 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
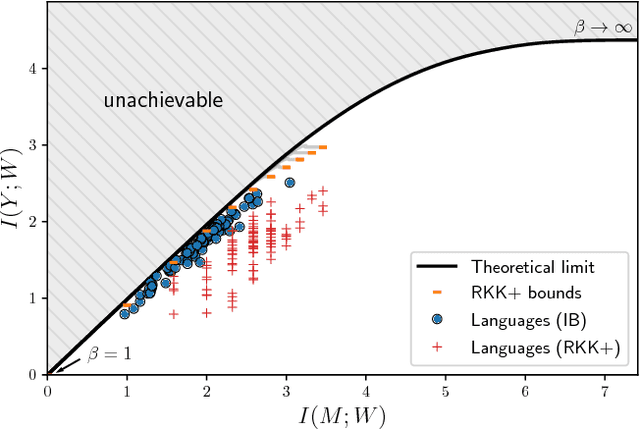
Add to EdgeWord reuse and combination support efficient communication of emerging concepts
Nov 08, 2024A key function of the lexicon is to express novel concepts as they emerge over time through a process known as lexicalization. The most common lexicalization strategies are the reuse and combination of existing words, but they have typically been studied separately in the areas of word meaning extension and word formation. Here we offer an information-theoretic account of how both strategies are constrained by a fundamental tradeoff between competing communicative pressures: word reuse tends to preserve the average length of word forms at the cost of less precision, while word combination tends to produce more informative words at the expense of greater word length. We test our proposal against a large dataset of reuse items and compounds that appeared in English, French and Finnish over the past century. We find that these historically emerging items achieve higher levels of communicative efficiency than hypothetical ways of constructing the lexicon, and both literal reuse items and compounds tend to be more efficient than their non-literal counterparts. These results suggest that reuse and combination are both consistent with a unified account of lexicalization grounded in the theory of efficient communication.
* Published in Proceedings of the National Academy of Sciences
Simpson's Paradox and the Accuracy-Fluency Tradeoff in Translation
Feb 20, 2024
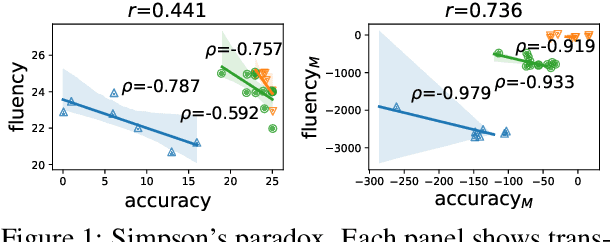
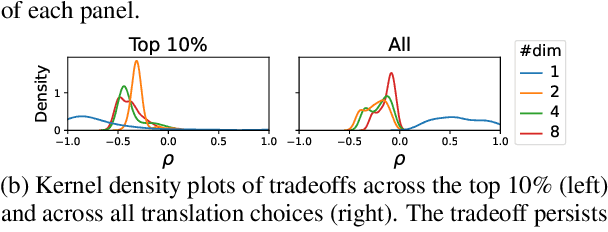

A good translation should be faithful to the source and should respect the norms of the target language. We address a theoretical puzzle about the relationship between these objectives. On one hand, intuition and some prior work suggest that accuracy and fluency should trade off against each other, and that capturing every detail of the source can only be achieved at the cost of fluency. On the other hand, quality assessment researchers often suggest that accuracy and fluency are highly correlated and difficult for human raters to distinguish (Callison-Burch et al. 2007). We show that the tension between these views is an instance of Simpson's paradox, and that accuracy and fluency are positively correlated at the level of the corpus but trade off at the level of individual source segments. We further suggest that the relationship between accuracy and fluency is best evaluated at the segment (or sentence) level, and that the trade off between these dimensions has implications both for assessing translation quality and developing improved MT systems.
