 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect and Weight: A Simple Yet Effective Loss for Implicit Feedback Recommendation
Jan 07, 2026Learning from implicit feedback has become the standard paradigm for modern recommender systems. However, this setting is fraught with the persistent challenge of false negatives, where unobserved user-item interactions are not necessarily indicative of negative preference. To address this issue, this paper introduces a novel and principled loss function, named Corrected and Weighted (CW) loss, that systematically corrects for the impact of false negatives within the training objective. Our approach integrates two key techniques. First, inspired by Positive-Unlabeled learning, we debias the negative sampling process by re-calibrating the assumed negative distribution. By theoretically approximating the true negative distribution (p-) using the observable general data distribution (p) and the positive interaction distribution (p^+), our method provides a more accurate estimate of the likelihood that a sampled unlabeled item is truly negative. Second, we introduce a dynamic re-weighting mechanism that modulates the importance of each negative instance based on the model's current prediction. This scheme encourages the model to enforce a larger ranking margin between positive items and confidently predicted (i.e., easy) negative items, while simultaneously down-weighting the penalty on uncertain negatives that have a higher probability of being false negatives. A key advantage of our approach is its elegance and efficiency; it requires no complex modifications to the data sampling process or significant computational overhead, making it readily applicable to a wide array of existing recommendation models. Extensive experiments conducted on four large-scale, sparse benchmark datasets demonstrate the superiority of our proposed loss. The results show that our method consistently and significantly outperforms a suite of state-of-the-art loss functions across multiple ranking-oriented metrics.
Multimodal Chain-of-Thought Reasoning via ChatGPT to Protect Children from Age-Inappropriate Apps
Jul 08, 2024



Mobile applications (Apps) could expose children to inappropriate themes such as sexual content, violence, and drug use. Maturity rating offers a quick and effective method for potential users, particularly guardians, to assess the maturity levels of apps. Determining accurate maturity ratings for mobile apps is essential to protect children's health in today's saturated digital marketplace. Existing approaches to maturity rating are either inaccurate (e.g., self-reported rating by developers) or costly (e.g., manual examination). In the literature, there are few text-mining-based approaches to maturity rating. However, each app typically involves multiple modalities, namely app description in the text, and screenshots in the image. In this paper, we present a framework for determining app maturity levels that utilize multimodal large language models (MLLMs), specifically ChatGPT-4 Vision. Powered by Chain-of-Thought (CoT) reasoning, our framework systematically leverages ChatGPT-4 to process multimodal app data (i.e., textual descriptions and screenshots) and guide the MLLM model through a step-by-step reasoning pathway from initial content analysis to final maturity rating determination. As a result, through explicitly incorporating CoT reasoning, our framework enables ChatGPT to understand better and apply maturity policies to facilitate maturity rating. Experimental results indicate that the proposed method outperforms all baseline models and other fusion strategies.
Securing Visually-Aware Recommender Systems: An Adversarial Image Reconstruction and Detection Framework
Jun 11, 2023


