 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Model for Multimodal Document Quality Assessment
Paper and Code



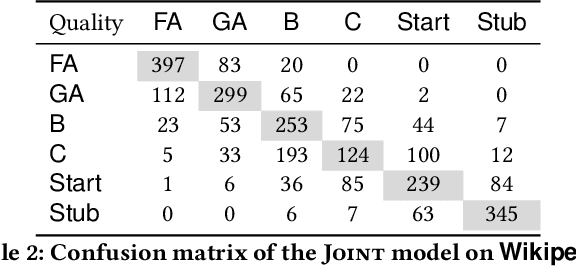
The quality of a document is affected by various factors, including grammaticality, readability, stylistics, and expertise depth, making the task of document quality assessment a complex one. In this paper, we explore this task in the context of assessing the quality of Wikipedia articles and academic papers. Observing that the visual rendering of a document can capture implicit quality indicators that are not present in the document text --- such as images, font choices, and visual layout --- we propose a joint model that combines the text content with a visual rendering of the document for document quality assessment. Experimental results over two datasets reveal that textual and visual features are complementary, achieving state-of-the-art results.