Human Goal Recognition as Bayesian Inference: Investigating the Impact of Actions, Timing, and Goal Solvability
Feb 16, 2024



Goal recognition is a fundamental cognitive process that enables individuals to infer intentions based on available cues. Current goal recognition algorithms often take only observed actions as input, but here we use a Bayesian framework to explore the role of actions, timing, and goal solvability in goal recognition. We analyze human responses to goal-recognition problems in the Sokoban domain, and find that actions are assigned most importance, but that timing and solvability also influence goal recognition in some cases, especially when actions are uninformative. We leverage these findings to develop a goal recognition model that matches human inferences more closely than do existing algorithms. Our work provides new insight into human goal recognition and takes a step towards more human-like AI models.
Predicting Human Translation Difficulty with Neural Machine Translation
Dec 19, 2023Human translators linger on some words and phrases more than others, and predicting this variation is a step towards explaining the underlying cognitive processes. Using data from the CRITT Translation Process Research Database, we evaluate the extent to which surprisal and attentional features derived from a Neural Machine Translation (NMT) model account for reading and production times of human translators. We find that surprisal and attention are complementary predictors of translation difficulty, and that surprisal derived from a NMT model is the single most successful predictor of production duration. Our analyses draw on data from hundreds of translators operating across 13 language pairs, and represent the most comprehensive investigation of human translation difficulty to date.
Inductive reasoning in humans and large language models
Jun 11, 2023The impressive recent performance of large language models has led many to wonder to what extent they can serve as models of general intelligence or are similar to human cognition. We address this issue by applying GPT-3 and GPT-4 to a classic problem in human inductive reasoning known as property induction. Over two experiments, we elicit human judgments on a range of property induction tasks spanning multiple domains. Although GPT-3 struggles to capture many aspects of human behaviour, GPT-4 is much more successful: for the most part, its performance qualitatively matches that of humans, and the only notable exception is its failure to capture the phenomenon of premise non-monotonicity. Overall, this work not only demonstrates that property induction is an interesting skill on which to compare human and machine intelligence, but also provides two large datasets that can serve as suitable benchmarks for future work in this vein.
