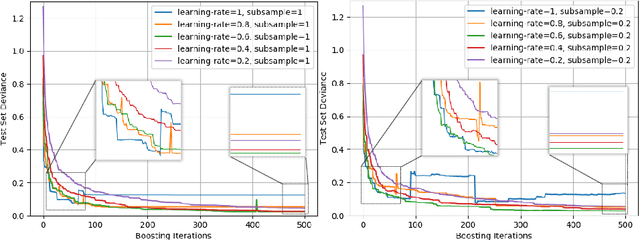
Due to their flexibility, dexterity, and compact size, Continuum Manipulators (CMs) can enhance minimally invasive interventions. In these procedures, the CM may be operated in proximity of sensitive organs; therefore, requiring accurate and appropriate feedback when colliding with their surroundings. Conventional CM collision detection algorithms rely on a combination of exact CM constrained kinematics model, geometrical assumptions such as constant curvature behavior, a priori knowledge of the environmental constraint geometry, and/or additional sensors to scan the environment or sense contacts. In this paper, we propose a data-driven machine learning approach using only the available sensory information, without requiring any prior geometrical assumptions, model of the CM or the surrounding environment. The proposed algorithm is implemented and evaluated on a non-constant curvature CM, equipped with Fiber Bragg Grating (FBG) optical sensors for shape sensing purposes. Results demonstrate successful detection of collisions in constrained environments with soft and hard obstacles with unknown stiffness and location.
End-to-End Fine-Grained Action Segmentation and Recognition Using Conditional Random Field Models and Discriminative Sparse Coding
Jan 29, 2018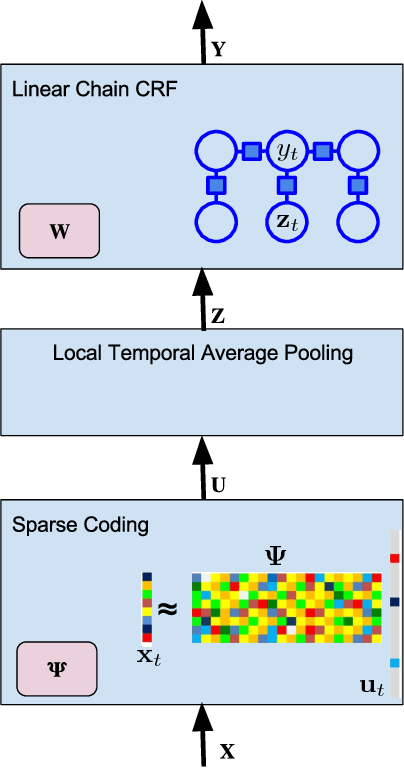
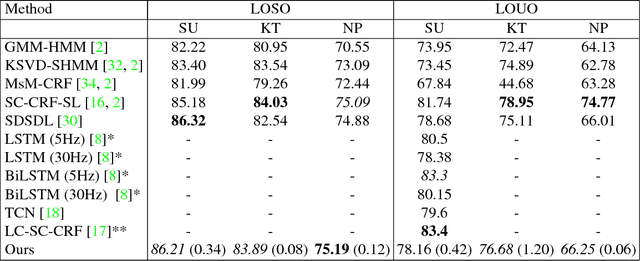
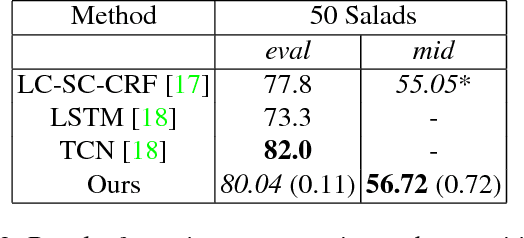
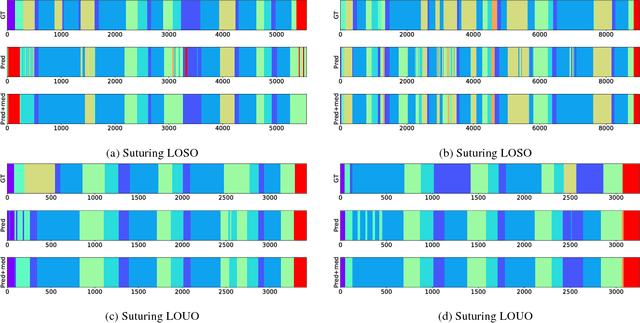
Fine-grained action segmentation and recognition is an important yet challenging task. Given a long, untrimmed sequence of kinematic data, the task is to classify the action at each time frame and segment the time series into the correct sequence of actions. In this paper, we propose a novel framework that combines a temporal Conditional Random Field (CRF) model with a powerful frame-level representation based on discriminative sparse coding. We introduce an end-to-end algorithm for jointly learning the weights of the CRF model, which include action classification and action transition costs, as well as an overcomplete dictionary of mid-level action primitives. This results in a CRF model that is driven by sparse coding features obtained using a discriminative dictionary that is shared among different actions and adapted to the task of structured output learning. We evaluate our method on three surgical tasks using kinematic data from the JIGSAWS dataset, as well as on a food preparation task using accelerometer data from the 50 Salads dataset. Our results show that the proposed method performs on par or better than state-of-the-art methods.