 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDOL: Unified Dual-Modal Latent Diffusion for Human-Centric Joint Video-Depth Generation
Paper and Code


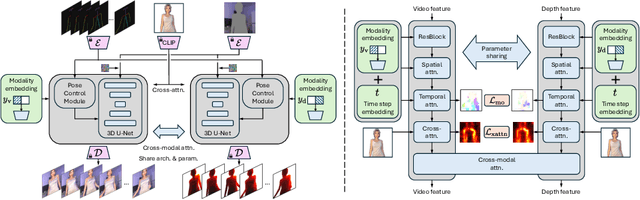

Significant advances have been made in human-centric video generation, yet the joint video-depth generation problem remains underexplored. Most existing monocular depth estimation methods may not generalize well to synthesized images or videos, and multi-view-based methods have difficulty controlling the human appearance and motion. In this work, we present IDOL (unIfied Dual-mOdal Latent diffusion) for high-quality human-centric joint video-depth generation. Our IDOL consists of two novel designs. First, to enable dual-modal generation and maximize the information exchange between video and depth generation, we propose a unified dual-modal U-Net, a parameter-sharing framework for joint video and depth denoising, wherein a modality label guides the denoising target, and cross-modal attention enables the mutual information flow. Second, to ensure a precise video-depth spatial alignment, we propose a motion consistency loss that enforces consistency between the video and depth feature motion fields, leading to harmonized outputs. Additionally, a cross-attention map consistency loss is applied to align the cross-attention map of the video denoising with that of the depth denoising, further facilitating spatial alignment. Extensive experiments on the TikTok and NTU120 datasets show our superior performance, significantly surpassing existing methods in terms of video FVD and depth accuracy.