 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation
Oct 30, 2024



Human beings are endowed with a complementary learning system, which bridges the slow learning of general world dynamics with fast storage of episodic memory from a new experience. Previous video generation models, however, primarily focus on slow learning by pre-training on vast amounts of data, overlooking the fast learning phase crucial for episodic memory storage. This oversight leads to inconsistencies across temporally distant frames when generating longer videos, as these frames fall beyond the model's context window. To this end, we introduce SlowFast-VGen, a novel dual-speed learning system for action-driven long video generation. Our approach incorporates a masked conditional video diffusion model for the slow learning of world dynamics, alongside an inference-time fast learning strategy based on a temporal LoRA module. Specifically, the fast learning process updates its temporal LoRA parameters based on local inputs and outputs, thereby efficiently storing episodic memory in its parameters. We further propose a slow-fast learning loop algorithm that seamlessly integrates the inner fast learning loop into the outer slow learning loop, enabling the recall of prior multi-episode experiences for context-aware skill learning. To facilitate the slow learning of an approximate world model, we collect a large-scale dataset of 200k videos with language action annotations, covering a wide range of scenarios. Extensive experiments show that SlowFast-VGen outperforms baselines across various metrics for action-driven video generation, achieving an FVD score of 514 compared to 782, and maintaining consistency in longer videos, with an average of 0.37 scene cuts versus 0.89. The slow-fast learning loop algorithm significantly enhances performances on long-horizon planning tasks as well. Project Website: https://slowfast-vgen.github.io
IDOL: Unified Dual-Modal Latent Diffusion for Human-Centric Joint Video-Depth Generation
Jul 15, 2024

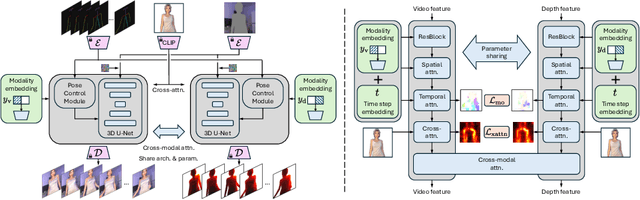

Significant advances have been made in human-centric video generation, yet the joint video-depth generation problem remains underexplored. Most existing monocular depth estimation methods may not generalize well to synthesized images or videos, and multi-view-based methods have difficulty controlling the human appearance and motion. In this work, we present IDOL (unIfied Dual-mOdal Latent diffusion) for high-quality human-centric joint video-depth generation. Our IDOL consists of two novel designs. First, to enable dual-modal generation and maximize the information exchange between video and depth generation, we propose a unified dual-modal U-Net, a parameter-sharing framework for joint video and depth denoising, wherein a modality label guides the denoising target, and cross-modal attention enables the mutual information flow. Second, to ensure a precise video-depth spatial alignment, we propose a motion consistency loss that enforces consistency between the video and depth feature motion fields, leading to harmonized outputs. Additionally, a cross-attention map consistency loss is applied to align the cross-attention map of the video denoising with that of the depth denoising, further facilitating spatial alignment. Extensive experiments on the TikTok and NTU120 datasets show our superior performance, significantly surpassing existing methods in terms of video FVD and depth accuracy.
Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation
Jun 11, 2024Image diffusion distillation achieves high-fidelity generation with very few sampling steps. However, applying these techniques directly to video diffusion often results in unsatisfactory frame quality due to the limited visual quality in public video datasets. This affects the performance of both teacher and student video diffusion models. Our study aims to improve video diffusion distillation while improving frame appearance using abundant high-quality image data. We propose motion consistency model (MCM), a single-stage video diffusion distillation method that disentangles motion and appearance learning. Specifically, MCM includes a video consistency model that distills motion from the video teacher model, and an image discriminator that enhances frame appearance to match high-quality image data. This combination presents two challenges: (1) conflicting frame learning objectives, as video distillation learns from low-quality video frames while the image discriminator targets high-quality images; and (2) training-inference discrepancies due to the differing quality of video samples used during training and inference. To address these challenges, we introduce disentangled motion distillation and mixed trajectory distillation. The former applies the distillation objective solely to the motion representation, while the latter mitigates training-inference discrepancies by mixing distillation trajectories from both the low- and high-quality video domains. Extensive experiments show that our MCM achieves the state-of-the-art video diffusion distillation performance. Additionally, our method can enhance frame quality in video diffusion models, producing frames with high aesthetic scores or specific styles without corresponding video data.
STAT: Towards Generalizable Temporal Action Localization
Apr 20, 2024