Semantic categories of artifacts and animals reflect efficient coding
May 11, 2019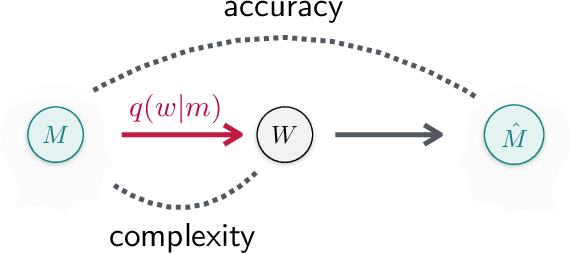
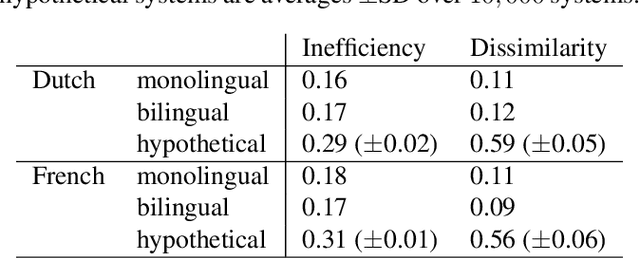
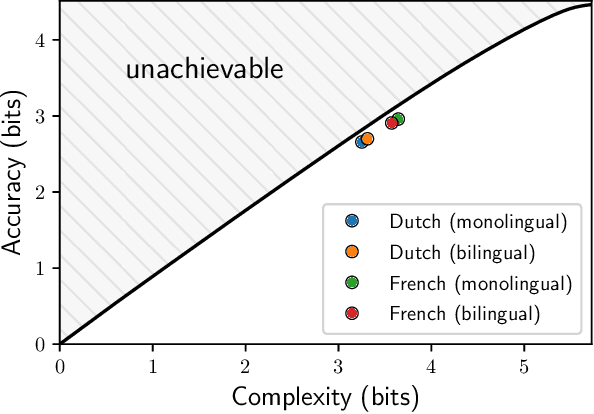
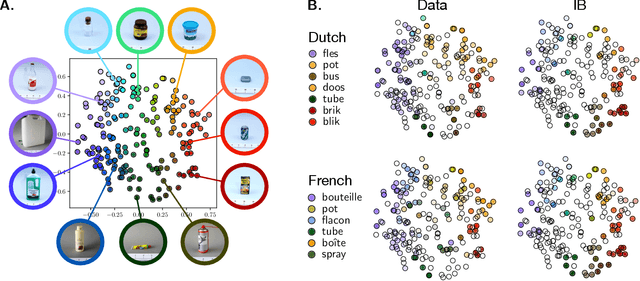
It has been argued that semantic categories across languages reflect pressure for efficient communication. Recently, this idea has been cast in terms of a general information-theoretic principle of efficiency, the Information Bottleneck (IB) principle, and it has been shown that this principle accounts for the emergence and evolution of named color categories across languages, including soft structure and patterns of inconsistent naming. However, it is not yet clear to what extent this account generalizes to semantic domains other than color. Here we show that it generalizes to two qualitatively different semantic domains: names for containers, and for animals. First, we show that container naming in Dutch and French is near-optimal in the IB sense, and that IB broadly accounts for soft categories and inconsistent naming patterns in both languages. Second, we show that a hierarchy of animal categories derived from IB captures cross-linguistic tendencies in the growth of animal taxonomies. Taken together, these findings suggest that fundamental information-theoretic principles of efficient coding may shape semantic categories across languages and across domains.
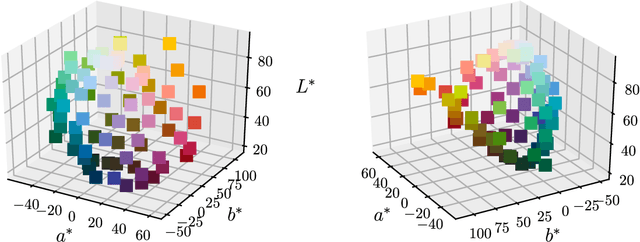
Efficient human-like semantic representations via the Information Bottleneck principle
Aug 09, 2018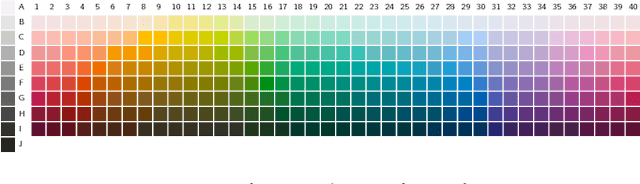

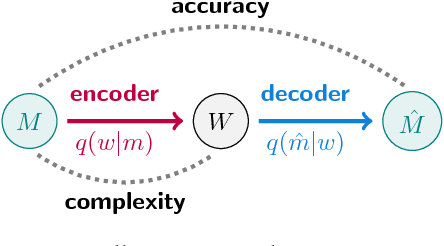
Maintaining efficient semantic representations of the environment is a major challenge both for humans and for machines. While human languages represent useful solutions to this problem, it is not yet clear what computational principle could give rise to similar solutions in machines. In this work we propose an answer to this open question. We suggest that languages compress percepts into words by optimizing the Information Bottleneck (IB) tradeoff between the complexity and accuracy of their lexicons. We present empirical evidence that this principle may give rise to human-like semantic representations, by exploring how human languages categorize colors. We show that color naming systems across languages are near-optimal in the IB sense, and that these natural systems are similar to artificial IB color naming systems with a single tradeoff parameter controlling the cross-language variability. In addition, the IB systems evolve through a sequence of structural phase transitions, demonstrating a possible adaptation process. This work thus identifies a computational principle that characterizes human semantic systems, and that could usefully inform semantic representations in machines.