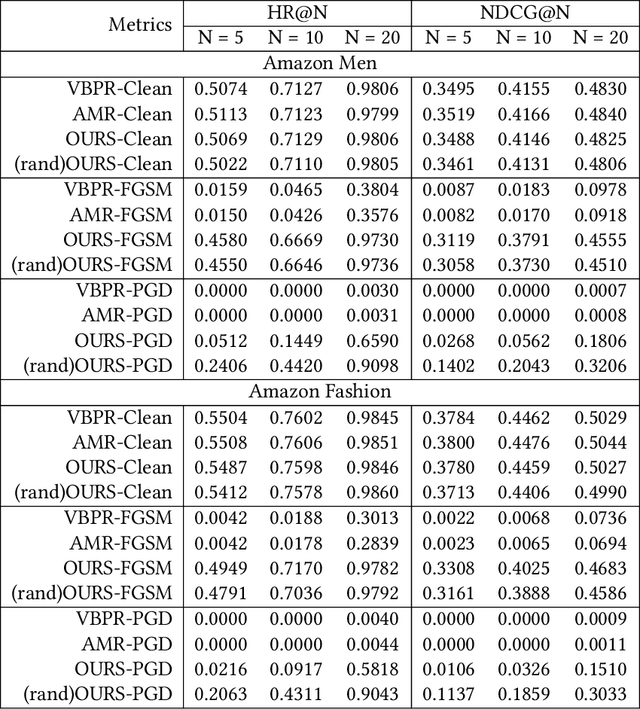
With rich visual data, such as images, becoming readily associated with items, visually-aware recommendation systems (VARS) have been widely used in different applications. Recent studies have shown that VARS are vulnerable to item-image adversarial attacks, which add human-imperceptible perturbations to the clean images associated with those items. Attacks on VARS pose new security challenges to a wide range of applications such as e-Commerce and social networks where VARS are widely used. How to secure VARS from such adversarial attacks becomes a critical problem. Currently, there is still a lack of systematic study on how to design secure defense strategies against visual attacks on VARS. In this paper, we attempt to fill this gap by proposing an adversarial image reconstruction and detection framework to secure VARS. Our proposed method can simultaneously (1) secure VARS from adversarial attacks characterized by local perturbations by image reconstruction based on global vision transformers; and (2) accurately detect adversarial examples using a novel contrastive learning approach. Meanwhile, our framework is designed to be used as both a filter and a detector so that they can be jointly trained to improve the flexibility of our defense strategy to a variety of attacks and VARS models. We have conducted extensive experimental studies with two popular attack methods (FGSM and PGD). Our experimental results on two real-world datasets show that our defense strategy against visual attacks is effective and outperforms existing methods on different attacks. Moreover, our method can detect adversarial examples with high accuracy.
Detection of Illicit Drug Trafficking Events on Instagram: A Deep Multimodal Multilabel Learning Approach
Aug 23, 2021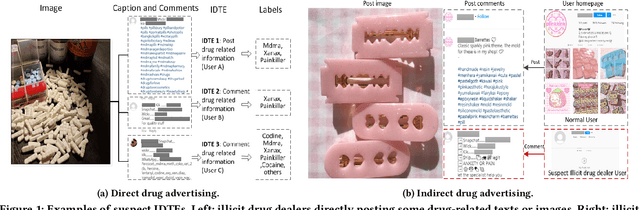


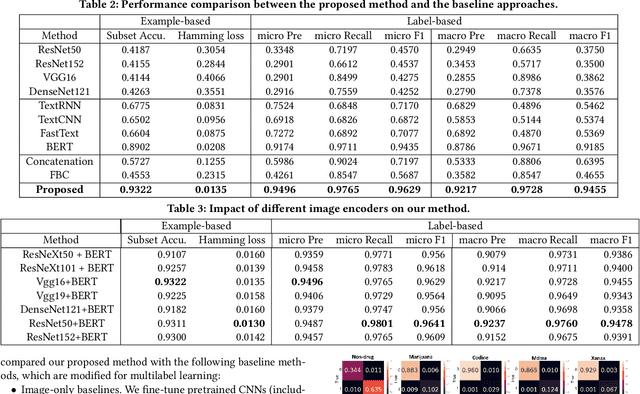
Social media such as Instagram and Twitter have become important platforms for marketing and selling illicit drugs. Detection of online illicit drug trafficking has become critical to combat the online trade of illicit drugs. However, the legal status often varies spatially and temporally; even for the same drug, federal and state legislation can have different regulations about its legality. Meanwhile, more drug trafficking events are disguised as a novel form of advertising commenting leading to information heterogeneity. Accordingly, accurate detection of illicit drug trafficking events (IDTEs) from social media has become even more challenging. In this work, we conduct the first systematic study on fine-grained detection of IDTEs on Instagram. We propose to take a deep multimodal multilabel learning (DMML) approach to detect IDTEs and demonstrate its effectiveness on a newly constructed dataset called multimodal IDTE(MM-IDTE). Specifically, our model takes text and image data as the input and combines multimodal information to predict multiple labels of illicit drugs. Inspired by the success of BERT, we have developed a self-supervised multimodal bidirectional transformer by jointly fine-tuning pretrained text and image encoders. We have constructed a large-scale dataset MM-IDTE with manually annotated multiple drug labels to support fine-grained detection of illicit drugs. Extensive experimental results on the MM-IDTE dataset show that the proposed DMML methodology can accurately detect IDTEs even in the presence of special characters and style changes attempting to evade detection.
Identifying Illicit Drug Dealers on Instagram with Large-scale Multimodal Data Fusion
Aug 23, 2021