Weakly-supervised temporal action localization (WTAL) aims to recognize and localize action instances with only video-level labels. Despite the significant progress, existing methods suffer from severe performance degradation when transferring to different distributions and thus may hardly adapt to real-world scenarios . To address this problem, we propose the Generalizable Temporal Action Localization task (GTAL), which focuses on improving the generalizability of action localization methods. We observed that the performance decline can be primarily attributed to the lack of generalizability to different action scales. To address this problem, we propose STAT (Self-supervised Temporal Adaptive Teacher), which leverages a teacher-student structure for iterative refinement. Our STAT features a refinement module and an alignment module. The former iteratively refines the model's output by leveraging contextual information and helps adapt to the target scale. The latter improves the refinement process by promoting a consensus between student and teacher models. We conduct extensive experiments on three datasets, THUMOS14, ActivityNet1.2, and HACS, and the results show that our method significantly improves the Baseline methods under the cross-distribution evaluation setting, even approaching the same-distribution evaluation performance.
SOAR: Scene-debiasing Open-set Action Recognition
Sep 03, 2023

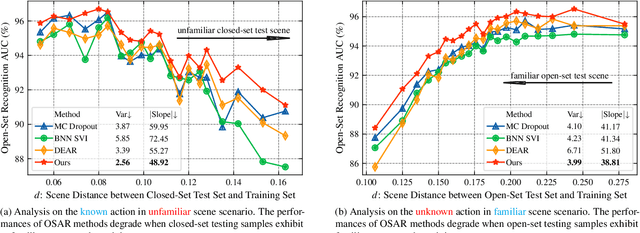

Deep learning models have a risk of utilizing spurious clues to make predictions, such as recognizing actions based on the background scene. This issue can severely degrade the open-set action recognition performance when the testing samples have different scene distributions from the training samples. To mitigate this problem, we propose a novel method, called Scene-debiasing Open-set Action Recognition (SOAR), which features an adversarial scene reconstruction module and an adaptive adversarial scene classification module. The former prevents the decoder from reconstructing the video background given video features, and thus helps reduce the background information in feature learning. The latter aims to confuse scene type classification given video features, with a specific emphasis on the action foreground, and helps to learn scene-invariant information. In addition, we design an experiment to quantify the scene bias. The results indicate that the current open-set action recognizers are biased toward the scene, and our proposed SOAR method better mitigates such bias. Furthermore, our extensive experiments demonstrate that our method outperforms state-of-the-art methods, and the ablation studies confirm the effectiveness of our proposed modules.
Towards Generic Image Manipulation Detection with Weakly-Supervised Self-Consistency Learning
Sep 03, 2023As advanced image manipulation techniques emerge, detecting the manipulation becomes increasingly important. Despite the success of recent learning-based approaches for image manipulation detection, they typically require expensive pixel-level annotations to train, while exhibiting degraded performance when testing on images that are differently manipulated compared with training images. To address these limitations, we propose weakly-supervised image manipulation detection, such that only binary image-level labels (authentic or tampered with) are required for training purpose. Such a weakly-supervised setting can leverage more training images and has the potential to adapt quickly to new manipulation techniques. To improve the generalization ability, we propose weakly-supervised self-consistency learning (WSCL) to leverage the weakly annotated images. Specifically, two consistency properties are learned: multi-source consistency (MSC) and inter-patch consistency (IPC). MSC exploits different content-agnostic information and enables cross-source learning via an online pseudo label generation and refinement process. IPC performs global pair-wise patch-patch relationship reasoning to discover a complete region of manipulation. Extensive experiments validate that our WSCL, even though is weakly supervised, exhibits competitive performance compared with fully-supervised counterpart under both in-distribution and out-of-distribution evaluations, as well as reasonable manipulation localization ability.
Language-guided Human Motion Synthesis with Atomic Actions
Aug 18, 2023Language-guided human motion synthesis has been a challenging task due to the inherent complexity and diversity of human behaviors. Previous methods face limitations in generalization to novel actions, often resulting in unrealistic or incoherent motion sequences. In this paper, we propose ATOM (ATomic mOtion Modeling) to mitigate this problem, by decomposing actions into atomic actions, and employing a curriculum learning strategy to learn atomic action composition. First, we disentangle complex human motions into a set of atomic actions during learning, and then assemble novel actions using the learned atomic actions, which offers better adaptability to new actions. Moreover, we introduce a curriculum learning training strategy that leverages masked motion modeling with a gradual increase in the mask ratio, and thus facilitates atomic action assembly. This approach mitigates the overfitting problem commonly encountered in previous methods while enforcing the model to learn better motion representations. We demonstrate the effectiveness of ATOM through extensive experiments, including text-to-motion and action-to-motion synthesis tasks. We further illustrate its superiority in synthesizing plausible and coherent text-guided human motion sequences.
High Fidelity 3D Hand Shape Reconstruction via Scalable Graph Frequency Decomposition
Jul 08, 2023
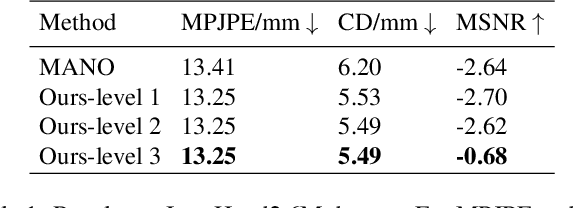