Color naming reflects both perceptual structure and communicative need
Aug 03, 2018
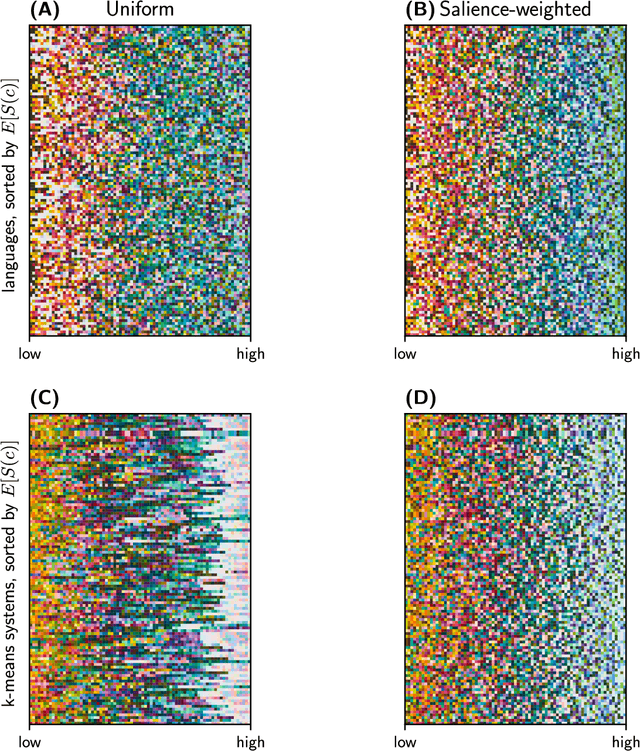
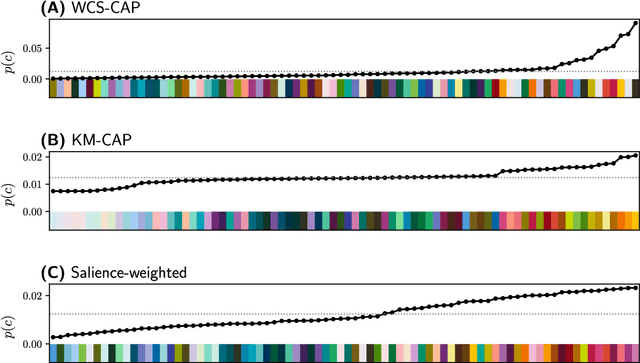
Gibson et al. (2017) argued that color naming is shaped by patterns of communicative need. In support of this claim, they showed that color naming systems across languages support more precise communication about warm colors than cool colors, and that the objects we talk about tend to be warm-colored rather than cool-colored. Here, we present new analyses that alter this picture. We show that greater communicative precision for warm than for cool colors, and greater communicative need, may both be explained by perceptual structure. However, using an information-theoretic analysis, we also show that color naming across languages bears signs of communicative need beyond what would be predicted by perceptual structure alone. We conclude that color naming is shaped both by perceptual structure, as has traditionally been argued, and by patterns of communicative need, as argued by Gibson et al. - although for reasons other than those they advanced.