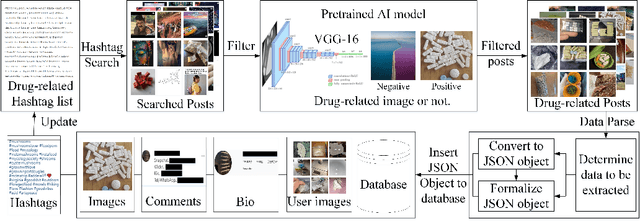

Illicit drug trafficking via social media sites such as Instagram has become a severe problem, thus drawing a great deal of attention from law enforcement and public health agencies. How to identify illicit drug dealers from social media data has remained a technical challenge due to the following reasons. On the one hand, the available data are limited because of privacy concerns with crawling social media sites; on the other hand, the diversity of drug dealing patterns makes it difficult to reliably distinguish drug dealers from common drug users. Unlike existing methods that focus on posting-based detection, we propose to tackle the problem of illicit drug dealer identification by constructing a large-scale multimodal dataset named Identifying Drug Dealers on Instagram (IDDIG). Totally nearly 4,000 user accounts, of which over 1,400 are drug dealers, have been collected from Instagram with multiple data sources including post comments, post images, homepage bio, and homepage images. We then design a quadruple-based multimodal fusion method to combine the multiple data sources associated with each user account for drug dealer identification. Experimental results on the constructed IDDIG dataset demonstrate the effectiveness of the proposed method in identifying drug dealers (almost 95% accuracy). Moreover, we have developed a hashtag-based community detection technique for discovering evolving patterns, especially those related to geography and drug types.
Face Beautification: Beyond Makeup Transfer
Dec 11, 2019
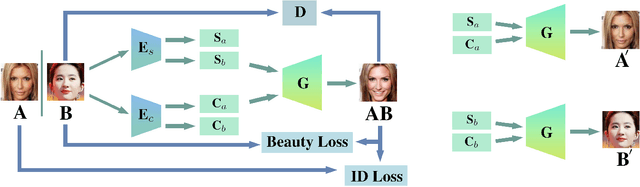

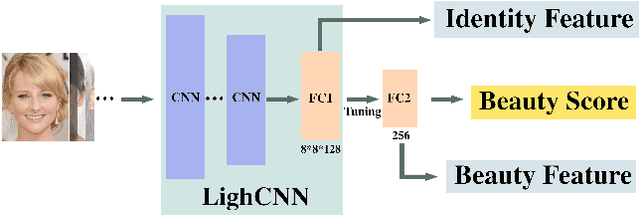
Facial appearance plays an important role in our social lives. Subjective perception of women's beauty depends on various face-related (e.g., skin, shape, hair) and environmental (e.g., makeup, lighting, angle) factors. Similar to cosmetic surgery in the physical world, virtual face beautification is an emerging field with many open issues to be addressed. Inspired by the latest advances in style-based synthesis and face beauty prediction, we propose a novel framework of face beautification. For a given reference face with a high beauty score, our GAN-based architecture is capable of translating an inquiry face into a sequence of beautified face images with referenced beauty style and targeted beauty score values. To achieve this objective, we propose to integrate both style-based beauty representation (extracted from the reference face) and beauty score prediction (trained on SCUT-FBP database) into the process of beautification. Unlike makeup transfer, our approach targets at many-to-many (instead of one-to-one) translation where multiple outputs can be defined by either different references or varying beauty scores. Extensive experimental results are reported to demonstrate the effectiveness and flexibility of the proposed face beautification framework.