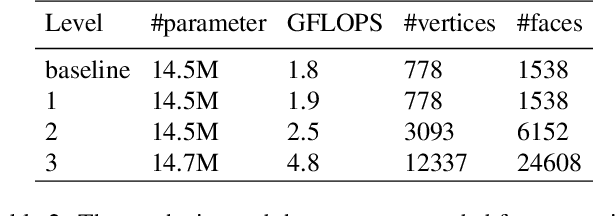
Despite the impressive performance obtained by recent single-image hand modeling techniques, they lack the capability to capture sufficient details of the 3D hand mesh. This deficiency greatly limits their applications when high-fidelity hand modeling is required, e.g., personalized hand modeling. To address this problem, we design a frequency split network to generate 3D hand mesh using different frequency bands in a coarse-to-fine manner. To capture high-frequency personalized details, we transform the 3D mesh into the frequency domain, and propose a novel frequency decomposition loss to supervise each frequency component. By leveraging such a coarse-to-fine scheme, hand details that correspond to the higher frequency domain can be preserved. In addition, the proposed network is scalable, and can stop the inference at any resolution level to accommodate different hardware with varying computational powers. To quantitatively evaluate the performance of our method in terms of recovering personalized shape details, we introduce a new evaluation metric named Mean Signal-to-Noise Ratio (MSNR) to measure the signal-to-noise ratio of each mesh frequency component. Extensive experiments demonstrate that our approach generates fine-grained details for high-fidelity 3D hand reconstruction, and our evaluation metric is more effective for measuring mesh details compared with traditional metrics.
* CVPR 2023
Two-Stream Consensus Network: Submission to HACS Challenge 2021 Weakly-Supervised Learning Track
Jul 11, 2021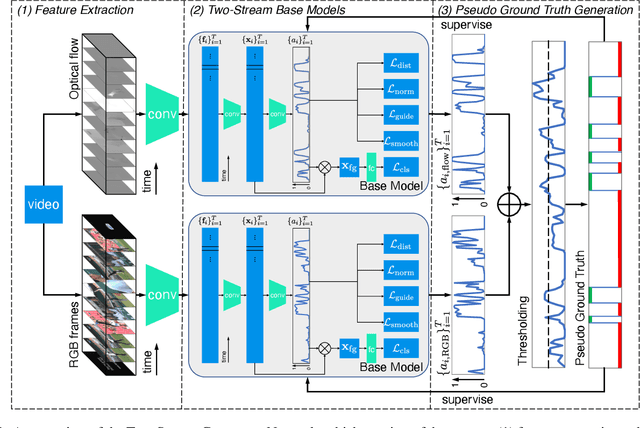
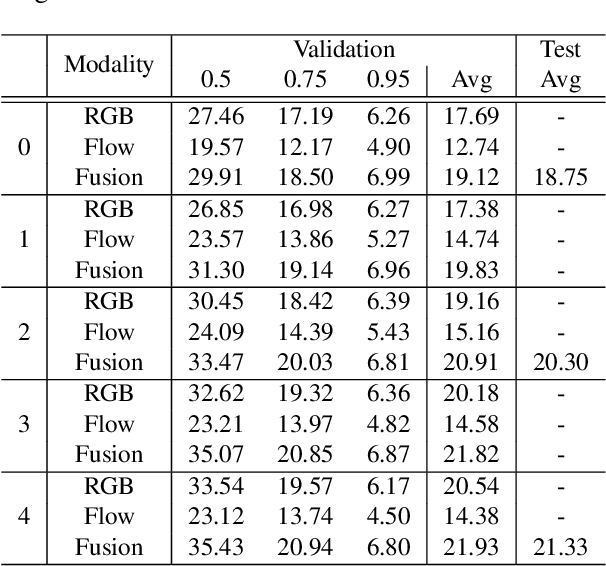
This technical report presents our solution to the HACS Temporal Action Localization Challenge 2021, Weakly-Supervised Learning Track. The goal of weakly-supervised temporal action localization is to temporally locate and classify action of interest in untrimmed videos given only video-level labels. We adopt the two-stream consensus network (TSCN) as the main framework in this challenge. The TSCN consists of a two-stream base model training procedure and a pseudo ground truth learning procedure. The base model training encourages the model to predict reliable predictions based on single modality (i.e., RGB or optical flow), based on the fusion of which a pseudo ground truth is generated and in turn used as supervision to train the base models. On the HACS v1.1.1 dataset, without fine-tuning the feature-extraction I3D models, our method achieves 22.20% on the validation set and 21.68% on the testing set in terms of average mAP. Our solution ranked the 2rd in this challenge, and we hope our method can serve as a baseline for future academic research.
Two-Stream Consensus Network for Weakly-Supervised Temporal Action Localization
Oct 22, 2020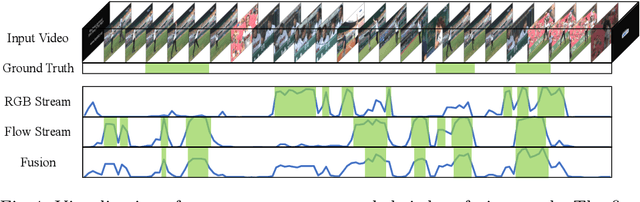
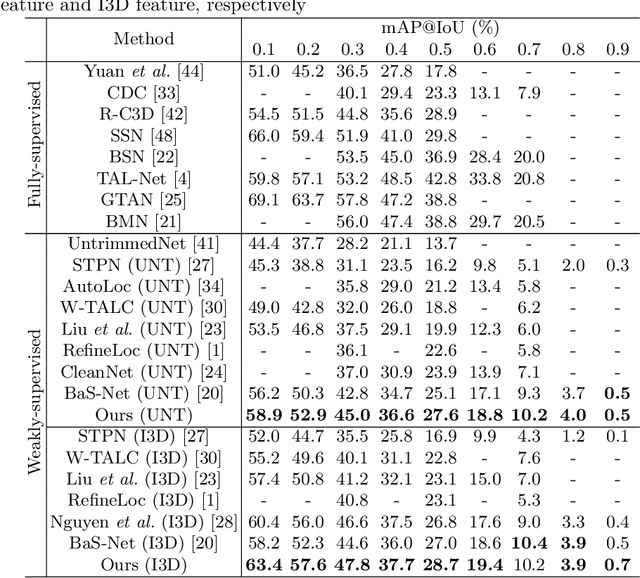