Structured Priors for Structure Learning
Jun 27, 2012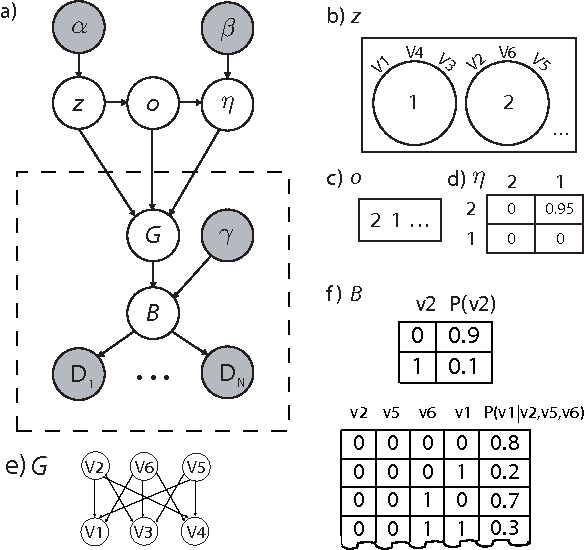
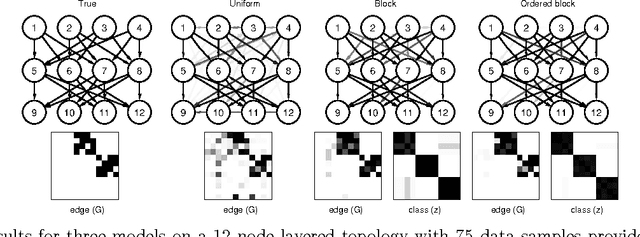
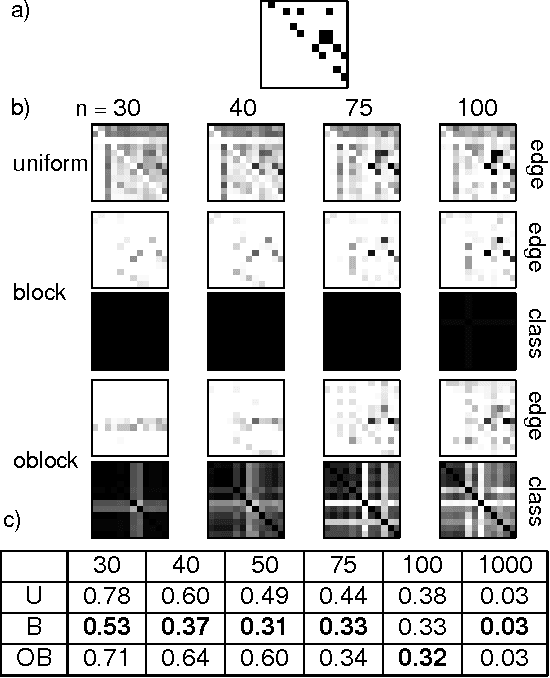
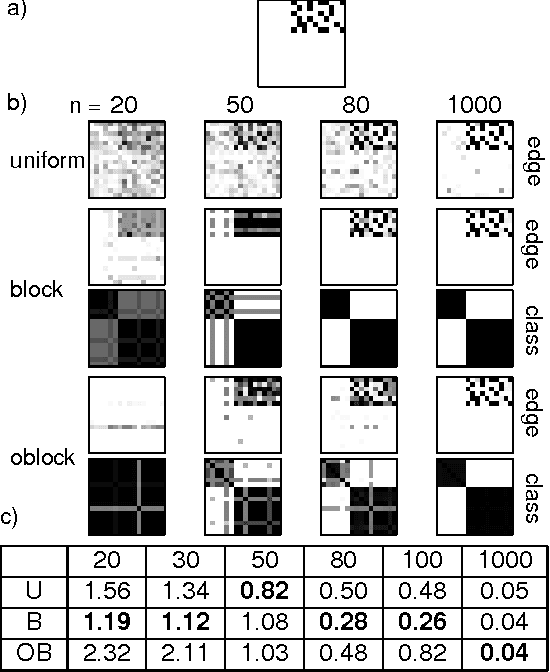
Traditional approaches to Bayes net structure learning typically assume little regularity in graph structure other than sparseness. However, in many cases, we expect more systematicity: variables in real-world systems often group into classes that predict the kinds of probabilistic dependencies they participate in. Here we capture this form of prior knowledge in a hierarchical Bayesian framework, and exploit it to enable structure learning and type discovery from small datasets. Specifically, we present a nonparametric generative model for directed acyclic graphs as a prior for Bayes net structure learning. Our model assumes that variables come in one or more classes and that the prior probability of an edge existing between two variables is a function only of their classes. We derive an MCMC algorithm for simultaneous inference of the number of classes, the class assignments of variables, and the Bayes net structure over variables. For several realistic, sparse datasets, we show that the bias towards systematicity of connections provided by our model yields more accurate learned networks than a traditional, uniform prior approach, and that the classes found by our model are appropriate.