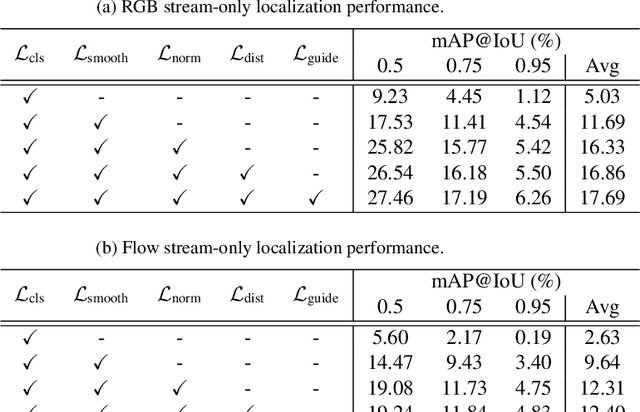
Weakly-supervised Temporal Action Localization (W-TAL) aims to classify and localize all action instances in an untrimmed video under only video-level supervision. However, without frame-level annotations, it is challenging for W-TAL methods to identify false positive action proposals and generate action proposals with precise temporal boundaries. In this paper, we present a Two-Stream Consensus Network (TSCN) to simultaneously address these challenges. The proposed TSCN features an iterative refinement training method, where a frame-level pseudo ground truth is iteratively updated, and used to provide frame-level supervision for improved model training and false positive action proposal elimination. Furthermore, we propose a new attention normalization loss to encourage the predicted attention to act like a binary selection, and promote the precise localization of action instance boundaries. Experiments conducted on the THUMOS14 and ActivityNet datasets show that the proposed TSCN outperforms current state-of-the-art methods, and even achieves comparable results with some recent fully-supervised methods.